1 RDD编程实战案例一
数据样例

字段说明:

其中cid中1代表手机,2代表家具,3代表服装
1.1 计算订单分类成交金额
需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称,统计出某一天商品各个分类的成交金额,并保存至Mysql中
(1)法一,将json数据解析出来,直接使用
object IncomeKpi { private val logger: Logger = LoggerFactory.getLogger(IncomeKpi.getClass) def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean // 创建SparkContext val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName) if(isLocal){ conf.setMaster("local[*]") } val sc: SparkContext = new SparkContext(conf) // 使用SparkContext创建RDD val lines: RDD[String] = sc.textFile(args(1)) val tpRDD: RDD[(Int, Double)] = lines.map(line => { var tp = (-1, 0.0) var jsonObj: JSONObject = null // 使用FastJSON解析数据 try { jsonObj= JSON.parseObject(line) val cid: Int = jsonObj.getInteger("cid").toInt val money: Double = jsonObj.getDouble("money").toDouble tp = (cid, money) } catch { case e:JSONException => { // 处理有问题的数据 logger.error("parse json error: => " + line) } } tp }) val reduced: Array[(Int, Double)] = tpRDD.reduceByKey(_+_).collect() println(reduced.toBuffer) } }
运行结果:

发现有个不要的数据没被过滤掉,此处自己还不知道不要的数据怎么处理掉
(2)法二,定义一个bean去保存解析json数据得到的字段,需要时再取出来(此处的bean用case class,这样方便点,不需要序列化)
这里有两种做法,使用foreach将数据一条一条拿出来(每拿一条数据会与数据库建立一个连接),效率比较低,所以使用foreachPartition,foreach直接取出rdd的kv对,而foreachPartition为迭代器
Foreach与foreachPartition的区别
Foreach与foreachPartition都是在每一个partition中对iterator进行操作,
不同的是,foreach是直接在每一个partition中直接对iterator运行foreach操作,而传入的function仅仅是在foreach内部使用,
而foreachPartition是在每一个partition中把iterator给传入的function,让function自己对iterator进行处理.
foreach
object IncomeKpi2 { private val logger: Logger = LoggerFactory.getLogger(IncomeKpi2.getClass) def main(args: Array[String]): Unit = { val isLocal: Boolean = args(0).toBoolean // 创建SparkContext val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName) if(isLocal){ conf.setMaster("local[*]") } val sc: SparkContext = new SparkContext(conf) // 使用sc创建rdd val lines: RDD[String] = sc.textFile(args(1)) // 使用fastJson解析json数据,将数据封装到bean中 val beanRDD: RDD[IncomeBean] = lines.map(line => { var bean:IncomeBean = null try { bean = JSON.parseObject(line, classOf[IncomeBean]) } catch { case e: JSONException => { logger.error("parse json error") } } bean }) // 过滤掉不需要的数据 val filtered: RDD[IncomeBean] = beanRDD.filter(_ != null) // 将数据转成元组形式 val cidAndMoneyRDD: RDD[(Int, Double)] = filtered.map(bean => { val cid: Int = bean.cid.toInt val money: Double = bean.money (cid, money) }) // 分组聚合 val reduced: RDD[(Int, Double)] = cidAndMoneyRDD.reduceByKey(_+_) // 再次创建一个RDD,用来读取分类文件 val cLines: RDD[String] = sc.textFile(args(2)) val cidAndCName: RDD[(Int, String)] = cLines.map(line => { val split: Array[String] = line.split(",") val cid: Int = split(0).toInt val cname: String = split(1) (cid, cname) }) // 将两个rdd使用join关联起来 val joined: RDD[(Int, (Double, String))] = reduced.join(cidAndCName) // 对join后的数据进行处理 val res: RDD[(String, Double)] = joined.map(t => (t._2._2, t._2._1)) res.foreach(dataToMySQL) } // 创建用于连接数据库并将res结果存入数据库的函数 val dataToMySQL: ((String, Double)) => Unit = (t:(String, Double)) => { var ps: PreparedStatement = null var conn: Connection = null // 创建一个Connection try { conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "root", "feng") // 对sql语句进行预编译,并插入相应的数据 ps = conn.prepareStatement("insert into t_result values (null,?,?,?)") ps.setString(1, t._1) ps.setDouble(2, t._2) ps.setDate(3, new Date(System.currentTimeMillis())) // 执行 ps.executeUpdate() } catch{ case e:SQLException => { // 有误的数据 } } finally{ // 释放MySQL的资源 if (ps != null){ ps.close() } if (conn != null) { conn.close() } } () } }
