前言
之前一段时间,准备把糗百的项目中json解析的模块中的原生Json解析换成gson解析,工作比较繁杂,坑多,因此为了防止出错,我还对Gson做了一个源码分析。这一篇就是Gson源码分析的总结,同时对Gson内部运用的设计模式也进行了总结,相信了解了它的源码和运行机制,对于使用Gson的使用会更有帮助。

Gson简介
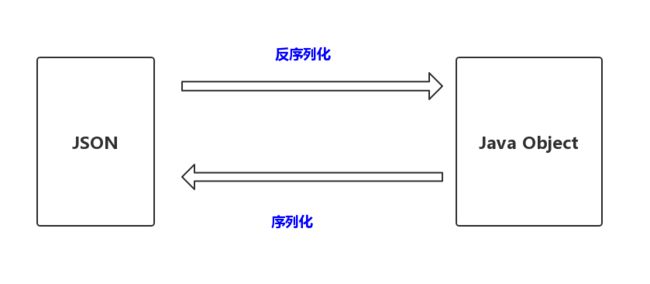
Gson,就是帮助我们完成序列化和反序列化的工作的一个库。
- 日常用法
UserInfo userInfo = getUserInfo();
Gson gson = new Gson();
String jsonStr = gson.toJson(userInfo); // 序列化
UserInfo user = gson.fromJson(jsonStr,UserInfo.class); // 反序列化
实际上我们用的最多的是Gson的反序列化,主要在解析服务器返回的json串。因此,后面的文章也会以Gson中的反序列化的过程为主来分析代码。
在分析之前,我们先做个简单的猜想,要如何实现反序列化的流程的,Gson大体会做一下这三件事:
- 反射创建该类型的对象
- 把json中对应的值赋给对象对应的属性
- 返回该对象。
事实上,Gson想要把json数据反序列化基本都逃不掉这三个步骤,但是这三个步骤就像小品里分三步把大象装进冰箱一样。我们知道最复杂的一步就是把大象装进去,毕竟,开冰箱门或者关冰箱门大家都会的嘛。在Gson中,复杂的就是怎样把json中对应数据放入对应的属性中。而这个问题的答案就是Gson的TypeAdapter。
Gson核心:TypeAdapter
TypeAdapter是Gson的核心,它的意思是类型适配器,而说到适配器,大家都会想到适配器模式,没错,这个TypeAdapter的设计这确实是一个适配器模式,因为Json数据接口和Type的接口两者是无法兼容,因此TypeAdapter就是来实现兼容,把json数据读到Type中,把Type中的数据写入到Json里。
public abstract class TypeAdapter {
// JsonWriter代表Json数据,T则是对应的Type的对象
public abstract void write(JsonWriter out, T value) throws IOException;
// JsonWriter代表Json数据,T则是对应的Type的对象
public abstract T read(JsonReader in) throws IOException;
...
...
...
}
简单而言,TypeAdapter的作用就是针对Type进行适配,保证把json数据读到Type中,或者把Type中的数据写入到Json里
Type和TypeAdapter的对应关系
Gson会为每一种类型创建一个TypeAdapter,同样的,每一个Type都对应唯一一个TypeAdapter
而所有Type(类型),在Gson中又可以分为基本类型和复合类型(非基本类型)
- 基本类型(Integer,String,Uri,Url,Calendar...):这里的基本类型不仅包括Java的基本数据类型,还有很多其他的数据类型
- 复合类型(非基本类型):即除了基本类型之外的类型,往往是我们自定义的一些业务相关的JavaBean,比如User,Article.....等等。
这里的基本类型和复合类型(非基本类型)是笔者定义的词汇,因为这样定义对于读者理解Gson源码和运行机制更有帮助。
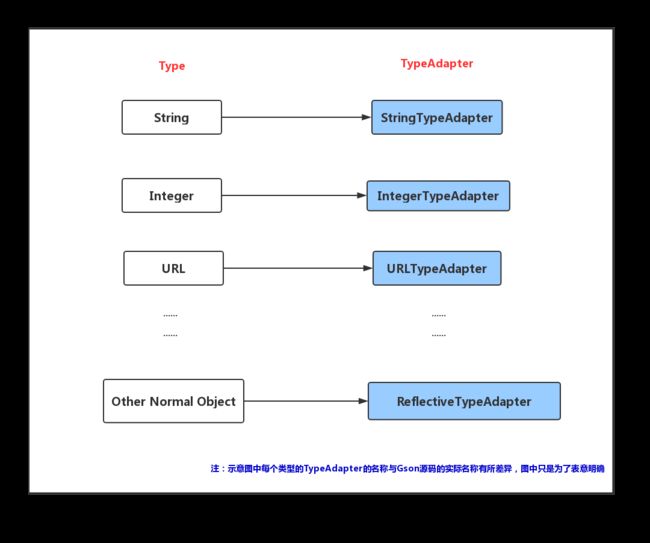
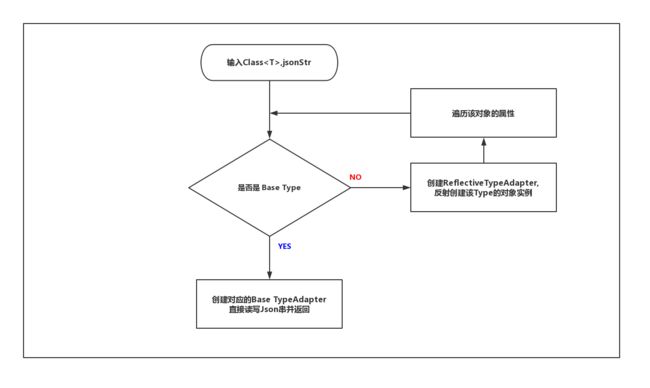
如上图,每一种基本类型都会创建一个TypeAdapter来适配它们,而所有的复合类型(即我们自己定义的各种JavaBean)都会由ReflectiveTypeAdapter来完成适配
