原创者:文思
绪论
为何要学算法?
有个字符串”大中中国 中国我爱 中中国我爱 你中国我爱你中国我爱你好”,怎样判断出”中国我爱你”是否存在,如存在则返回位置。非算法思路则是进行暴力匹配,依次匹配,遇到不匹配的再从字符串开头重新依次匹配,如下:

如果你懂KMP算法,则会很简单。
为何要学数据结构?
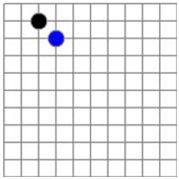
开发五子棋的存盘、续盘功能,如果使用二位数组记录,则像这样:

因为二位数据的很多默认值是0,因为记录了很多无意义的数据,如果优化存储空间就需要稀疏数组。
左图棋盘用二维数据则元素个数是11*11,优化使用稀疏数组则为9*3,对比如下:

二位数组优化为稀疏数组:

这就是数据结构与算法的重要性。不同的数据结构有不同的算法,算法是为数据结构服务的。
数据结构分两种:
线性结构
这是最常用的数据结构,特点是数据元素之间是一对一的线性关系(a[0]=30)。体现为数组、队列、链表、栈等。线性结构有两种不同的存储结构:顺序存储结构、链式存储结构
非线性结构
数据元素之间不是一对一的线性关系。体现为二维数组、广义表、树结构等。
I 线性结构
这是最常用的数据结构,特点是数据元素之间是一对一的线性关系(a[0]=30)。体现为数组、队列、链表、栈等。
线性结构有两种不同的存储结构:顺序存储结构、链式存储结构
顺序存储的线性表称为顺序表,表中的存储元素是连续的(更主要指元素的地址是连续的)。
优点:存储密度大=1,存储空间利用概率高。
链式存储的线性表称为链表,表中存储的元素不一定是联系的,元素节点中存放的是数据元素以及相邻元素的地址信息。
优点:插入或删除元素方便效率高,使用灵活
备注:链式要存储相邻元素地址非常重要,因为如果与相邻元素没有关系就是一个个孤立的元素就无法沟通链式结构了,看到上述加粗字体,应联想到与顺序存储结构在查找、插入效率上的区别,想象其结构图形更能推论出链式在查找上对算法依赖的重要。
想象顺序存储结构:相邻的数据元素,物理存储位置也相邻,依次排列,在顺序表中做插入、删除操作时,平均移动表中的一半元素(要看插入和删除的位置),因此对n较大的顺序表效率低。即插入或删除元素效率不高,适合查找操作。
想象链式存储结构:插入、删除运算应该方便,因为其他元素不用依次位移。但因为数据之前没有依次排列所以存储密度低。即存储空间利用率低,适合插入、删除元素操作,查找效率一般。
总结:数据量小的时候首选顺序存储结构,比如ArrayList,数据量大且插入、删除频繁时选用链式存储结构,比如LinkedList。
一、稀疏数组与队列
当一个数组中大部分元素为同一个值的数组时,可以用稀疏数组来保存。
稀疏数组的处理方法是:
1、记录数组一共有几行几列,有多少个不同的值
2、把具有不同值的元素的行列及值记录在一个小规模的数组中,从而缩小程序的规模
举例:
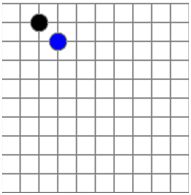
将一个五子棋转换为二位数组:

再用稀疏数组方式进行优化数据结构为:

