本文写文章日期为2018.03.13
因为买电脑自带了win10系统,自己就没有重新安装win10,而是在原win10环境下分割一个磁盘来安装ubuntu16.04,本人电脑GPU为Gtx 1080Ti显卡,要注意的是显示器连接线是直接与Gtx 1080Ti显卡连接,而不是连接主板上的接口!电脑配置见下图。我的硬盘是双硬盘一个256G的SSD固态硬盘,一个2T的HDD机械硬盘,现在win10是安装在SSD上,我准备把ubuntu也安装在SSD上。
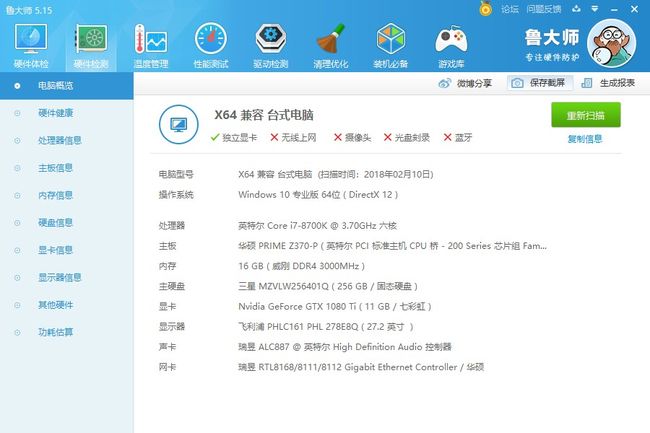
以前用的电脑都是BIOS+MBR,以前装的双系统基本都Win7和ubuntu16.04,而这次是在win10下且是在UEFI + GPT条件下安装ubuntu16.04,所以在动手之前google了很多最新教程,避免了很多坑,感谢那些善良的人!
一、安装前准备
1.安装EasyUEFI
通常使用BIOS+MBR构架的双系统需要使用EasyBCD软件来添加启动项,使用UEFI需要EasyUEFI。在win10下先安装EasyUEFI以便于以后在win10下管理启动项以及删除ubuntu系统。
2.制作Ubuntu 16.04LTS启动盘
- 下载Ubuntu 16.04LTS于Ubuntu 16.04LTS中国官网或者Ubuntu 16.04LTS官网
- 我是用ubuntu官方推荐的Rufus来制作启动盘,其方法见How to create a bootable USB stick on Windows,使用该工具的时候,有三种模式可选,到底是用那种模式取决于电脑的配置,可以百度一下电脑主板是不是UEFI以及硬盘分区是MBR还是GPT:如何查看电脑硬盘是gpt分区还是MBR分区 + 如何查看主板是UEFI启动以及是否支持UEFI模式,确实不清楚的就选第一项。有资料说直接解压到空的U盘也能行。总之很多方式都能做成系统启动盘。
- 但是也有用UltraISO软碟通来制作的,但是我制作后安装的时候失败了,然后改用Rufus,文件系统用的是Ntfs,安装时还是失败了。这两种失败情况都是ACPI error,后来我发现是U盘太旧了的原因,虽然这个u盘也有16G,于是我用另一个较新的16G的u盘用Rufus制作启动盘,文件系统用的默认的FAT32,分区方案和目标系统类型选择自己对应的即可,见下图。
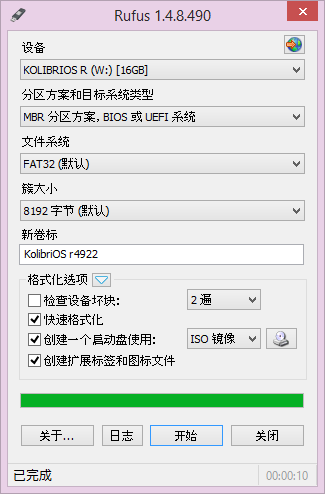
3.禁用UEFI安全启动、关闭快速启动
- 禁用UEFI安全启动的方法见配置深度学习主机与环境(TensorFlow+1080Ti):(二) Win10&Ubuntu双系统与显卡驱动安装。
- 关闭快速启动的方法关闭win10的快速启动,如果Win10电源管理中没有快速启动选项,那么请按照Win10电源管理中没有快速启动选项中的的方法进行设置即可,因为我就是这种情况。
4.为Ubuntu系统分配硬盘空间
- 如果需要,用DiskGenius或者分区助手对各个硬盘大小进行调整
- “鼠标右键计算机—>管理—->磁盘管理—->选中盘符右键—->压缩卷 ”
压缩出最少60G(空间太小,等会分区的时候很难分配,而且会运行慢)的空间出来,不要分配盘符,直接让其处于空闲或未分配状态即可。这个未分配的空间就是我们将来的ubuntu系统的安装使用空间。我压缩了130g固态硬盘空间用于安装ubuntu。
二、安装ubuntu 16.04
- 安装方法主要见配置深度学习主机与环境(TensorFlow+1080Ti):(二) Win10&Ubuntu双系统与显卡驱动安装,还可参考 Win10下UEFI环境安装Ubuntu 16.04双系统教程
- 我准备的分区情况是:
swap交换空间:8G
efi系统分区 :512M
挂载“/” :30G
挂载“/usr” :35G
挂载“/home”:51G
因为我参考了下面:
