参考资料:
W3School网站XPath教程:http://www.w3school.com.cn/xpath/index.asp
lxml库官网:http://lxml.de/
在做网络爬虫的时候,对静态HTML页面内容的提取和解析是一项重要的工作。常用的HTML解析方法有三种:正则文本匹配、BeautifulSoup库解析和XPath解析。本文就讲一讲如何用XPath解析HTML。
什么是XPath
XPath是一种称为路径表达式的语法,可以用一个类似于Windows或Linux文件路径的表达式,定位到XML或HTML中的任意一个或多个节点元素,获取元素的各项信息,写起来非常方便。在解析结构比较规整的XML或HTML文档的时候,用XPath路径表达式非常快速、方便。
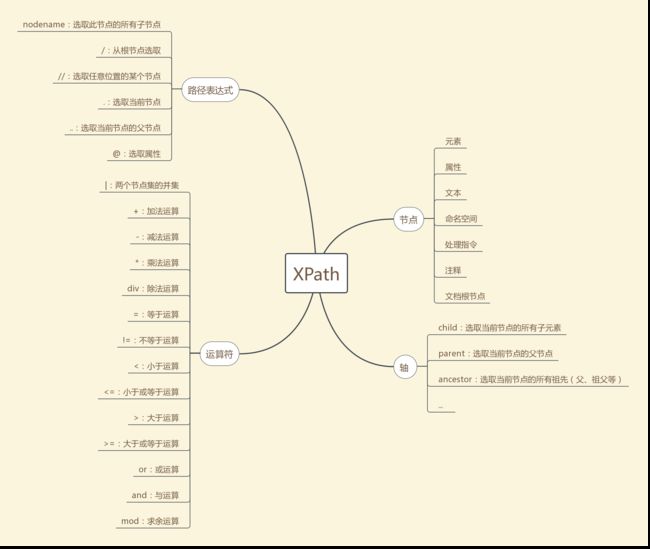
XPath语法中有四个关键的概念:节点、轴、路径表达式和运算符,思维导图如下:
在浏览器中使用XPath
其实现在很多浏览器都支持可以直接获取网页DOM对象的XPath路径,下面以Chrome浏览器为例。
比方说我们想获取这么个网页中的表格中的"城市名称"和"平均房价"两列的数据:
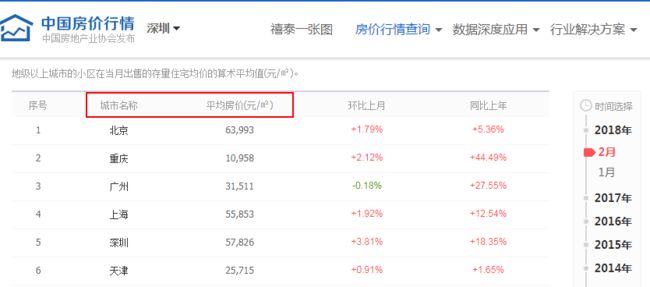
(网址: http://www.creprice.cn/rank/cityforsale.html?type=11&citylevel=1&y=2018&m=02)
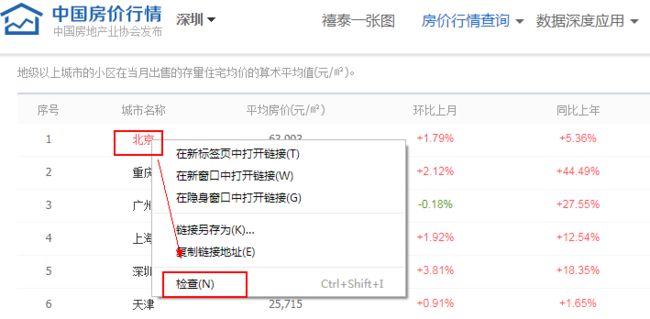
首先把鼠标放在第一行数据的"北京"的正上方,点击右键,点击"检查"菜单:
可以看到这时浏览器就弹出来了Elements窗口,在窗口中直接就定位到了"北京"这个DOM元素的HTML代码:
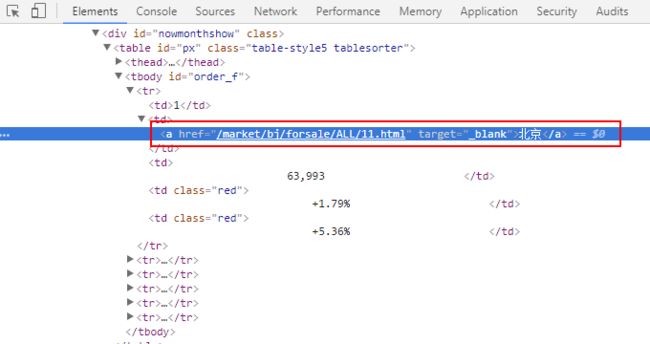
然后在"北京"所在的a标签的HTML代码上点击右键,然后点击"Copy > Copy XPath"菜单:
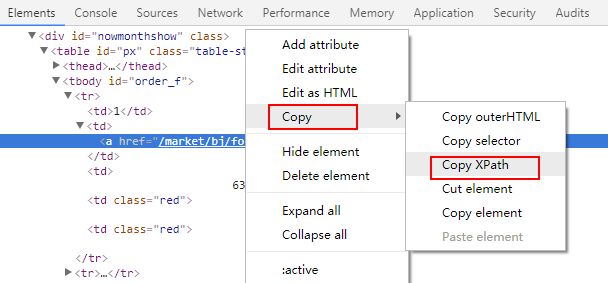
这时"北京"所在的a标签的XPath路径就被复制到了剪贴板中,然后复制到记事本中,发现其路径为://*[@id="order_f"]/tr[1]/td[2]/a。我们分析一下这个路径,首先是以//表示的相对路径开始,然后选择了id为order_f的元素(即表格的tbody元素),然后选择子元素中的第1个tr元素下的第2个td元素下的a标签元素,就是我们想要的"北京"这个文本所在的a标签。
注:XPath路径表达式中的下标索引是从1开始的。
下面我们再打开浏览器的Console控制台窗口,在控制台窗口的命令行中输入下面这个命令并按回车:
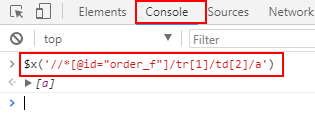
可以看到用$x(...)命令选取XPath路径的结果就是最终要定位的元素,而且即使是最终结果只有1个元素,还是被放在了一个数组里。还要注意的是,如果XPath表达式中含有双引号,那么$x()中的XPath路径要用单引号引起来。
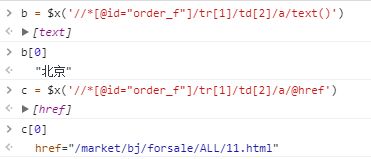
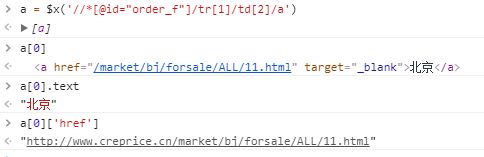
如果我们想继续获取这个a标签的链接href属性值和文本,该怎么做呢?需要这样做:
如果我想获取当前这个页面表格中的所有的城市名和对应的平均房价数据,又该怎么写XPath呢?我们先观察一下表格的HTML结构:
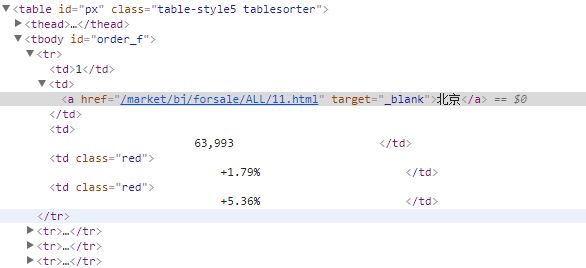
可以看到所有的房价数据都是在id为
order_f的tbody元素里面,这个tbody有多个tr元素,每个tr元素代表一行数据。每个tr元素又有多个td元素,每个td元素代表一列数据。我们需要的城市名和平均房价数据分别在第2个td和第3个td中。下面来尝试写一下选取表格中的所有城市名和平均房价的XPath表达式:
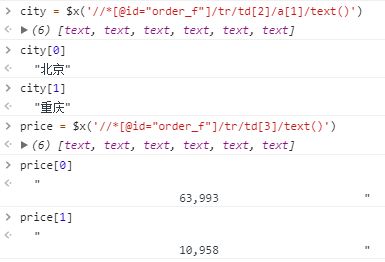
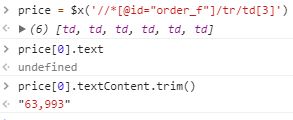
发现两个XPath表达式都写出来了,但有个问题就是price的文本的前后有很多空白,怎么去掉这些空白只保留房价数字呢?需要这样做:
用Python lxml模块解析HTML
Python有一个很强大的第三方库:lxml可以用来借助XPath语法解析XML和HTML文本,下面我们还是以解析上一小节中的网页中的房价数据为例来探讨lxml的用法。
安装lxml
pip install lxml
解析HTML
- 用HTML文本创建Element对象
# coding:utf-8
from lxml import etree
# 首先把刚刚网页的房价表格数据的HTML代码存在一个text变量中
# 注:为了简单起见,只选取3个城市的HTML代码
text = '''
序号
城市名称
平均房价(元/㎡)
环比上月
同比上年
1
北京
63,993
+1.79%
+5.36%
2
重庆
10,958
+2.12%
+44.49%
3
广州
31,511
-0.18%
+27.55%
'''
# 构建etree元素对象
html = etree.HTML(text)
print html
上面代码输出:
可见用etree.HTML方法构建了一个Element对象。
假设将上面的文本内容保存在当前目录下的data.txt文件中,还可以通过读取文件内容构建Element对象:
html = etree.parse('./data.txt',etree.HTMLParser())
print html
输出:
- 用XPath表达式选取行列表
接下来选取表格的行列表:
tr_list = html.xpath('//*[@id="order_f"]/tr')
print tr_list
输出:
[, , ]
可见行列表是Element对象列表。
- 选取每一行的城市名和房价
城市名:
cities = html.xpath('//*[@id="order_f"]/tr/td[2]/a/text()')
print cities
输出:
[u'北京',u'重庆',u'广州']
房价:
In [36]: prices = html.xpath('//*[@id="order_f"]/tr/td[3]/text()')
In [37]: print prices
[' \n 63,993 ', ' \n 10,958 ', ' \n 31,511 ']
In [38]: print [p.strip() for p in prices]
['63,993', '10,958', '31,511']
- 选取每一行的所有文本
选取一个DOM元素下的所有文本使用xpath('string(.)')函数:
In [39]: tr_list = html.xpath('//*[@id="order_f"]/tr')
In [40]: for tr in tr_list:
...: print tr.xpath('string(.)').strip()
...:
1
北京
63,993
+1.79%
+5.36%
2
重庆
10,958
+2.12%
+44.49%
3
广州
31,511
-0.18%
+27.55%
从上面这个例子也可以看出,Element对象的xpath函数支持链式调用。
- 遍历每一个元素
In [4]: tr_list = html.xpath('//*[@id="order_f"]/tr')
In [13]: for tr in tr_list:
...: print tr.xpath('./td[2]/a/text()')[0] + ':' + tr.xpath('./td[3]/text()')[0].strip()
...:
...:
北京:63,993
重庆:10,958
广州:31,511
注意:这里要注意的是,当对子元素再继续使用xpath表达式选取的时候,一定要使用相对路径的形式:./,否则选取的结果是和预期的不一样的。
lxml解析中文时出现乱码的解决措施
如果解析的HTML中有中文,lxml在选取的结果中可能会出现乱码,这个时候有以下几种解决措施:
- HTML文本编码使用unicode字符串:
u'...' - 读取HTML文件的时候使用unicode编码:
with open('text.html','r') as fin:
text = unicode(fin.read(),'utf-8')
html = etree.HTML(text)
使用lxml与BeautifulSoup的对比
我们知道BeautifulSoup也是一个HTML解析的利器,上面已经使用lxml解析了房价数据,下面再用BeautifulSoup来解析做一个对比:
# coding:utf-8
# lxml和BeautifulSoup解析HTML的对比
from bs4 import BeautifulSoup as BS
from collections import OrderedDict