TypeAdapter和Gson运行机制
既然讲到了每种Type都有对应的TypeAdapter,那么为什么说TypeAdapter是Gson的核心呢?我们可以看看Gson到底是如何实现Json解析的呢,下图是Gson完成json解析的抽象简化的流程图:
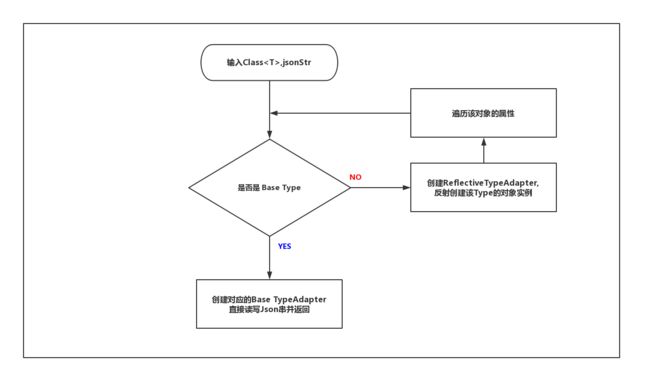
如上图,如果是基本类型,那么对应的TypeAdapter就可以直接读写Json串,如果是复合类型,ReflectiveTypeAdapter会反射创建该类型的对象,并逐个分析其内部的属性的类型,然后重复上述工作。直至所有的属性都是Gson认定的基本类型并完成读写工作。
TypeAdapter源码分析
当类型是复合类型的时候,Gson会创建ReflectiveTypeAdapter,我们可以看看这个Adapter的源码:
// 创建ReflectiveTypeAdapter
new Adapter(constructor, getBoundFields(gson, type, raw));
...
...
/**
* ReflectiveTypeAdapter是ReflectiveTypeAdapterFactory的内部类,其实际的类名就是Adapter
* 本文只是为了区别其他的TypeAdapter而叫它 ReflectiveTypeAdapter
**/
public static final class Adapter extends TypeAdapter {
// 该复合类型的构造器,用于反射创建对象
private final ObjectConstructor constructor;
// 该类型内部的所有的Filed属性,都通过map存储起来
private final Map boundFields;
Adapter(ObjectConstructor constructor, Map boundFields) {
this.constructor = constructor;
this.boundFields = boundFields;
}
//JsonReader是Gson封装的对Json相关的操作类,可以依次读取json数据
// 类似的可以参考Android封装的对XML数据解析的操作类XmlPullParser
@Override public T read(JsonReader in) throws IOException {
if (in.peek() == JsonToken.NULL) {
in.nextNull();
return null;
}
T instance = constructor.construct();
try {
in.beginObject(); // 从“{”开始读取
while (in.hasNext()) {
String name = in.nextName(); //开始逐个读取json串中的key
BoundField field = boundFields.get(name); // 通过key寻找对应的属性
if (field == null || !field.deserialized) {
in.skipValue();
} else {
field.read(in, instance); // 将json串的读取委托给了各个属性
}
}
} catch (IllegalStateException e) {
throw new JsonSyntaxException(e);
} catch (IllegalAccessException e) {
throw new AssertionError(e);
}
in.endObject(); // 到对应的“}”结束
return instance;
}
...