1.swap交换空间,相当于Win中的虚拟内存,通常需要划分对应物理内存2倍的空间,考虑到深度学习主机内存一般都是32G、64G或者128G,所以选择忽略不划分,之后如有需要还可以在系统设置中添加swap部分。实际上我划分了8G。
2.EFI系统分区,选择分区类型为“逻辑分区”,分区位置为“空间起始位置”。分配大小为512M,足矣。
3.挂载“/”,类型为EXT4日志文件系统,选择“逻辑分区”和“空间起始位置”。根目录将挂载除了“/home”和“/usr”之外的其他目录,分配30G。
4.挂载“/usr”,类型为EXT4日志文件系统,选择“逻辑分区”和“空间起始位置”。“/usr”为Linux存放软件的地方,分配40G。
5.挂载“/home”,类型为EXT4日志文件系统,选择“逻辑分区”和“空间起始位置”。剩余50G左右空间全部分配给“/home”。
- 实际分区情况为:

其中,磁盘0是2T机械硬盘,磁盘1是256G固态硬盘,固态硬盘用于安装win 10系统和ubuntu 16.04系统,磁盘1分区从左到右分别为:
100MB:win 10系统启动分区
100GB的C盘:win 10系统
7.51GB的H盘:固态硬盘中的非系统分区,用于存储常用文件
488MB: ubuntu 16.04系统中的efi系统分区
3.81GB:ubuntu 16.04系统中的swap交换空间
27.94GB:ubuntu 16.04系统中的挂载“/”
42.84GB:ubuntu 16.04系统中的挂载“/usr”
55.79GB:ubuntu 16.04系统中的挂载“/home”
- 如果安装ubuntu时出现ACPI error,可参考win10安装ubuntu-GNOME双系统踩坑综合
三、安装显卡驱动
- 因为此时我的ubuntu还不能连网,所以没办法到用系统自带的软件更新里去安装,所以只能自己在win10里下载好驱动,再在ubuntu里安装。
- 安装方法见Ubuntu 16.04 安装GTX1080Ti驱动、Ubuntu 16.04安装NVIDIA驱动
四、台式机ubuntu无线上网问题
想在台式机ubuntu16.04和win10上都用一个无线网卡来上网,发现很多网卡都不能在ubuntu中上网,即使可以也只能需要复杂的安装网卡驱动步骤,但是我也发现了在ubuntu系统中免驱可以即插即用且在windows中也可以免驱连网的两种网卡分别是:
- RT5572无线网卡,2.4GHz和5GHz双频,传输速率为300Mbps,因为速率比较快,所以我用的是这个网卡。
- RT3070(L)白或者 RT3070(L)黑或者RT3070(L)-Hi-Link,频段只为2.4GHz,传输速率为150Mbps
五、卸载 Ubuntu
- 方法见Win10+Ubuntu16.04双系统(UEFI+GPT, SDD+HDD)解决方案
六、安装CUDA 9.1 和Cudnn 7.1.1
在安装完CUDA 9.1 和Cudnn 7.1.1之后发现,tensorflow最新版本 1.7.0不支持CUDA 9.1 和Cudnn 7.1.1,而是支持CUDA 9.0 和Cudnn 7.0,见tensorflow官网安装说明:Installing TensorFlow 或 Installing TensorFlow on Ubuntu,否则会出现如下错误:
(tensordai) mengzhuo@ubuntu:~$ python
Python 3.6.2 |Continuum Analytics, Inc.| (default, Jul 20 2017, 13:51:32)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux
Type "help", "copyright", "credits" or "license" for more information.
