集成学习


随机森林算法:
一般用于大规模数据,百万级以上的。
在Bagging算法的基础上,如上面的解释,在去重后得到三组数据,那么再随机抽取三个特征属性,选择最佳分割属性作为节点来创建决策树。可以说是

RF(随机森林)的变种:
ExtraTree算法
凡解:和随机森林的原理基本一样。主要差别点如下
①随机森林是在含有m个数据的原数据集上有放回的抽取m个数据,而ExtraTree算法是直接用原数据集训练。
②随机森林在选择划分特征点的时候会和传统决策树一样,会基于信息增益、信息增益率、基尼系数、均方差等原则来选择最优特征值;而ExtraTree会随机的选择一个特征值来划分决策树。
TRTE算法
不重要,了解一下即可
官解:TRTE是一种非监督的数据转化方式。对特征属性重新编码,将低维的数据集映射到高维,从而让映射到高维的数据更好的应用于分类回归模型。
划分标准为方差
看例子吧直接:

IForest
IForest是一种异常点检测算法,使用类似RF的方式来检测异常点
此算法比较坑,适应性不强。
1.在随机采样的过程中,一般只需要少量数据即可;
•2.在进行决策树构建过程中,IForest算法会随机选择一个划分特征,并对划分特征随机选择一个划分阈值;
•3.IForest算法构建的决策树一般深度max_depth是比较小的。
此算法可以用,但此算法连创作者本人也无法完整的解释原理。
RF(随机森林)的主要优点:
●1.训练可以并行化,对于大规模样本的训练具有速度的优势;
●2.由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高的训练性能;
●3.可以给出各个特征的重要性列表;
●4.由于存在随机抽样,训练出来的模型方差小,泛化能力强;
●5. RF实现简单;
●6.对于部分特征的缺失不敏感。
RF的主要缺点:
●1.在某些噪音比较大的特征上(数据特别异常情况),RF模型容易陷入过拟合;
●2.取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的
效果。

Boosting算法
关键点与难点在于如何修改数据
原理:将 含有m个数据的数据集 丢给一个弱学习器1分类,比如分对百分之60,
那么经过一定手段修改数据集,数据个数还是m个,将修改后的数据集扔给弱学习器2训练,学习器2把在学习器1中分错的那一部分又分对百分之三十。
再修改数据集,将修改后的数据集扔给弱学习器3训练,学习器3把在学习器1和2中分错的那一部分又分对百分之三十。
最后加权融合为一个强学习器。
......
......
如下图:

重点:修改数据集的方法
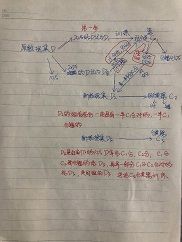
①凡解(配图讲解,绝对可以懂):
设原数据集为D,将其咔嚓好几刀分为n份,假设分成了三份,一份70%,一份20%,一份10%。
先拿70%这份去给弱分类器C1进行训练,假设C1分对了55%,分错了45%。
再提溜20%那一份作为测试集,扔给C1训练,分对了算C1牛批,C1没出息分错了的话就扔给楼下的D2数据集
由C1分错了的数据加上一些C1分对了的数据共同组成数据集D2,把D2丢给一个新的弱分类器C2训练。(为什么加上一些C1分对了的数据?为了保证数据的完整性,如果D2中含有C1分的错的多,那么C2分类时就会偏向于C1分错的这部分,因为它多啊,所以尽量D2中是一半C1分对的,一半C1分错的)
以此类推,生生不息
老板,上图!
②AdaBoost算法修改数据
最好用来作分类
凡解:总而言之一句话:修改权重,基于上上个图片,可以看出,一个一个的弱分类器分类后,越往后的弱分类器分类误差率越小,也就是分类效果越好(因为分类错误的越来越少了),
官解一:

其中Gm为从第一个开始的一个一个的弱分类器,G1,G2,G3......Gm。
αm为我们分配给各个分类器的权重。
如下公式是强分类器的公式:

