1. zookeeper 在 kafka 中起到什么作用
-
Controller 选举
- Controller 是一个特殊的 Broker, 其负责维护所有 Partition 的 leader/follower 关系。当有 partition 的 leader 挂掉之后,controller 会重新从同步队列中选出一个 leader。
- ==Zookeeper 负责从 Broker 中选举出一个作为 Controller, 并确保其唯一性。 同时, 当Controller 宕机时, 选举一个新的。==
-
集群 membership
- ==记录集群中都有哪些活跃着的Broker。==
-
Topic 配置
- ==记录有哪些Topic, Topic 都有哪些 Partition,Replica 存放在哪里, Leader 是谁。==
==在 consumer group 发生变化时进行 rebalance。==
-
配额(0.9.0+)
- 记录每个客户能够读写的数据量。
-
ACLs(0.9.0+)
- 记录对Topic 的读写控制。
-
high-level consumer(已废弃)
- 记录consumer group 及其成员和offset 信息。
2. kafka 在 zookeeper 上创建的目录结构
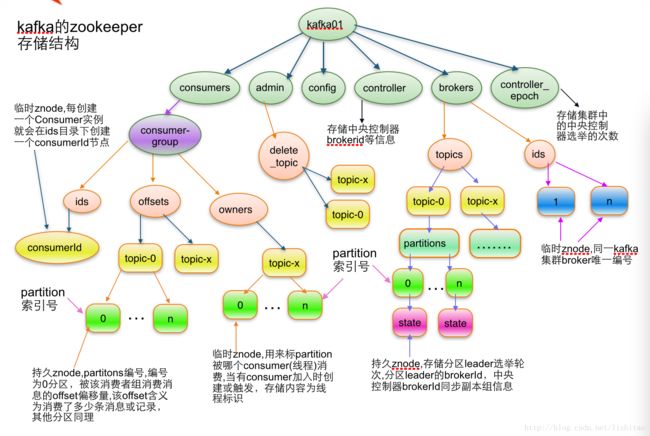
详细内容参考链接:
kafka笔记-Kafka在zookeeper中的存储结构【转】
注册的节点如下:
==consumers、admin、config、controller、brokers、controller_epoch==
-
topic 注册信息
/brokers/topics/[topic]:存储某个 topic 的 partitions 所有分配信息
-
partition状态信息
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
-
Broker注册信息
/brokers/ids/[0...N]
每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时znode(EPHEMERAL)
-
Controller epoch
/controller_epoch -> int (epoch)
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1
-
Controller注册信息
/controller -> int (broker id of the controller) 存储center controller中央控制器所在kafka broker的信息。这个值默认是 1,当 controller 节点挂掉后重新选举 controller 后,值会 +1
-
Consumer注册信息
每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息
/consumers/[groupId]/ids/[consumerIdString]
-
Consumer owner
/consumers/[groupId]/owners/[topic]/[partitionId] -> consumerIdString + threadId索引编号
3. kafka 中的控制器 controller 的作用
Kafka集群中的其中一个 Broker 会被选举为Controller,主要负责 Partition 管理和副本状态管理(当 partition leader 挂掉时,会从 follower 中选出一个 leader),也会执行类似于重分配 Partition 之类的管理任务。如果当前的 Controller 失败,会从其他正常的 Broker 中重新选举 Controller。
4. kafka consumer 均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡。均衡的最终目的,是提升topic的并发消费能力。
- 假如 topic1 具有如下 partitions: P0,P1,P2,P3
- 假如 group 中有如下 consumer: C0,C1
- 首先根据 partition 索引号对 partitions 排序: P0,P1,P2,P3
- 根据(consumer.id + '-'+ thread序号)排序: C0,C1
- 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值 M = 2 (向上取整)
- 然后依次分配 partitions: C0 = [P0,P1],C1=[P2,P3],即 Ci = [P(i * M),P((i + 1) * M -1)]
5. kafka 数据高可用的原理是什么
一致性定义:若某条消息对Consumer可见,那么即使Leader宕机了,在新Leader上数据依然可以被读到
HighWaterMark简称HW: Partition的高水位,取一个partition对应的ISR中最小的LEO作为HW,消费者最多只能消费到HW所在的位置,另外每个replica都有highWatermark,leader和follower各自负责更新自己的highWatermark状态,highWatermark <= leader. LogEndOffset
对于Leader新写入的msg,Consumer不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被Consumer消费,即Consumer最多只能消费到HW位置
这样就保证了如果Leader Broker失效,该消息仍然可以从新选举的Leader中获取。对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