...
}
Gson内部并没有ReflectiveTypeAdapter这个类,它其实际上是ReflectiveTypeAdapterFactory类一个名叫Adapter的内部类,叫它ReflectiveTypeAdapter是为了表意明确。
我们看到,ReflectiveTypeAdapter内部会首先创建该类型的对象,然后遍历该对象内部的所有属性,接着把json传的读去委托给了各个属性。
被委托的BoundField内部又是如何做的呢?BoundField这个类,是对Filed相关操作的封装,我们来看看BoundField是如何创建的,以及内部的工作原理。
// 创建ReflectiveTypeAdapter getBoundFields获取该类型所有的属性
new Adapter(constructor, getBoundFields(gson, type, raw));
...
...
private Map getBoundFields(Gson context, TypeToken type, Class raw) {
// 创建一个Map结构,存放所有的BoundField
Map result = new LinkedHashMap();
if (raw.isInterface()) {
return result;
}
Type declaredType = type.getType();
while (raw != Object.class) { // 如果类型是Object则结束循环
Field[] fields = raw.getDeclaredFields(); // 获取该类型的所有的内部属性
for (Field field : fields) {
boolean serialize = excludeField(field, true);
boolean deserialize = excludeField(field, false);
if (!serialize && !deserialize) {
continue;
}
accessor.makeAccessible(field);
Type fieldType = $Gson$Types.resolve(type.getType(), raw, field.getGenericType());
List fieldNames = getFieldNames(field); // 获取该Filed的名字(Gson通过注解可以给一个属性多个解析名)
BoundField previous = null;
for (int i = 0, size = fieldNames.size(); i < size; ++i) {
String name = fieldNames.get(i);
// 多个解析名,第一作为默认的序列化名称
if (i != 0) serialize = false; // only serialize the default name
// 创建BoundField
BoundField boundField = createBoundField(context, field, name,
TypeToken.get(fieldType), serialize, deserialize);
// 将BoundField放入Map中,获取被替换掉的value(如果有的话)
BoundField replaced = result.put(name, boundField);
// 做好记录
if (previous == null) previous = replaced;
}
if (previous != null) {
// 如果previous != null证明出现了两个相同的Filed name,直接抛出错误
// 注:Gson不允许定义两个相同的名称的属性(父类和子类之间可能出现)
throw new IllegalArgumentException(declaredType
+ " declares multiple JSON fields named " + previous.name);
}
}
type = TypeToken.get($Gson$Types.resolve(type.getType(), raw, raw.getGenericSuperclass()));
raw = type.getRawType(); // 获取父类类型,最终会索引到Object.因为Object是所有对象的父类
}
return result;
}
上面这段代码的主要工作就是,找到该类型内部的所有属性,并尝试逐一封装成BoundField。
// 根据每个Filed创建BoundField(封装Filed读写操作)
private ReflectiveTypeAdapterFactory.BoundField createBoundField(
final Gson context, final Field field, final String name,
final TypeToken fieldType, boolean serialize, boolean deserialize) {
// 是否是原始数据类型 (int,boolean,float...)
final boolean isPrimitive = Primitives.isPrimitive(fieldType.getRawType());
...
...
if (mapped == null){
// Gson尝试获取该类型的TypeAdapter,这个方法我们后面也会继续提到。
mapped = context.getAdapter(fieldType);
}
// final变量,便于内部类使用
final TypeAdapter typeAdapter = mapped;
return new ReflectiveTypeAdapterFactory.BoundField(name, serialize, deserialize) {
...
...