foreachPartition(与foreach的区别就是从rdd中获取数据有点不一样)
object IncomeKpi3 { private val logger: Logger = LoggerFactory.getLogger(IncomeKpi2.getClass) def main(args: Array[String]): Unit = { val isLocal: Boolean = args(0).toBoolean // 创建SparkContext val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName) if(isLocal){ conf.setMaster("local[*]") } val sc: SparkContext = new SparkContext(conf) // 使用sc创建rdd val lines: RDD[String] = sc.textFile(args(1)) // 使用fastJson解析json数据,将数据封装到bean中 val beanRDD: RDD[IncomeBean] = lines.map(line => { var bean:IncomeBean = null try { bean = JSON.parseObject(line, classOf[IncomeBean]) } catch { case e: JSONException => { logger.error("parse json error") } } bean }) // 过滤掉不需要的数据 val filtered: RDD[IncomeBean] = beanRDD.filter(_ != null) // 将数据转成元组形式 val cidAndMoneyRDD: RDD[(Int, Double)] = filtered.map(bean => { val cid: Int = bean.cid.toInt val money: Double = bean.money (cid, money) }) // 分组聚合 val reduced: RDD[(Int, Double)] = cidAndMoneyRDD.reduceByKey(_+_) // 再次创建一个RDD,用来读取分类文件 val cLines: RDD[String] = sc.textFile(args(2)) val cidAndCName: RDD[(Int, String)] = cLines.map(line => { val split: Array[String] = line.split(",") val cid: Int = split(0).toInt val cname: String = split(1) (cid, cname) }) // 将两个rdd使用join关联起来 val joined: RDD[(Int, (Double, String))] = reduced.join(cidAndCName) // 对join后的数据进行处理 val res: RDD[(String, Double)] = joined.map(t => (t._2._2, t._2._1)) res.foreachPartition(dataToMySQL) } // 创建用于连接数据库并将res结果存入数据库的函数 val dataToMySQL = (it:Iterator[(String, Double)]) => { var ps: PreparedStatement = null var conn: Connection = null // 创建一个Connection try { it.foreach( t =>{ conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "root", "feng") // 对sql语句进行预编译,并插入相应的数据 ps = conn.prepareStatement("insert into t_result values (null,?,?,?)") ps.setString(1, t._1) ps.setDouble(2, t._2) ps.setDate(3, new Date(System.currentTimeMillis())) // 执行 ps.executeUpdate() }) } catch{ case e:SQLException => { // 有误的数据 } } finally{ // 释放MySQL的资源 if (ps != null){ ps.close() } if (conn != null) { conn.close() } } () } }
1.2 将订单数据关联分类信息,然后将一些数据存放到Hbase中
OrderDetailToHbase
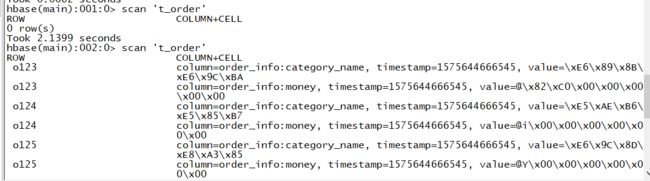
package com._51doit.spark03 import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet} import java.util import com._51doit.spark02.bean.IncomeBean import com._51doit.utils.HBaseUtil import com.alibaba.fastjson.{JSON, JSONException} import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.hbase.{TableName, client} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object OrderDetailToHbase { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) //创建RDD val lines: RDD[String] = sc.textFile(args(1)) val beanRDD: RDD[IncomeBean] = lines.map(line => { var bean: IncomeBean = null try { bean = JSON.parseObject(line, classOf[IncomeBean]) } catch { case e: JSONException => { //单独处理 } } bean }) //过滤有问题的数据 val filtered: RDD[IncomeBean] = beanRDD.filter(_ != null) // 使用分区创建一个数据库连接,再使用这个连接查询信息 val result: RDD[IncomeBean] = filtered.mapPartitions((it: Iterator[IncomeBean]) => { if(it.nonEmpty) { val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "root", "feng") val ps: PreparedStatement = conn.prepareStatement("SELECT cname FROM t_category WHERE cid = ?") // 根据bean中的cid查找对应的分类名 