二位数组转稀疏数在程序过程:
1、遍历原始的二位火速就,得到有效数据的个数(sum)
2、根据有效数据个数创建稀疏数组spareArr int[sum+1][3]
3、将二维数组的有效数据存入到稀疏数组
package com.wensi.sparsearray;
public class SparseArray {
public static void main(String[] args) {
//1创建大小为11*11的原始二位数组
//0标识无棋子,1标识黑子,2标识蓝字
int chessArr[][] = newint[11][11];
chessArr[1][2] = 1;
chessArr[2][3] = 2;
for(int[] row: chessArr){
for(int data: row){
System.out.print(" "+data);
}
System.out.println();
}
//二维数组转稀疏
//创建稀疏数组
int sum = 0;
for(int[] row: chessArr){
for(int data: row){
if(data != 0) {
sum++;
}
}
}
int sparseArr[][] = newint[sum + 1][3];
//给稀疏数组第一行赋值
sparseArr[0][0] = chessArr.length;
sparseArr[0][1] = chessArr[0].length;
sparseArr[0][2] = sum;
//给稀疏数组其它行赋值
int count = 0;//用于记录是第几个非0数据
for(int i = 0;i < chessArr.length;i++) {
for(int j = 0;j< chessArr[i].length;j++) {
if(chessArr[i][j] != 0) {
count++;
sparseArr[count][0] = i;
sparseArr[count][1] = j;
sparseArr[count][2] = chessArr[i][j];
}
}
}
System.out.println("-------转换为稀疏数组为------");
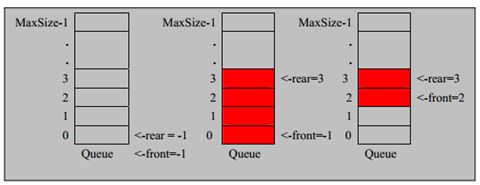
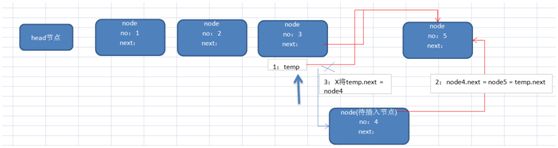
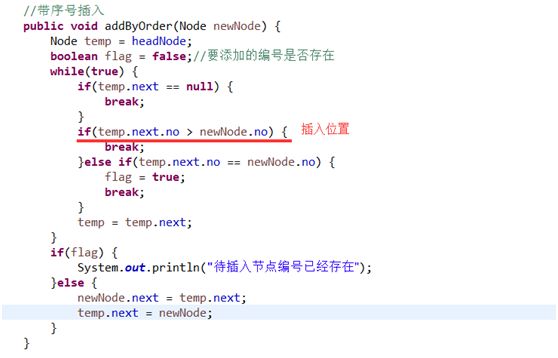
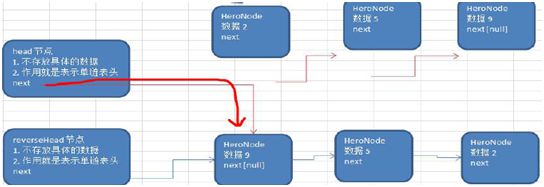
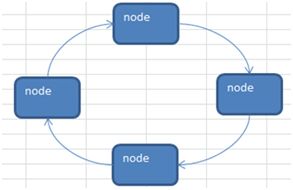
for(int i = 0; i System.out.printf("%d\t%d\t%d\t\n",sparseArr[i][0],sparseArr[i][1],sparseArr[i][2]); } } } 运行结果: 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ----------转换为稀疏数组为--------- 11 11 2 1 2 1 2 3 2 稀疏数组转原始二位数据程序过程: 1、先读取稀疏数组第一行创建二维数组,如上chessArr2 = int[11][11] 2、读取稀疏数组后几行数据,并赋值给二位数据即可。 队列是一个有序列表,可以用数组或是链表来实现。 遵循先入先出的原则 示意图: maxSize 是该队列的最大容量因为队列的输出、输入是分别从前后端来处理,需要两个变量front及rear分别记录队列前后端的下标,front 会随着数据输出而改变,而rear则是随着数据输入而改变。 数组模拟队列的思路分析: 当将数据存入队列时称为”addQueue”,addQueue 的处理需要有两个步骤:将尾指针往后移:rear+1 , 当front == rear【空】。若尾指针rear 小于队列的最大下标maxSize-1,则将数据存入rear所指的数组元素中,否则无法存入数据。rear == maxSize - 1【队列满】 程序: class ArrayQueue{ private int maxSize;//队列容量 private int front;//队列头 private int rear;//队列尾 private int[] arr;//模拟队列的数组 public ArrayQueue(int size){ maxSize = size; arr = new int[maxSize]; front = -1; rear = -1; } //判断队列是否满 public boolean isFull() { return rear == maxSize - 1; } //判断队列是否空 public boolean isEmpty() { return rear == front; } //加入队列 public void addQueue(int n) { if(!isFull()) { rear++; arr[rear] = n; } } //取队列 public int getQueue() { if(!isEmpty()) { front++; return arr[front]; }else { throw new RuntimeException("---队列为空---"); } } } 以上队列只能一次性使用,改进成可循环使用的环形队列(取模方式) 重点考虑取模的应用,比如均衡负载路由中也会用到取模进行路由 思路如下: 1、front队头指针指向队列的第一个元素下标,即数组[front]就是队列的第一个元素 2、rear队尾指针指向队列的最后一个元素下标的后一个位置。 3、队列满时,(rear + 1) % maxSize = fornt时【队列满】 4、rear == front时,【空】 分析如上第3步,假如rear=9,front=0,则(9+1)%10=0,所以当(rear + 1)% maxSize = fornt时,代表队列已满。 5、当队列中有效数据的个数(rear + maxSize - front) % maxSize 第5步是一个小算法,需补充学习。 程序: class CircleArray extends ArrayQueue{ public CircleArray(int size) { super(size); super.front = 0; super.rear = 0; } //重写父类判断队列是否满 public boolean isFull() { return (super.rear + 1) % super.maxSize == super.front; } //重写父类加入队列的方法 public void addQueue(int n) { if(!this.isFull()) { super.arr[super.rear] = n; super.rear = (super.rear + 1) % super.maxSize;//将rear后移,这里必须考虑取模(防止越界) } } //重写父类取队列 public int getQueue() { if(!super.isEmpty()) { //因为front是指向队列的第一个元素,所以 // 1. 先把 front 对应的值保留到一个临时变量 // 2. 将 front 后移, 考虑取模(防止越界) // 3. 