输入命令:import tensorflow as tf
出现错误:ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
因此,大家还是安装CUDA 9.0 和Cudnn 7.0吧,安装方法跟下面的方法一样。
CUDA 9.0下载地址为:CUDA Toolkit 9.0,所以大家可直接跳过前3步,直接看第4步安装CUDA 9.0和CUDNN 7.0.5的方法
1.安装CUDA 9.1
参考教程:Ubuntu 16.04 上安装 CUDA 9.0 详细教程、ubuntu16.04安装cuda9——简明教程
官方教程膜拜上:官方教程
-
下载CUDA Toolkit 9.1 Download
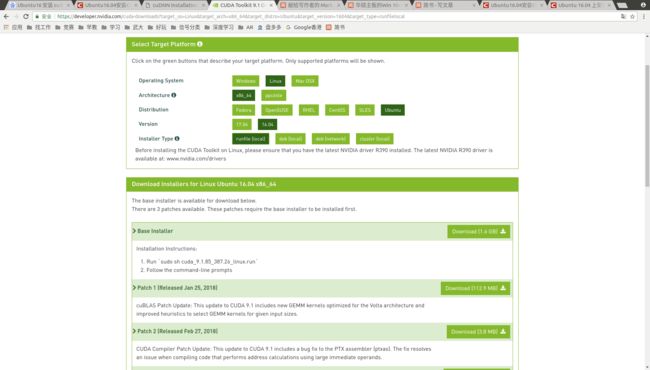
安装的主要方法见:Ubuntu16.04安装CUDA9.1、cuDNN7详细教程,基本同官方教程一样,我和这个教程有一点不一样就是在设置环境变量时,因为我也安装的是CUDA 9.1,所以在终端中输入
sudo gedit /etc/profile
在打开的文件末尾,添加以下两行。
64位系统:
export PATH=/usr/local/cuda-9.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.1/lib64:$LD_LIBRARY_PATH
这里的文件目录是cuda-9.1不是cuda-9.0。
2.安装Cudnn 7.1
- Cudnn 7.1的安装是按照Ubuntu16.04安装CUDA9.1、cuDNN7详细教程中以tgz文件的形式安装的。这个教程也是按照cudnn7.1.1安装官方教程来的。下载cudnn需要注册,我是在cuDNN Download中下载的,下载的是cuDNN v7.1.1 Library for Linux,见下图。
总结起来实际上以tgz文件的形式安装cuDNN只需要4条命令就能安装成功,在cuDNN7的tgz安装文件所在的文件夹内:右键--->在终端中打开--->然后在终端内输入以下4命令即可: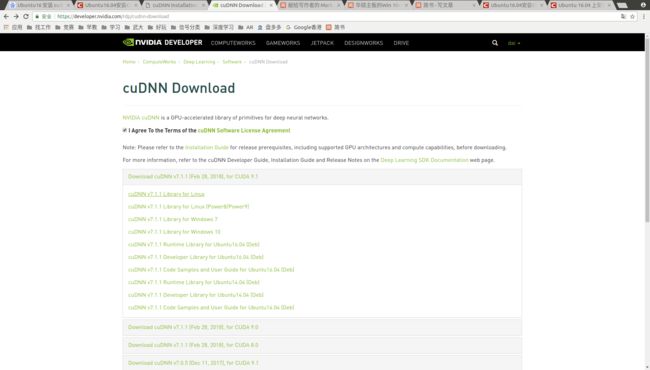
tar -xzvf cudnn-9.1-linux-x64-v7.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
- 因为是以tgz文件的形式安装的cudnn所以没办法按照官方教程中一样来验证cudnn是否安装成功,不过我到各个文件目录看了下,确认应该是安装成功了。
3.卸载 CUDNN 7.1.1 和CUDA 9.1,
3.1 卸载CUDA 9.1的方法见:
- 以runfiles形式安装CUDA9.1的官方卸载方法:
sudo /usr/local/cuda-9.1/bin/uninstall_cuda_9.1.pl
- ubuntu16.04 下 卸载CUDA9.1
3.2 卸载CUDNN 7.1.1 的方法:
因为安装CUDNN,实际上只是把几文件复制到CUDA的安装目录下,所以卸载CUDNN只需要把CUDA的安装目录"/usr/local/cuda-9.1"一起删除就可以了:
cd /usr/local/
sudo rm -r cuda-9.1
如果曾经验证过CUDA就会在/home/用户名 下产生文件夹“NVIDIA_CUDA-9.1_Samples”,可以把它一起删除:
cd /home/mengzhuo