it.map(bean => { ps.setInt(1, bean.cid) val resultSet: ResultSet = ps.executeQuery() //获取rs中的结果 var name: String = null while (resultSet.next()) { name = resultSet.getString("cname") } bean.categoryName = name //进行判断,如果迭代器中已经没有数据了,关闭连接 if (resultSet != null) { resultSet.close() } if (!it.hasNext) { if (ps != null) { ps.close() } if (conn != null) { conn.close() } } bean }) } else{ // 直接返回空迭代器 it } }) //将数据保存到Hbase中 result.foreachPartition(it => { // 创建一个Hbase的连接 val connection: client.Connection = HBaseUtil.getConnection("feng01,feng02,feng03", 2181) val table = connection.getTable(TableName.valueOf("t_order")) val puts = new util.ArrayList[Put]() //遍历迭代器中的数据 it.foreach(bean => { //设置数据,包括rk val put = new Put(Bytes.toBytes(bean.oid)) //设置列族的数据 put.addColumn(Bytes.toBytes("order_info"), Bytes.toBytes("category_name"), Bytes.toBytes(bean.categoryName)) put.addColumn(Bytes.toBytes("order_info"), Bytes.toBytes("money"), Bytes.toBytes(bean.money)) //将put放入到puts这个list中 puts.add(put) if(puts.size() == 100) { //将数据写入到Hbase中 table.put(puts) //清空puts集合中的数据 puts.clear() } }) //将没有达到100的数据也写入到Hbase中 table.put(puts) //关闭Hbase连接 connection.close() }) sc.stop() } }
HBaseUtil:用来创建HBase的连接
package com._51doit.utils import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory} /** * Hbase的工具类,用来创建Hbase的Connection */ object HBaseUtil extends Serializable { /** * @param zkQuorum zookeeper地址,多个要用逗号分隔 * @param port zookeeper端口号 * @return */ def getConnection(zkQuorum: String, port: Int): Connection = synchronized { val conf = HBaseConfiguration.create() conf.set("hbase.zookeeper.quorum", zkQuorum) conf.set("hbase.zookeeper.property.clientPort", port.toString) ConnectionFactory.createConnection(conf) } }
pom.xml
xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com._51doitgroupId>
<artifactId>spark01artifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<scala.version>2.11.12scala.version>
<spark.version>2.3.3spark.version>
<hadoop.version>2.8.5hadoop.version>
<encoding>UTF-8encoding>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.57version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.8.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.8.5version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>2.0.4version>
dependency>
dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
plugin>
plugins>
pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<executions>
<execution>
<id>scala-compile-firstid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
<execution>
<id>scala-test-compileid>
<phase>process-test-resourcesphase>
<goals>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<executions>
<execution>
<phase>compilephase>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
此处自己出现的问题:
- 依赖的冲突
使用maven管理库的依赖,有个好处就是连同库的依赖的全部jar文件一起下载,免去手工添加的麻烦,但同时也带来了同一个jar包会被下载不同版本的问题。解决方法就是在pom的配置文件中用
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
exclusion>
exclusions>
dependency>
- Hbase开启出现问题
开启Hbase的前提是一定要先开启zookeeper和hdfs文件系统(zookeeper先于hdfs启动)
运行结果:
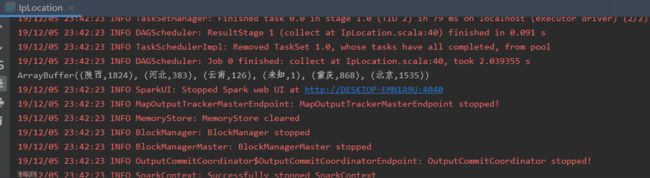
1.3 使用Spark读取日志文件,根据IP地址,查询日志文件中的IP地址对应的位置信息 ,并统计处各个省份的用户量
日志文件

ip文件(ip规则数据)

说明:此处加载ip规则数据若以rdd的形式的话(sc.textFile(文件路径)),由于ip规则数据会被切片成多块,这样每个task就会加载ip规则数据中的一部分,这样的话,当进行ip关联的时候(日志文件中的ip找对应的省份等信息),就可能关联不到需要的信息,ip规则数据越大,日志文件中的ip关联不到对应的信息的可能性越大(ip规则数据越大,切片的数量就会越大,相应的分区也就越多,意味着task的数量也会越多,每个task中读取到的数据占总数据的比例就会减少)。所以说,使用rdd的形式读取ip规则数据不可行,那么该怎么办呢?