// ReflectiveTypeAdapter委托的Json读操作会调用到这里
@Override void read(JsonReader reader, Object value)
throws IOException, IllegalAccessException {
// 通过该属性的类型对应的TypeAdapter尝试读取json串
//如果是基础类型,则直接读取,
//如果是复合类型则递归之前的流程
Object fieldValue = typeAdapter.read(reader);
if (fieldValue != null || !isPrimitive) {
field.set(value, fieldValue); //更新filed值
}
}
@Override public boolean writeField(Object value) throws IOException, IllegalAccessException {
if (!serialized) return false;
Object fieldValue = field.get(value);
return fieldValue != value; // avoid recursion for example for Throwable.cause
}
};
}
假设该复合类型中所有的属性的类型是String,则属性所对应的TypeAdapter以及其读写方式如下:
public static final TypeAdapter STRING = new TypeAdapter() {
@Override
public String read(JsonReader in) throws IOException {
JsonToken peek = in.peek(); // 获取下一个jsontoken而不消耗它
if (peek == JsonToken.NULL) {
in.nextNull();
return null;
}
/* coerce booleans to strings for backwards compatibility */
if (peek == JsonToken.BOOLEAN) {
return Boolean.toString(in.nextBoolean()); // 如果时布尔值,则转化为String
}
return in.nextString(); // 从json串中获取这个String类型的value并消耗它
}
@Override
public void write(JsonWriter out, String value) throws IOException {
out.value(value); // 不做任何处理直接写入Json串
}
}
到这里,关于Gson的TypeAdapter的原理也就讲得差不多了,回顾一下,因为Type有两类,对应的TypeAdapter也有两类,一类是ReflectiveTypeAdapter,针对复合类型,它的作用是把复合类型拆解成基本类型,另一类是针对基本类型的TypeAdapter,实现对应基本类型的Json串读写工作。而Gson本质上就是按照这两类TypeAdapter来完成Json解析的。
可以说,到这里,我们现在对Gson的基本工作流程有了一个基本的认识。
再一次分析Gson的执行逻辑
事实上,文章到这里结合上面的源码剖析和简化流程图,我们已经可以比较比较真实的分析出Gson的执行逻辑了。
Gson反序列化的日常用法:
UserInfo userInfo = getUserInfo();
Gson gson = new Gson();
String jsonStr = getJsonData();
UserInfo user = gson.fromJson(jsonStr,UserInfo.class); // 反序列化
gson.fromJson(jsonStr,UserInfo.class)方法内部真实的代码执行流程大致如下:
- 对jsonStr,UserInfo.class这两个数据进行封装
- 通过UserInfo.class这个Type来获取它对应的TypeAdapter
- 拿到对应的TypeAdapter(ReflectiveTypeAdapterFactor),并执行读取json的操作
- 返回UserInfo这个类型的对象。
我们描述的这个流程和Gson代码真实的执行流程已经没太大的区别了。
TypeAdapter的创建与工厂模式
Gson中除了适配器模式之外最重要的设计模式,可能就是工厂模式吧。因为Gson中众多的TypeAdapter都是通过工厂模式统一创建的:
public interface TypeAdapterFactory {
// 创建TypeAdapter的接口
TypeAdapter create(Gson gson, TypeToken type);
}
我们可以看看ReflectiveTypeAdapterFactory的实现
// ReflectiveTypeAdapterFactory的实现
public final class ReflectiveTypeAdapterFactory implements TypeAdapterFactory {
@Override public TypeAdapter create(Gson gson, final TypeToken type) {
Class raw = type.getRawType();
// 只要是Object的子类,就能匹配上
if (!Object.class.isAssignableFrom(raw)) {
// it's a primitive!
return null;
}
ObjectConstructor constructor = constructorConstructor.get(type);
return new Adapter(constructor, getBoundFields(gson, type, raw));
}
}
Gson在其构造方法中,就提前把所有的TypeAdapterFactory放在缓存列表中。
Gson(final Excluder excluder, final FieldNamingStrategy fieldNamingStrategy,
final Map> instanceCreators, boolean serializeNulls,
boolean complexMapKeySerialization, boolean generateNonExecutableGson, boolean htmlSafe,
boolean prettyPrinting, boolean lenient, boolean serializeSpecialFloatingPointValues,
LongSerializationPolicy longSerializationPolicy, String datePattern, int dateStyle,
int timeStyle, List builderFactories,
List builderHierarchyFactories,
List factoriesToBeAdded) {
...
...
...