from lxml import etree
import json
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 使用BeautifulSoup
def parse_html_by_BeautifulSoup(html_content):
'''
从房价HTML页面中解析出房价数据,返回一个以城市名为key、房价为vlaue的字典
:param html_content: 房价HTML网页内容
:return: 以城市名为key、房价为vlaue的字典
'''
soup = BS(html_content, 'html.parser')
tr_list = soup.find('tbody', attrs={'id': 'order_f'}).find_all('tr')
price_dict = OrderedDict()
for tr in tr_list:
city_name = tr.find_all('td')[1].text.strip()
price_str = tr.find_all('td')[2].text.strip()
price = int(''.join([d for d in price_str if d != ',']))
price_dict[city_name] = price
return price_dict
# 使用lxml
def parse_html_by_lxml(html_content):
'''
从房价HTML页面中解析出房价数据,返回一个以城市名为key、房价为vlaue的字典
:param html_content: 房价HTML网页内容
:return: 以城市名为key、房价为vlaue的字典
'''
html = etree.HTML(html_content)
# 获取行数据列表
tr_list = html.xpath('//*[@id="order_f"]/tr')
price_dict = OrderedDict()
# 遍历行数据列表,解析出每一行的城市名和房价数据
for tr in tr_list:
s = tr.xpath('string(.)').strip()
# 打印出当前行的所有文本,不同列用空格隔开
print re.sub(r'\s+',' ',s)
# 这里要使用相对路径:'./'
city = tr.xpath('./td[2]/a/text()')[0].strip()
price_str = tr.xpath('./td[3]/text()')[0].strip()
# 把数字字符串转为整数
price = int(''.join([d for d in price_str if d != ',']))
price_dict[city] = price
return price_dict
def main():
with open('./data.txt','r') as fin:
# 用unicode编码读取文本文件
html_content = unicode(fin.read(),'utf-8')
print json.dumps(parse_html_by_BeautifulSoup(html_content)).decode('unicode-escape').encode('gbk')
print '\n'
print json.dumps(parse_html_by_lxml(html_content)).decode('unicode-escape').encode('gbk')
if __name__ == '__main__':
main()
输出:
{"北京": 63993, "重庆": 10958, "广州": 31511}
1 北京 63,993 +1.79% +5.36%
2 重庆 10,958 +2.12% +44.49%
3 广州 31,511 -0.18% +27.55%
{"北京": 63993, "重庆": 10958, "广州": 31511}
从上面的对比可以看出,两种方式解析的结果是一样的,但是个人觉得lxml在解析HTML时还是更简洁好用一些。而且lxml是使用XPath这种文本语法而非函数API,写起来更轻量化,不必去研究BeautifulSoup库的各种函数API的细节怎么写,只要会XPath语法就可以轻松解析HTML。这就好比在处理复杂的文本时,使用正则表达式比使用字符串类的函数API更好用、更强大。
上述代码已经放在了:我的GitHub