直接的想法是直接通过IO流读取ip规则数据,并保存至内存中,可以改进的一点是使用静态代码块,这样一个executor中的多个task使用这些ip规则数据时只需要加载一次ip规则数据(其他task能直接获取到数据地址的引用)。
IpRulesLoader(此处使用静态代码块,加载IP数据(从hdfs中读取),在Ececutor的类加载时执行一次),经过此代码处理后得到数组 ArrayBuffer[(Long, Long, String, String)],参数依次对应起始IP, 结束IP 省份名 城市名
package com._51doit.spark03 import java.io.{BufferedReader, InputStreamReader} import java.net.URI import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.{FSDataInputStream, FileSystem, Path} import scala.collection.mutable.ArrayBuffer object IpRulesLoader { // 定义一个数组用来存放处理好的数据 private val ipRules: ArrayBuffer[(Long, Long, String, String)] = new ArrayBuffer[(Long,Long,String,String)]() //加载IP规则数据,在Executor的类加载是执行一次 //静态代码块 { //读取HDFS中的数据 val fileSystem: FileSystem = FileSystem.get(URI.create("hdfs://feng05:9000"), new Configuration()) val inputStream: FSDataInputStream = fileSystem.open(new Path("/ip/ip.txt")) val br: BufferedReader = new BufferedReader(new InputStreamReader(inputStream)) var line:String = null do { line = br.readLine() if(line != null) { //处理IP规则数据 val fields = line.split("[|]") val startNum = fields(2).toLong val endNum = fields(3).toLong val province = fields(6) val city = fields(7) val t = (startNum, endNum, province, city) ipRules += t } } while(line != null) } def getAllRules: ArrayBuffer[(Long, Long, String, String)] ={ ipRules } }
注意,此处不能使用while来读取数据,要是用do while
IpLocation:
package com._51doit.spark03 import com._51doit.utils.IpUtils import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ArrayBuffer object IpLocation { def main(args: Array[String]): Unit = { // 决定是否本地运行 val isLocal = args(0).toBoolean val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName) if(isLocal){ conf.setMaster("local[*]") } // 创建sc,读取日志信息,得到相应的rdd val sc: SparkContext = new SparkContext(conf) val lines: RDD[String] = sc.textFile(args(1)) // 处理日志信息 val provinceAndOne: RDD[(String, Int)] = lines.map(line => { val split: Array[String] = line.split("\\|") // 获取ip地址,并将ip地址转换成Long的形式 val ipStr: String = split(1) val ipLong: Long = IpUtils.ip2Long(ipStr) // 获取Ip规则 val allRules: ArrayBuffer[(Long, Long, String, String)] = IpRulesLoader.getAllRules val index: Int = IpUtils.binarySearch(allRules, ipLong) var province: String = "未知" if (index != -1) { province = allRules(index)._3 } (province, 1) }) // 按照省份进行聚合 val result: RDD[(String, Int)] = provinceAndOne.reduceByKey(_+_) //将计算好的数据保存到MySQL println(result.collect().toBuffer) sc.stop() } }
IpUtils(将ip转成十进制,二进制查找相应地址信息,从而获取对应的省份信息)
package com._51doit.utils import scala.collection.mutable.ArrayBuffer object IpUtils { /** * 将IP地址转成十进制 * * @param ip * @return */ def ip2Long(ip: String): Long = { val fragments = ip.split("[.]") var ipNum = 0L for (i <- 0 until fragments.length) { ipNum = fragments(i).toLong | ipNum << 8L } ipNum } /** * 二分法查找 * * @param lines * @param ip * @return */ def binarySearch(lines: ArrayBuffer[(Long, Long, String, String)], ip: Long): Int = { var low = 0 //起始 var high = lines.length - 1 //结束 while (low <= high) { val middle = (low + high) / 2 if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2)) return middle if (ip < lines(middle)._1) high = middle - 1 else { low = middle + 1 } } -1 //没有找到 } }
运行结果: