1注册中国大学MOOC
 .
.
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
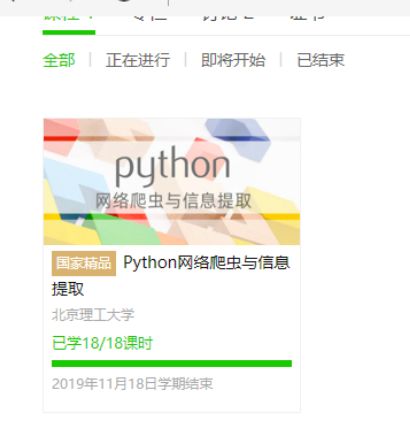
3.学习完成第0周至第4周的课程内容,并完成各周作业
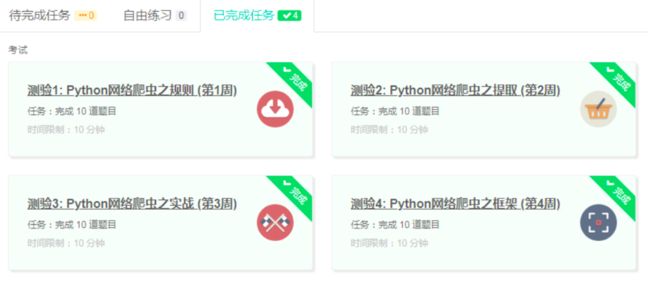
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获
第一周老师主要让我们了解Requests库的入门,比如Requests库的安装,Requests库的7种主要方法,其中主要讲了Requests库的get()方法,还有要理解Requests库的异常等等。还让我们了解了什么是网络爬虫,让我们对爬虫有进一步的了解。介绍了Robots协议,为了让我们更明白,还举了京东的例子,更加清晰易懂。在第三单元中举了Requests库中爬虫的五个例子,我也跟着老师也操作起来了,以爬虫的视角看待网络内容。
第二周安装Beautiful Soup库安装还是正常的pip安装,然后就是了解Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag NavigableString BeautifulSoup Comment
3种遍历方式:上行遍历,下行遍历,平行遍历。bs4库还有三种信心标记的方法:XML:标签:
第三周正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
第四周每一个网页都有一个对应的url,而url在页面上又有很多指向其他页面的url,这种url之间相互的指向关系就形成一个网,这就是互联网。通常,我们使用浏览器访问互联网,获取需要的、感兴趣的信息,但这种方式效率低下。对于批量数据的获取,网络爬虫有着天生的优势。
网络爬虫是一段自动抓取互联网信息的程序,它模仿浏览器访问互联网的过程,下载网页,然后解析得到需要的数据。此外,爬虫可以从一个url出发,访问它关联的所有url,并且从每个页面上提取我们所需要的、有价值的数据。
Python是编写爬虫程序的常用工具。Python中有多个模块使得爬虫编写非常简单,常用的模块有:urllib、requests、re、bs4、Selenium等。