sudo rm -r NVIDIA_CUDA-9.1_Samples
注意:我用官方卸载方法卸载CUDA 9.1后再用下面的"4.4.1 方法一"安装CUDA 9.0后发现:
系统分辨率变成没装驱动一样,并且在ubuntu登录界面出现循环登录,导致不能以图形方式进入ubuntu。
我猜测的原因:卸载CUDA 9.1时估计连带着驱动的一些包被卸载了。
我解决的办法是:在登录界面按Alt+Ctrl+F1进入字符界面,然后卸载我刚才安装的CUDA 9.0,在没有卸载驱动的情况下用驱动的.run安装包,再按照上面讲的安装驱动方法重新安装修复了驱动。然后分辨率变正常,循环登录现象消失。最后我进入ubuntu系统后用了
4.安装CUDA 9.0
CUDA 9.0下载地址为:CUDA Toolkit 9.0
参考教程:Ubuntu 16.04 上安装 CUDA 9.0 详细教程、ubuntu16.04安装cuda9——简明教程
官方教程膜拜上:安装CUDA9.0官方教程
安装方法同上面安装CUDA 9.1一样,其主要方法见:Ubuntu16.04安装CUDA9.1、cuDNN7详细教程,基本同官方教程一样,具体方法如下:
4.1 检查自己的计算机是否具备CUDA安装条件
检查方法见:Ubuntu16.04安装CUDA9.1、cuDNN7详细教程
4.2 安装NVIIDA驱动。
CUDA提供两种安装方式:package manager安装和runfile安装。因为CUDA安装文件将近1.6G,所以 这里我选择runfile安装,采用runfile安装,CUDA自带的驱动可能无法定位内核信息,所以要先安装NVIIDA驱动。我前面已经安装了驱动,所以这步已经免了。
4.3 下载CUDA 9.0的runfile安装文件
下载地址:CUDA Toolkit 9.0
4.4 开始安装CUDA 9.0
4.4.1 方法一:网上大部分的方法都是这种,太复杂,所以可直接看4.4.2的方法二
- 重启系统,在登录界面时按Ctrl+Alt+F1进入字符终端界面,登录成功后,关闭图形化界面
sudo service lightdm stop
- 以cd命令进入CUDA 9.0的.run安装文件所在文件夹内,比如我的是:
cd /home/mengzhuo/ # mengzhuo是我的系统用户名
- 找到下载文件的路径,键入下面的命令安装:
sudo sh cuda_9.0.176_384.81_linux.run
- 单击回车,直到提示“是否为NVIDIA安装驱动?” 一定要选择否,因为已经安装好驱动程序,其他都是默认。
最后,你会看到cuda驱动、sample、tookit已经安装成功,但是缺少一些库。
- 添加这些库:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
- 重新启动图形化界面:
sudo service lightdm start
- 同时按住Alt + ctrl +F7,返回到图形化登录界面,输入密码登录。 如果能够成功登录,则表示不会遇到循环登录的问题,基本说明CUDA的安装成功了 .重启电脑,检查Device Node Verification:
ls /dev/nvidia*
- 若结果显示:
/dev/nvidia0 /dev/nvidiactl /dev/nvidia-uvm
或显示出类似的信息,应该有三个(包含一个类似/dev/nvidia-nvm的),则安装成功。 如果显示其他情况,则按照Ubuntu16.04安装CUDA9.1、cuDNN7详细教程中方法进行设置。