6. kafka 的数据可靠性保证
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别
- 0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
- 1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
- -1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
仅设置acks=-1也不能保证数据不丢失,当Isr列表中只有Leader时,同样有可能造成数据丢失。要保证数据不丢除了设置acks=-1, 还要保证ISR的大小大于等于2,具体参数设置:
1.request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功;
2.min.insync.replicas: 设置为大于等于2,保证ISR中至少有两个Replica
注意:Producer要在吞吐率和数据可靠性之间做一个权衡
7. kafka partition 分区的策略是什么
消息发送到哪个分区上,有两种基本的策略,一是采用 Key Hash 算法,一是采用 Round Robin 算法。另外创建分区时,最好是 broker 数量的整数倍,这样才能是一个 Topic 的分区均匀的分布在整个 Kafka 集群中。
默认情况下,Kafka 根据传递消息的 key 来进行分区的分配,即 hash(key) % numPartitions。
如果发送消息时没有指定key,那么 Producer 将会把这条消息发送给随机的一个 Partition。但是代码层面的逻辑并不完全是这样。首先看看Kafka有没有缓存的现成的分区Id,如果有的话直接使用这个分区Id。如果没有的话,找出所有可用分区的leader所在的broker,从中随机挑一个并放到缓存中,下次就直接从缓存中拿这个 partition id。注意这个缓存是每隔一段时间就会被清空的。这么做的目的是为了减少服务器端的sockets数。
8. Kafka Producer是如何动态感知Topic分区数变化
问题是,如果在 Kafka Producer 往 Kafka 的 Broker 发送消息的时候用户通过命令修改了改主题的分区数,Kafka Producer 能动态感知吗?答案是可以的。那是立刻就感知吗?不是,是过一定的时间(topic.metadata.refresh.interval.ms参数决定)才知道分区数改变的。
原文链接
9. kafka 的消费方式
10. kafka 如何实现高吞吐量
Spark 集群启动源码
Master 启动
源码不需要特别详细,只需要把大体流程说清楚即可。
Spark 任务提交过程源码
Driver 程序的代码运行到 action 操作,触发了 SparkContext 的 runJob 方法
SparkContext 调用 DAGScheduler 的 runJob 函数,内部调用 DAGScheduler 的 submitJob 方法,返回一个 JobWaiter 对象。接着向 EventProcessLoop 的阻塞队列中 put 一个 JobSubmitted 事件。
这时候 DAGScheduler 的 onReceive 方法被调用,模式匹配,调用 handleJobSubmitted 方法,用来切分 stage。stage 的划分过程是递归调用,从前往后的划分 stage。
根据 final stage 递归找到第一个 stage,然后将第一个 stage 提交。
由于 stage 的类型不同,这里会有两种不同类型的 task,ShuffleMapTask 和 ResultTask。把 task 封装到 taskSet 里,把 Tasks 交给 TaskScheduler。(RPC 调用,向 Executor 提交 task)
Executor 将 task 封装到 TaskRunner 对象中,将 taskRunner 放入到 Executor 中的线程池中。
最后会调用 ShuffleMapTask 或 ResultTask 的 runTask 方法,执行业务逻辑。
spark 任务创建过程
- 客户端执行 spark-submit 脚本,脚本内部会调用 spark-class 脚本,启动 SparkSubmit 类。
- SparkSubmit 类的内部会反射调用我们自己写的类的 main 方法。
- 此时开始创建 SparkContext。
Spark shuffle 过程源码
Spark 部署的三种模式介绍
standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。目前 Spark 在 standalone 模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。
Spark On Mesos模式。这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考Andrew Xia的“Mesos Scheduling Mode on Spark”):
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
Spark On YARN模式。这是一种最有前景的部署模式。但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。这是由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化,不过这个已经在YARN计划(具体参考连接)中了。
spark on yarn 的支持两种模式:
1. yarn-cluster:适用于生产环境;
