常用聚集函数
是对一组或一批数据进行综合操作后返回一个结果,如下:
| count | 行总数 |
| avg | 平均数 |
| sum | 列值和 |
| max | 最大值 |
| min | 最小值 |
用法说明
count([{distinct|all} '列名'|*) 为列值时空不在统计之内,为*时包含空行和重复行
idle> select count(comm) from emp;
COUNT(COMM)
-----------
4
idle> select count(ename) from emp;
COUNT(ENAME)
------------
14
idle> select count(*) from emp;
COUNT(*)
----------
14
idle> select count(deptno) from emp;
COUNT(DEPTNO)
-------------
14
idle> select count(distinct deptno) from emp;
COUNT(DISTINCTDEPTNO)
---------------------
3
idle> select count(all deptno) from emp;
COUNT(ALLDEPTNO)
----------------
14
上面执行的聚集函数都是对所有记录统计,如果想分组统计(比如统计部门的平均值)需要使用group by,为了限制分组统计的结果需要使用having过滤
求出每个部门的平均工资
idle> select deptno,avg(sal) from emp group by deptno;
DEPTNO AVG(SAL)
---------- ----------
30 1566.66667
20 2175
10 2916.66667
分组再排序
idle> select deptno,avg(sal) from emp group by deptno order by deptno ;
DEPTNO AVG(SAL)
---------- ----------
10 2916.66667
20 2175
30 1566.66667
分组修饰列可以是未选择的列
idle> select avg(sal) from emp group by deptno order by deptno;
AVG(SAL)
----------
2916.66667
2175
1566.66667
如果在查询中使用了分组函数,任何不在分组函数中的列或表达式必须在group by子句中。因为分组函数是返回一行而其他列显示多行显示结果矛盾。
idle> select avg(sal) from emp ;
AVG(SAL)
----------
2073.21429
idle> select deptno,avg(sal) from emp;
select deptno,avg(sal) from emp
*
ERROR at line 1:
ORA-00937: not a single-group group function
idle> select deptno,avg(sal) from emp group by deptno ;
DEPTNO AVG(SAL)
---------- ----------
30 1566.66667
20 2175
10 2916.66667
idle> select deptno,avg(sal) from emp group by deptno order by job;
select deptno,avg(sal) from emp group by deptno order by job
*
ERROR at line 1:
ORA-00979: not a GROUP BY expression
group by 的过滤
查出平均工资大于2000的部门
idle> select deptno,avg(sal) avg from emp group by deptno where avg >2000;
select deptno,avg(sal) avg from emp group by deptno where avg >2000
*
ERROR at line 1:
ORA-00933: SQL command not properly ended
group by后不能再接where子句过滤,where过滤只能加到group by前端这样又不能满足要求,对分组后的过滤要使用having。
idle> select deptno,avg(sal) avg from emp group by deptno having avg(sal) >2000;
DEPTNO AVG
---------- ----------
20 2175
10 2916.66667
分组函数的注意事项:
- 分组函数只能出现在select,order by,having,分析函数子句中
- 分组函数会忽略NULL 除了count(*)
- 分组函数中可以使用ALL或distinct;ALL是默认值,统计所有。加上distinct则只统计不同
- 如果选择的列里有普通列,表达式和分组列,那么普通列和表达式都必须出现在group by中 。
如下操作:得到t5表中有部分行是重复的,找出重复的行
SQL> create table t5 as select * from emp;
Table created.
SQL> insert into t5 select * from emp where deptno=20;
5 rows created.
SQL> commit;
Commit complete.
SQL>
查看:
select count(ename),ename from t5 group by ename having COUNT(ENAME) !=1;
删除: 不是函数,而是列名
delete t5 where rowid in (select max(rowid) from t5 group by ename having count(ename)>1);
行转列
pivot(行专列)and unpivot(列转行)函数的使用
pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,
比如 select distinct code from customers

select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果', '橘子', '葡萄', '芒果'));
![]()

select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
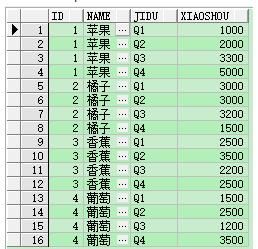
注意:unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量
普通方式
create table t4(id int,name varchar2(10),subject varchar2(20),grade number); insert into t4 values(1,'ZORRO','语文',70); insert into t4 values(2,'ZORRO','数学',80); insert into t4 values(3,'ZORRO','英语',75); insert into t4 values(4,'SEKER','语文',65); insert into t4 values(5,'SEKER','数学',75); insert into t4 values(6,'SEKER','英语',60); insert into t4 values(7,'BLUES','语文',60); insert into t4 values(8,'BLUES','数学',90); insert into t4 values(9,'PG','数学',80); insert into t4 values(10,'PG','英语',90); commit; SQL> select * from t4; ID NAME SUBOBJECT GRADE ---------- ---------- -------------------- ---------- 1 ZORRO 语文 70 2 ZORRO 数学 80 3 ZORRO 英语 75 4 SEKER 语文 65 5 SEKER 数学 75 6 SEKER 英语 60 7 BLUES 语文 60 8 BLUES 数学 90 9 PG 数学 80 10 PG 英语 90 10 rows selected. SQL> select name,max(case subobject when '语文' then grade else 0 end) “语文”, max(case subobject when '数学' then grade else 0 end) "数学", max(case subobject when '英语' then grade else 0 end) "英语" from t4 group by name; ---------------------------- | name | 语文 | 数学| 英语| ---------------------------- | zorro | 70 | 80 | 75 | ---------------------------- | seker | 65 | 75 | 60 | ---------------------------- | blues | 60 | 90 | 0 | ---------------------------- | PG | 0 | 80 | 90 | ----------------------------
![]()