- 终端中输入
sudo gedit /etc/profile
- 在打开的文件末尾,添加以下两行:
64位系统:
export PATH=/usr/local/cuda-9.0/bin:PATH export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:LD_LIBRARY_PATH
32位系统:
export PATH=/usr/local/cuda-9.0/bin:PATH export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib:LD_LIBRARY_PATH
- 保存文件,并重启。因为source /etc/profile是临时生效,重启电脑才是永久生效。重启电脑,检查上述的环境变量是否设置成功。
4.4.2 方法二:
因为我们在安装cuda时并不需要安装驱动,所以不用按Ctrl+Alt+F1进入字符终端,也不用关闭图化界面。同时,在方法一中,在验证是否安装成功时,make也太复杂了,需要花20+分钟,其实只需要make一个文件就可以,这样只需要几秒就可验证是否安装正确。具体方法如下:
- 先安装 安装cuda所需的依赖库:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
- 输入以下命令:
cd /home/mengzhuo/ # mengzhuo是我的系统用户名,该文件夹下存在CUDA9.0的.run安装文件
sudo sh cuda_9.0.176_384.81_linux.run
单击回车,直到提示“是否为NVIDIA安装驱动?” 一定要选择no,因为已经安装好驱动程序,其他都是选择yes。
- 添加环境变量:
sudo gedit /etc/profile
在打开的文件末尾,添加以下两行:
64位系统:
export PATH=/usr/local/cuda-9.0/bin:PATH export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:LD_LIBRARY_PATH
- 保存文件,并重启。因为source /etc/profile是临时生效,重启电脑才是永久生效。重启电脑,检查上述的环境变量是否设置成功。
4.5 验证CUDA 9.0是否安装成功
4.5.1 方法一:网上大部分的方法都是这种,太复杂太花时间,所以可直接看4.5.2的方法二
- 验证CUDA Toolkit:
nvcc -V
- 最后,我们需要尝试编译cuda提供的例子,看cuda能否正常运行,打开终端输入:
cd /home/user_name/NVIDIA_CUDA-9.1_Samples
make
系统就会自动进入到编译过程,整个过程大概需要十几到二十分钟,请耐心等待。如果出现错误的话,系统会立即报错停止。 如果编译成功,最后会显示Finished building CUDA samples,如下图所示。
运行编译生成的二进制文件。 编译后的二进制文件默认存放在NVIDIA_CUDA-9.1_Samples/bin中。接着在终端中输入 :
cd bin/x86_64/linux/release
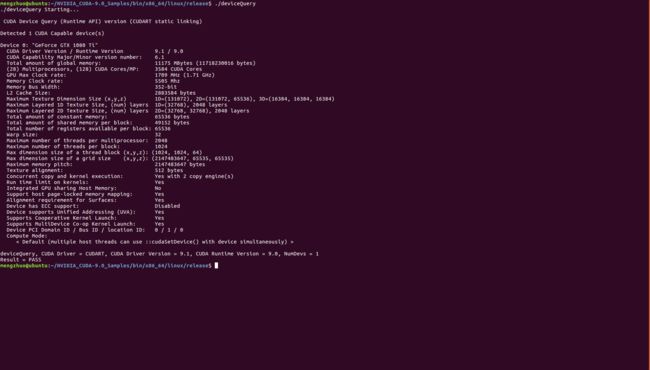
./deviceQuery
- 结果如下图所示:看到类似如下图片中的显示,则代表CUDA安装且配置成功,其中 Result = PASS代表成功,若失败 Result = FAIL .