2. yarn-client:适用于交互、调试,希望立即看到app的输出
yarn-cluster 和 yarn-client 的区别在于 yarn appMaster,每个 yarn app 实例有一个 appMaster 进程,是为 app 启动的第一个 container;负责从 ResourceManager 请求资源,获取到资源后,告诉 NodeManager 为其启动 container。yarn-cluster 和yarn-client 模式内部实现还是有很大的区别。
Spark 常用的 RDD 算子,哪些会产生 shuffle
1. 算子分类
大方向来说,Spark 算子大致可以分为以下两类:Transformation 算子和 Action 算子。
从小方向来说,Spark 算子大致可以分为以下三类:(1) Value 数据类型的 Transformation 算子、(2) Key-Value 数据类型的 Transfromation 算子、(3) Action 算子。
2. 列举
详细请看:Spark 算子分类
会产生 shuffle 的算子
combineByKey、reduceByKey、groupByKey、cogroup、join、leftOutJoin、rightOutJoin
Spark Streaming 和 Storm 的区别
处理模型,延迟
虽然这两个框架都提供可扩展性和容错性,它们根本的区别在于他们的处理模型。而 Storm 处理的是每次传入的一个事件,而 Spark Streaming 是处理某个时间段窗口内的事件流。因此,Storm 处理一个事件可以达到秒内的延迟,而 Spark Streaming 则有几秒钟的延迟。
容错、数据保证
在容错数据保证方面的权衡是,Spark Streaming 提供了更好的支持容错状态计算。在 Storm 中,每个单独的记录当它通过系统时必须被跟踪,所以 Storm 能够至少保证每个记录将被处理一次,但是在从错误中恢复过来时候允许出现重复记录。这意味着可变状态可能不正确地被更新两次。
另一方面,Spark Streaming 只需要在批级别进行跟踪处理,因此可以有效地保证每个 mini-batch 将完全被处理一次,即便一个节点发生故障。(实际上 Storm 的 Trident library 库也提供了完全一次处理。但是,它依赖于事务更新状态,这比较慢,通常必须由用户实现)。
总结
简而言之,如果你需要秒内的延迟,Storm 是一个不错的选择,而且没有数据丢失。如果你需要有状态的计算,而且要完全保证每个事件只被处理一次,Spark Streaming 则更好。Spark Streaming 编程逻辑也可能更容易,因为它类似于批处理程序(Hadoop),特别是在你使用批次(尽管是很小的)时。
Spark SQL 源码执行流程
- SQL 语句经过 SqlParser 解析成 Unresolved LogicalPlan
- 使用 analyzer 结合数据数据字典(catalog)进行绑定,生成 resolved LogicalPlan
- 使用 optimizer 对 resolved LogicalPlan 进行优化,生成 optimized LogicalPlan
- 使用 SparkPlan 将 LogicalPlan 转换成 PhysicalPlan
- 使用 prepareForExecution() 将 PhysicalPlan 转换成可执行物理计划
- 使用 execute() 执行可执行物理计划
- 生成 RDD。
Spark 性能优化方案
cache 和 pesist 的区别
在 spark 中,cache 和 persist 都是用于将一个 RDD 进行缓存的,这样在之后的使用过程中就不需要重新进行计算了,可以大大节省程序运行的时间。
两者的区别在于: cache 其实是调用了 persist 方法,缓存策略为 MEMORY_ONLY。而 persist 可以通过设置参数有多种缓存策略。
两者都能通过 unpersisit 来进行释放。
spark-submit的时候如何引入外部jar包
spark shuffle的具体过程,你知道几种shuffle方式
spark shuffle 有:hash,sort,tungsten-sort。
Spark的Shuffle总体而言就包含两个基本的过程:Shuffle write和Shuffle read。ShuffleMapTask的整个执行过程就是Shuffle write。hash-based机制就是在Shuffle的过程中写数据时不做排序操作,区别于MapReduce。只是将数据根据Hash的结果,将各个Reduce分区的数据写到各自的磁盘文件中。
首先是将map的输出结果送到对于的缓冲区bucket里面,分配bucket的过程同样也是个hash进行分区的过程,在hashed-based下每一个bucket对应一个最终的reducer,在处理完之后bucket里的数据会自动划分到reducer的bucket里面。每个bucket里的文件会被写入本地磁盘文件ShuffleBlockFile中,形成一个FileSegment文件。
Shuffle read指的是reducer对属于自己的FileSegment文件进行fetch操作,这里采用的netty框架,效率明显好于Mapreduce的http传输。fetch操作会等到所有的Shuffle Write过程结束后再进行,这也是因为ShuffleMapTask可能并不在一个stage里面,需要在父stage执行之后提交才会进行子stage的执行。reducer通过fetch得到的FileSegment先放在缓冲区softBuffer中,默认大小48MB。Spark不要求Shuffle后的数据是全局有序的,所以没有必要等到shuffle read全部结束后再进行reduce,是可以并行处理的。