公式解释:公式的结果是加权求和的形式,组合成强分类器。Gm是弱分类器,那么Gm分类的结果就是1or-1,1or-1,1or-1,αm是权重,可以是任意值,所以αm是连续的,那么 也就是连续的,但是我们最后搭建的是分类器,所以用符号函数,把连续的量变成离散的量。
也就是连续的,但是我们最后搭建的是分类器,所以用符号函数,把连续的量变成离散的量。
那么现在就该求αm和Gm了吧,首先搞清楚分类的目标是什么?答:分类的准确率。自然就是错误率越低越好咯。
那我们以分类错误的几率作为损失函数,分类错误的几率如何表示?分类错误的个数/总的个数,分类错误的个数如何表示?G(x)≠yi,G(x)是强分类器分类的结果,yi是对应的正确的分类标签。G(x)≠yi也就是说强学习器分类的结果和它正确的所属类别不同,不就是分类错误咯。为了便于操作,用指示函数把它套上,即I(G(x)≠yi),意思是分类错误的话记作1,分类正确的话记作0,i从1到n就是分类错误的样本个数 ,n是总的个数,即所有样本的个数,再除以n,不就是错误率了吗,最后损失函数公式如下:
,n是总的个数,即所有样本的个数,再除以n,不就是错误率了吗,最后损失函数公式如下: ,
,
现在再回归我们一开始的目标:让其准确率最高,即错误率最低,求αm和Gm。----很明显,损失函数和αm与Gm没有半毛钱关系,那怎么办?扩大呗,扩大后让它们有关系呗,怎么扩大?这个有点乱,我用手写表示吧,上图!

最后损失函数公式建立起来关系后为:
目的是准确率最高,那么找损失函数最小值即可,也就是找 最小值即可。
最小值即可。
f(x)其实是α1G1+α2G2+α3G3+.....+αmGm,而Boosting思想是搭建了第一个分类器才搭建第二个分类器,那么当我要求αmGm的时候,实际上从α1G1到αm-1Gm-1都是知道的,那么损失函数中的f(x)就可以写成f(m-1)(x)+αmGm,得到
化简后得到

那么实际过程中,假设Gm这个分类器我们已知了,那么最后的式子就只有一个αm是未知参数,要错误率最小,即求loss函数的最小值,即求导=0即可,对谁求导?一个未知参数,αm。求导过程如下,手推了一遍,有些乱,但是易懂,嫌乱的后面有官解过程

Adaboost第二种修改数据集的方式其实就是修改样本的权重,即wi
如下图


权重更新用的就是 公式
公式
每搭建一个弱分类器,就和之前的弱分类器集成一下,集成完之后看看结合成的强学习器的结果,达到要求不再往下进行,达不到继续搭建弱分类器,要求就是准确率。

其中,基本上在代码中可调整的参数仅有n_estimators(弱分类器的个数)

GBDT(梯度提升迭代决策树)
GBDT也是Boosting算法的一种,但是和AdaBoost算法不同;区别如下:
AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮
的迭代;
GBDT也是迭代,但是GBDT要求弱学习器必须是回归CART模型,而且
GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。优先做回归问题。
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度。 方差越高,模型越复杂,越容易过拟合;偏差越高,模型越简单,越容易欠拟合。
备注:所有GBDT算法中,底层都是回归树。
原理如下图

所有树的结果累加起来就是最终结果。
GBDT与随机森轮的区别:
Stacking
Stacking是指训练一个模型用于组合(combine)其它模型(基模型/基学习器)的技术。即首先训练出多个不同的模型,然后再以之前训练的各个模型的输出作为输入来新训练一个新的模型,从而得到一个最终的模型。一般情况下使用单层的Logistic回归作为组合模型。
XGboost算法
XGBoost是GBDT算法的一种变种,是一种常用的有监督集成学习算法;是一种伸缩性强、便捷的可并行构建模型的GradientBoosting算法。
XGBoost官网:http://xgboost.readthedocs.io;
XGBoost支持开发语言:Python、R、Java、Scala、C++等。