List factories = new ArrayList();
// built-in type adapters that cannot be overridden
factories.add(TypeAdapters.JSON_ELEMENT_FACTORY);
factories.add(ObjectTypeAdapter.FACTORY);
// the excluder must precede all adapters that handle user-defined types
factories.add(excluder);
// users type adapters
factories.addAll(factoriesToBeAdded);
// type adapters for basic platform types
factories.add(TypeAdapters.STRING_FACTORY);
factories.add(TypeAdapters.INTEGER_FACTORY);
factories.add(TypeAdapters.BOOLEAN_FACTORY);
factories.add(TypeAdapters.BYTE_FACTORY);
factories.add(TypeAdapters.SHORT_FACTORY);
TypeAdapter longAdapter = longAdapter(longSerializationPolicy);
factories.add(TypeAdapters.newFactory(long.class, Long.class, longAdapter));
factories.add(TypeAdapters.newFactory(double.class, Double.class,
doubleAdapter(serializeSpecialFloatingPointValues)));
factories.add(TypeAdapters.newFactory(float.class, Float.class,
floatAdapter(serializeSpecialFloatingPointValues)));
factories.add(TypeAdapters.NUMBER_FACTORY);
factories.add(TypeAdapters.ATOMIC_INTEGER_FACTORY);
factories.add(TypeAdapters.ATOMIC_BOOLEAN_FACTORY);
factories.add(TypeAdapters.newFactory(AtomicLong.class, atomicLongAdapter(longAdapter)));
factories.add(TypeAdapters.newFactory(AtomicLongArray.class, atomicLongArrayAdapter(longAdapter)));
factories.add(TypeAdapters.ATOMIC_INTEGER_ARRAY_FACTORY);
factories.add(TypeAdapters.CHARACTER_FACTORY);
factories.add(TypeAdapters.STRING_BUILDER_FACTORY);
factories.add(TypeAdapters.STRING_BUFFER_FACTORY);
factories.add(TypeAdapters.newFactory(BigDecimal.class, TypeAdapters.BIG_DECIMAL));
factories.add(TypeAdapters.newFactory(BigInteger.class, TypeAdapters.BIG_INTEGER));
factories.add(TypeAdapters.URL_FACTORY);
factories.add(TypeAdapters.URI_FACTORY);
factories.add(TypeAdapters.UUID_FACTORY);
factories.add(TypeAdapters.CURRENCY_FACTORY);
factories.add(TypeAdapters.LOCALE_FACTORY);
factories.add(TypeAdapters.INET_ADDRESS_FACTORY);
factories.add(TypeAdapters.BIT_SET_FACTORY);
factories.add(DateTypeAdapter.FACTORY);
factories.add(TypeAdapters.CALENDAR_FACTORY);
factories.add(TimeTypeAdapter.FACTORY);
factories.add(SqlDateTypeAdapter.FACTORY);
factories.add(TypeAdapters.TIMESTAMP_FACTORY);
factories.add(ArrayTypeAdapter.FACTORY);
factories.add(TypeAdapters.CLASS_FACTORY);
// type adapters for composite and user-defined types
factories.add(new CollectionTypeAdapterFactory(constructorConstructor));
factories.add(new MapTypeAdapterFactory(constructorConstructor, complexMapKeySerialization));
this.jsonAdapterFactory = new JsonAdapterAnnotationTypeAdapterFactory(constructorConstructor);
factories.add(jsonAdapterFactory);
factories.add(TypeAdapters.ENUM_FACTORY);
// 注意,ReflectiveTypeAdapterFactor是要最后添加的
factories.add(new ReflectiveTypeAdapterFactory(
constructorConstructor, fieldNamingStrategy, excluder, jsonAdapterFactory));
this.factories = Collections.unmodifiableList(factories);
}
这里我们能够看到,ReflectiveTypeAdapterFactor最后被添加进去的,因为这里的添加顺序是有讲究的。我们看看getAdapter(type)方法就能知道。
getAdapter(type)这个方法就是gson通过type寻找到对应的TypeAdapter,这是Gson中非常重要的一个方法。
// 通过Type获取TypeAdapter
public TypeAdapter getAdapter(TypeToken type) {
try {
// 遍历缓存中所有的TypeAdapterFactory,
for (TypeAdapterFactory factory : factories) {
//如果类型匹配,则create()将会返回一个TypeAdapter,否则为nulll
TypeAdapter candidate = factory.create(this, type);
if (candidate != null) {
// candidate不为null,证明找到类型匹配的TypeAdapter.