- 最后再检查一下系统和CUDA-Capable device的连接情况
终端输入 :
./bandwidthTest
看到类似如下图片中的显示,则代表成功
4.5.2方法二:
- 验证CUDA Toolkit:
nvcc -V
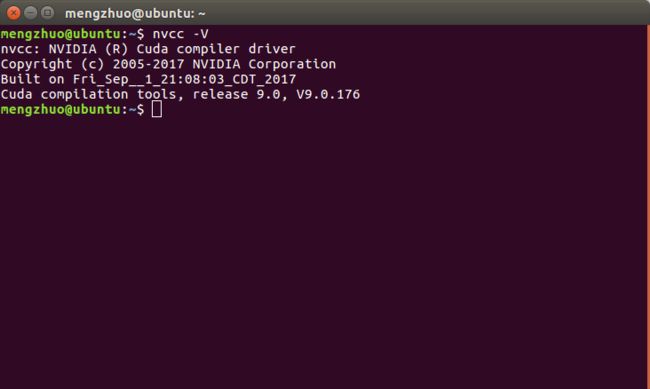
- 我们需要尝试编译cuda提供的例子,看cuda能否正常运行,这里我们不用像方法一一样make所有samples,而只需make一个sample就可以了,这样可以使时间从20多分钟减少到几秒钟,打开终端输入:
cd /home/mengzhuo/NVIDIA_CUDA-9.0_Samples/1_Utilities # 进入NVIDIA_CUDA-9.0_Samples中 deviceQuery所在文件夹,mengzhuo是我自己的username
make
cd /home/mengzhuo/NVIDIA_CUDA-9.0_Samples/bin/x86_64/linux/release
./deviceQuery
-
结果如下图所示:看到类似如下图片中的显示,则代表CUDA安装且配置成功,其中 Result = PASS代表成功,若失败 Result = FAIL 。
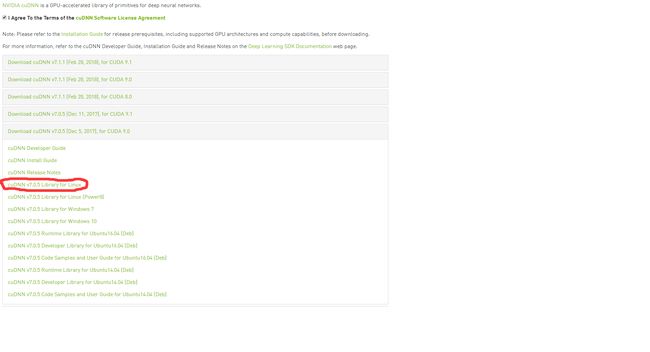
5.安装CUDNN 7.0.5
- Cudnn 7.0.5的安装是按照Ubuntu16.04安装CUDA9.1、cuDNN7详细教程中以tgz文件的形式安装的。这个教程也是按照cudnn7.0.5安装官方教程来的。下载cudnn需要注册,我是在cuDNN Download中下载的,下载的是cuDNN v7.0.5 Library for Linux
,见下图。
实际上cuDNN的安装只是将其安装包解压缩之后,把里面的文件复制到对应的地方即可。故总结起来实际上以tgz文件的形式安装cuDNN只需要4条命令就能安装成功,在cuDNN7的tgz安装文件所在的文件夹内:右键--->在终端中打开--->然后在终端内输入以下4命令即可:
tar -xzvf cudnn-9.0-linux-x64-v7.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
注意:上面的第三条命令官方方法是:sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/ ,但是我在lib64文件夹下并没有看到名为libcudnn的文件夹,所以应该还是用我上面的第三条命令。
为防止破坏软链接,还有必要再输入以下4条命令,反正我按照上面的官方安装方法后测试时是提示我软链接被破坏了:
cd /usr/local/cuda-9.0/lib64
sudo ln -s libcudnn.so.7.0.5 libcudnn.so.7
sudo ln -s libcudnn.so.7 libcudnn.so
sudo ldconfig -v #改了lib、lib64、 ld.so.conf都要重新运行一下ldconfig,不然系统找不到动态链接库
因为是以tgz文件的形式安装的cudnn所以没办法按照官方教程中一样来验证cudnn是否安装成功,不过我到各个文件目录看了下,确认应该是安装成功了。
七、安装Anaconda 3.5.1及其中自带的python 3.6
虽然我的ubuntu 16系统自带的python是2.7.12,但是Anaconda不仅能够进行包管理,还能进行环境管理,所以用它来进行创建虚拟环境并管理。去Anaconda的官方下载地址或清华anaconda镜像下载对应python版本的Anaconda安装文件。我这里下载的是python3.6的版本:本次使用的是Anaconda3-5.1.0-Linux-x86_64.sh。
- 主要安装方法见Ubuntu 16.04 安装Anaconda3。另外,也参考了Ubuntu 安装 Anaconda3 详细步骤。
八、安装pycharm
方法见Ubuntu 16.04 安装 PyCharm
如果在应用程序中找不到pycharm启动项,可用如下方法:
打开Pycharm--->Tools--->Creat Desktop Entry...--->Ok
完全不必用这种方法:在ubuntu16.4中为pycharm创建桌面快捷启动方式。这种方法不仅复杂,而且我用这种方法后发现程序图标并没有被加载,所以图标变发了一个问号图片。
九、利用pycharm创建虚拟环境,并在虚拟环境内安装tensorflow、keras等深度学习框架
如果不想利用pycharm创建虚拟环境,并在虚拟环境内安装tensorflow、keras等深度学习框架,而是非要自己在终端手机输入命令来进行,那么可直接跳过本节看下一节"十、在Anaconda创建的虚拟环境内安装tensorflow",本节和下一节方法是等效的,只是本节方法更简单、更直观而已。
-
打开pycharm--->Files--->New Project--->Pure python
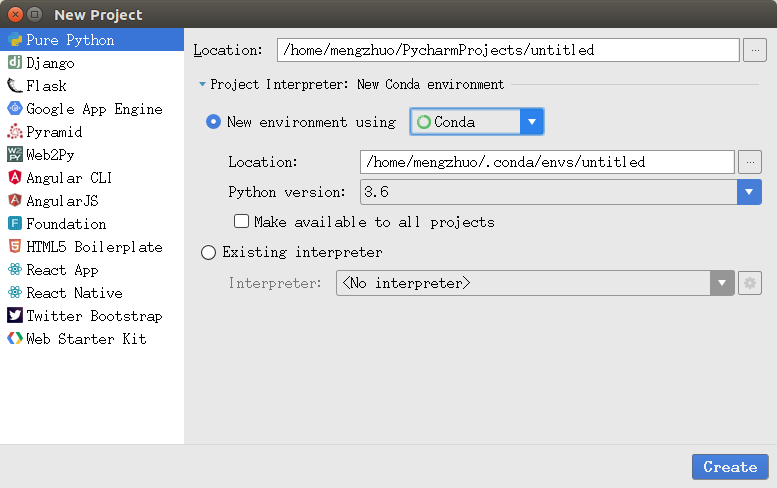 1.png
1.png 在New environment using中可选择“Conda”或"Virtualenv"来创建虚拟环境,在Location中把“untitled”改成自定义的虚拟环境名字,Python version中可自己选择想要的版本,这里我选择的是用"Virtualenv"来创建虚拟环境,因为我用“Conda”来创建虚拟环境后发现安装包速率很慢,尽管我在pycharm中已经更换了国内的pip源。
-
Files--->Settings--->Project Interpreter

可以点击上图中右上角的齿轮图标,来更换项目解释器。
-
点击右上角“+”,可以看到“Availabe Packages”,并可以搜索安装想要的包。如果前是选择“Conda”来创建虚拟环境,这里就是一片空白,什么都没有。
-
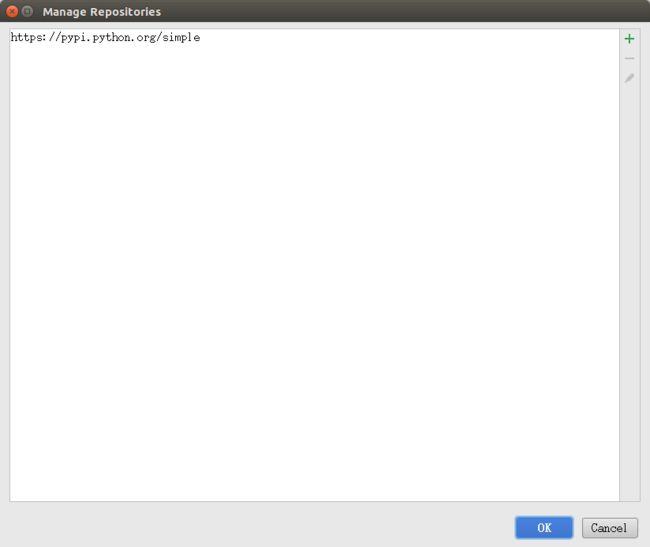
更换国内pip源:点击上图中的“Manage Repositories”,然后输入源地址,如下图所示。
十、在Anaconda创建的虚拟环境内安装tensorflow
本节和上一节方法是等效的,只是上一节方法更简单、更直观,如果你已经按照"九、利用pycharm创建虚拟环境,并在虚拟环境内安装tensorflow、keras等深度学习框架"中的方法进行,可跳过本节。
- Ubuntu16.04+Anaconda安装+换源+环境创建+tensorflow安装(3)
- Ubuntu16.04下安装tensorflow(Anaconda3+pycharm+tensorflow+CPU)
- Ubuntu16.04安装anaconda3+tensorflow
- Ubuntu下使用pycharm add TensorFlow
- 解决每次使用conda创建的虚拟环境都需要激活的问题:如何在Ubuntu下安装Anaconda及搭建环境安装TensorFlow深度学习框架
- 在虚拟环境中安装tensoflow时不要用conda命令安装,因为我看到conda安装包里面的tensorflow gpu版本已经是4个月前了,不是最新的,所以还是用pip3命令安装吧。
1.利用conda创建虚拟环境
conda create -n tensordai python=3.6
tensordai是虚拟环境的名字。
2.在虚拟环境内安装tensorflow
2.1 方法一:见Ubuntu16.04安装anaconda3+tensorflow