return candidate;
}
}
throw new IllegalArgumentException("GSON (" + GsonBuildConfig.VERSION + ") cannot handle " + type);
}
}
ReflectiveTypeAdapterFactory之所以在缓存列表的最后一个,就是因为它能匹配几乎任何类型,因此,我们为一个类型遍历时,只能先判断它是不是基本类型,如果都不成功,最后再使用ReflectiveTypeAdapterFactor进行判断。
这就是Gson中用到的工厂模式。
关于代码的难点
我们重新回到getAdapter(type)这个方法,这个方法里面有一些比较难理解的代码
// 通过Type获取TypeAdapter
public TypeAdapter getAdapter(TypeToken type) {
// typeTokenCache是Gson的一个Map类型的缓存结构
// 0,首先尝试从缓存中获取是否有对应的TypeAdapter
TypeAdapter cached = typeTokenCache.get(type == null ? NULL_KEY_SURROGATE : type);
if (cached != null) {
return (TypeAdapter) cached;
}
// 1,alls 是Gson内部的ThreadLocal变量,用于保存一个Map对象
// map对象也缓存了一种FutureTypeAdapter
Map, FutureTypeAdapter> threadCalls = calls.get();
boolean requiresThreadLocalCleanup = false;
if (threadCalls == null) {
threadCalls = new HashMap, FutureTypeAdapter>();
calls.set(threadCalls);
requiresThreadLocalCleanup = true;
}
//2,如果从ThreadLocal内部的Map中找到缓存,则直接返回
// the key and value type parameters always agree
FutureTypeAdapter ongoingCall = (FutureTypeAdapter) threadCalls.get(type);
if (ongoingCall != null) {
return ongoingCall;
}
try {
创建一个FutureTypeAdapter
FutureTypeAdapter call = new FutureTypeAdapter();
// 缓存
threadCalls.put(type, call);
for (TypeAdapterFactory factory : factories) {
// 遍历所有的TypeAdapterFactory
TypeAdapter candidate = factory.create(this, type);
if (candidate != null) {
// 3, 设置委托的TypeAdapter
call.setDelegate(candidate);
// 缓存到Gson内部的Map中,
typeTokenCache.put(type, candidate);
return candidate;
}
}
//如果遍历都没有找到对应的TypeAdapter,直接抛出异常
throw new IllegalArgumentException("GSON (" + GsonBuildConfig.VERSION + ") cannot handle " + type);
} finally {
// 4,移除threadCalls内部缓存的 FutureTypeAdapter
threadCalls.remove(type);
if (requiresThreadLocalCleanup) {
//ThreadLocal移除该线程环境中的Map
calls.remove();
}
}
}
上述代码比较难以理解的地方我标注了序号,用于后面解释代码
方法里出现了FutureTypeAdapter这个TypeAdapter,似乎很奇怪,因为它没有FutureTypeAdapterFactory这个工厂类,我们先来看看 FutureTypeAdapter的内部构造
static class FutureTypeAdapter extends TypeAdapter {
private TypeAdapter delegate;
public void setDelegate(TypeAdapter typeAdapter) {
if (delegate != null) {
throw new AssertionError();
}
delegate = typeAdapter;
}
@Override public T read(JsonReader in) throws IOException {
if (delegate == null) {
throw new IllegalStateException();
}
return delegate.read(in);
}
@Override public void write(JsonWriter out, T value) throws IOException {
if (delegate == null) {
throw new IllegalStateException();
}
delegate.write(out, value);
}
}
这是一个明显的委派模式(也可称为代理模式)的包装类。我们都知道委托模式的功能是:隐藏代码具体实现,通过组合的方式同样的功能,避开继承带来的问题。但是在这里使用委派模式似乎并不是基于这些考虑。而是为了避免陷入无限递归导致对栈溢出的崩溃。
为什么这么说呢?我们来举个例子:
// 定义一个帖子的实体
public class Article {
// 表示帖子中链接到其他的帖子
public Article linkedArticle;
.....
.....
.....
}
Article类型中有一个linkedArticle属性,它的类型还是Article,根据我们之前总结的简化流程图:
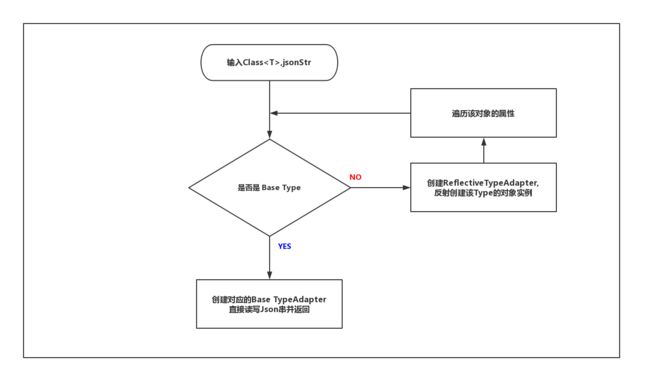
你会发现这里有一个死循环,或者说无法终结的递归。为了避免这个问题,所以先创建一个代理类,等到递归遇到同样的类型时直接复用返回,避免无限递归。也就是注释2那段代码的用意,在注释3处,再将创建成功的TypeAdapter设置到代理类中。就基本解决这个问题了。
当然说基本解决,是因为还要考虑多线程的环境,所以就出现了ThreadLocal这个线程局部变量,这保证了它只会在单个线程中缓存,而且会在单次Json解析完成后移出缓存。见上文注释1和注释4。这是因为无限递归只会发生在单次Json解析中,而且Gson内部已经有了一个TypeAdapterde 全局缓存(typeTokenCache),见注释0.
潜在的递归循环: gson.getAdapter(type) ---> (ReflectiveTypeAdapterFactory)factory.create(this, type) ---> getBoundFields() ---> createBoundField() ---> (Gson)context.getAdapter(fieldType)
关于Gson自定义解析
上文只讲到了Gson自己内部是如何实现Json解析的,其实Gson也提供了一些自定义解析的接口。主要是两种:
- 自己实现继承TypeAdapter
- 实现JsonSerializer/JsonDeserializer接口
那么,两者有什么区别呢?
追求效率更高,选第一种,想要操作更简单,实现更灵活,选第二种。
为什么这么说?举个例子,假设我们需要为Article这个JavaBean自定义解析,如果我们选择继承TypeAdapter的话,需要先实现TypeAdapter,然后注册。
// 继承TypeAdapter,实现抽象方法
public class ArticleTypeAdapter extends TypeAdapter{
@Override
public void write(JsonWriter out, Article value) throws IOException {
// 实现把Article中的实体数据的写入到JsonWriter中,实现序列化
}
@Override
public Article read(JsonReader in) throws IOException {
// 需要创建Article对象
// 把 JsonReader中的json串读出来,并设置到Article对象中
return null;
}
}
...
...
// 注册
Gson mGson = new GsonBuilder()
.registerTypeAdapter(Article.class, new ArticleTypeAdapter<>())//实际上注册到Gson的factories列表中
.create();
这样就实现了自定义的Json解析,这种方式的读写效率很高,但是不太灵活,因为必须要同时实现序列化和反序列化的工作。
而实现JsonSerializer/JsonDeserializer接口这种方式相对更简单
//JsonSerializer(json序列话)/JsonDeserializer(反序列化)可按需实现
public class ArticleTypeAdapter implements JsonDeserializer {
@Override
public Article deserialize(JsonElement json, Type typeOfT, JsonDeserializationContext context) throws JsonParseException {
// 需要创建Article对象
// 并从JsonElement中把封装好的Json数据结构读出来,并设置到Article对象中
return null;
}
}
// 注册
Gson mGson = new GsonBuilder()
.registerTypeAdapter(Article.class, new ArticleTypeAdapter<>())//实际上注册到Gson的factories列表中
.create();
我们可以看到,两者的区别,是后者更加灵活,序列化/返序列化可按需选择,而且它使用了JsonElement对Json数据进行再封装,从而使我们操作Json数据更加简单。不过正是因为使用了 JsonElement这种对Json数据再封装的类,而不是更加原始的JsonReader导致了代码执行效率的降低。
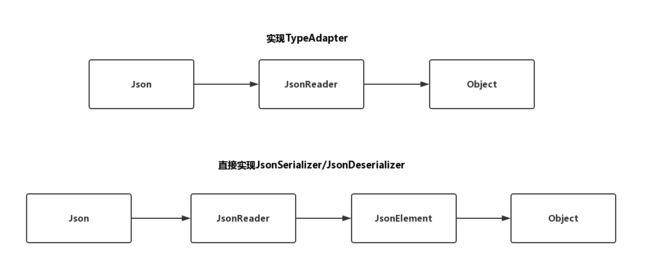
如上图所示,本质上就是多了一个中间层,导致解析效率的降低。不过话说回来,只要不是非常大批量复杂结构的连续解析,这种效率差异我们可以忽略不计,因此日常的开发,大家通过JsonSerializer/JsonDeserializer接口来实现自定义解析是一个相对更好的选择。