注意:这种方法我没成功,原因是网络老是断掉,所以我更换了国内的pip源,再进行了方法二来安装tensorflow 1.7.0. 所以大家还是直接看方法二吧。
下面是方法1的内容:
- 根据tensorflow的github官方网站可知python 3的安装命令如下:
GPU版:pip install tf-nightly-gpu
CPU版:pip install tf-nightly
- 或者可以先下载好对应版本的安装文件:
Linux CPU-only: Python 2 (build history) / Python 3.4 (build history) / Python 3.5 (build history) / Python 3.6 (build history)
Linux GPU: Python 2 (build history) / Python 3.4 (build history) / Python 3.5 (build history) / Python 3.6 (build history)
我点击python3.6版本 Python 3.6 (build history)
中的“build history”,然后下载这个文件“tf_nightly_gpu-1.7.0.dev20180222-cp36-cp36m-manylinux1_x86_64.whl”,然后必须把它重命名为“tensorflow-1.7.0-py3-none-linux_x86_64.whl”,否则会出现错误“tf_nightly_gpu-1.7.0.dev20180222-cp36-cp36m-linux_x86_64.whl is not a supported wheel on this platform.”
再利用下面的命令进行安装:
source activate tensordai #激活虚拟环境
cd ~/Download #我是将下载好的东西放在了Download文件夹里
pip3 install --ignore-installed --upgrade tensorflow-1.7.0-py3-none-linux_x86_64.whl
或者
pip install tf-nightly-gpu
参考:如何在 Ubuntu 16.04 上安装并使用 TensorFlow、ubuntu16.04安装TensorFlow的正确步骤
2.2 方法二:
- 更换pip源,换为国内镜像,方法见:更换pip源到国内镜像、pip换源(更换软件镜像源)
http://pypi.douban.com是豆瓣提供一个镜像源,软件够新,连接速度也很好。所以我选择豆瓣为我的镜像源。
更换源命令为:
cd ~
mkdir .pip
sudo gedit ~/.pip/pip.conf
然后直接编辑文件pip.conf的内容为:
[global]
index-url = http://pypi.douban.com/simple/
[install]
trusted-host = pypi.douban.com
这样就更换pip源成功了。
- 运行命令:
pip install tf-nightly-gpu
3.测试是否安装成功
- 进入python环境:
$ python # 进入python环境
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
sess.run(hello)
a = tf.constant(10)
b = tf.constant(32)
sess.run(a + b)
sess.close()
- 卸载tensorflow
pip uninstall tf-nightly-gpu
本文链接:https://www.jianshu.com/p/a9d458544ca1
参考文献:
win10安装ubuntu-GNOME双系统踩坑综合
感谢:
我的好兄弟张洞明童鞋对本文的热心帮助与耐心指导!