将临时保存的变量返回 int value = super.arr[super.front]; super.front = (super.front + 1) % super.maxSize; return value; }else { throw new RuntimeException("---队列为空---"); } } } 二、链表 链表是有序的列表,以节点的方式来存储,每个节点包含data域、next域名(指向下一个节点),链表的各个节点不一定是连续存储。 链表分带头节点链表和没有头节点的链表。链表是学树结构的基础,是有一定的实战威力的。单列表结构图: 链表最后一个节点的next为null。 程序: public classSingleLinkedListDmo { public static void main(String[] args) { Nodenode1= newNode(1,"n1"); Nodenode2= newNode(2,"n2"); Nodenode3= newNode(3,"n3"); SingleLinkedListsingleLinkedist= newSingleLinkedList(); singleLinkedist.add(node1); singleLinkedist.add(node2); singleLinkedist.add(node3); singleLinkedist.show(); } } //链表 class SingleLinkedList{ //初始化头节点 NodeheadNode= newNode(0,""); //添加链表 public void add(Node newNode) { Nodetemp= headNode; while(true) { if(temp.next == null) { break; } temp = temp.next; } temp.next = newNode; } //展示链表 public void show() { Nodetemp= headNode; if(temp.next == null) { System.out.println("这是一个空链表"); return; } while(true) { if(temp == null) {//这里用temp.next会在末尾引发空指针异常 break; } System.out.println(temp); temp = temp.next; } } } //定义表示单链表节点的pojo class Node{ public int no; public String name; public Node next; public Node(int no,String name) { this.no = no; this.name = name; } public String toString() { return "no:"+this.no+",name:"+this.name; } } 运行结果: no:0,name: no:1,name:n1 no:2,name:n2 no:3,name:n3 实现按no排序插入的逻辑: 1、找到要添加的节点位置(位置的前一节点temp) 2、是插入(不是替换),所以新节点.next = temp.next 3、temp.next = 新节点 如图: 程序: //带序号插入 public void addByOrder(Node newNode) { Nodetemp= headNode; boolean flag = false;//要添加的编号是否存在 while(true) { if(temp.next == null) { break; } if(temp.next.no > newNode.no) { break; }else if(temp.next.no == newNode.no) { flag = true; break; } temp = temp.next; } if(flag) { System.out.println("待插入节点编号已经存在"); }else { newNode.next = temp.next; temp.next = newNode; } } 链表反转 思路: 1、定义一个节点reversetNode 2、遍历原来的链表,每取出一个节点及相邻的后节点,将相邻的后节点放到reversetNode链表的最前端 3、head.next = reversetNode.next 程序: public staticvoidreversetList(Node headNode) { if(headNode.next == null || headNode.next.next == null) { return; } NodereversetNode= newNode(0,"");//1 NodecurrentNode= headNode.next; NodenextNode= null; while(currentNode != null) { nextNode = currentNode.next;//记录一下即将要变动的节点后的next currentNode.next = reversetNode.next;//2当前节点的下一节点指向链表最前端(reversetNode.next即为链表的最前端) reversetNode.next = currentNode;//将当前节点连接到新链表上 currentNode = nextNode;//当前节点后移 } headNode.next = reversetNode.next;//3 } } 从尾向头打印链表,且不改变链表结构: 利用栈的原理(后进先出) public staticvoidreversetPrint(Node headNode) { Stackstock= newStack NodecurrentNode= headNode.next; while(currentNode!=null) { stock.push(currentNode); currentNode = currentNode.next; } while(stock.size()>0) { System.out.println("弹栈:"+stock.pop()); } } 双向链表: 单向链表的缺点分析: [if !supportLists]1) [endif]单向链表,查找的方向只能是一个方向,而双向链表可以向前或者向后查找。 [if !supportLists]2) [endif]单向链表不能自我删除,需要靠辅助节点 ,而双向链表,则可以自我删除,所以前面我们单链表删除时节点,总是找到temp,temp是待删除节点的前一个节点(认真体会). 所以双向链表: 遍历\修改:同单向链表 添加: [if !supportLists](1) [endif]先找到双向链表的最后一个节点 [if !supportLists](2) [endif]temp.next = newNode newNode.pre = temp 删除: (1) [endif]因为是双向所以可以自我删除 (2) [endif]找到要删除的节点,比如temp (3) temp.pre.next = temp.next temp.next.pre = temp.pre 代码略。 单向环形链表及约瑟夫问题 顾名思义结构图如下: 约瑟夫问题就是环形单向链表的应用: 约瑟夫问题为,设编号为1,2,… n的n个人围坐一圈,约定编号为k(1<=k<=n)的人从1开始报数,数到m 的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。 思路: 用一个不带头结点的循环链表来处理Josephu 问题:先构成一个有n个结点的单循环链表,然后由k结点起从1开始计数,计到m时,对应结点从链表中删除,然后再从被删除结点的下一个结点又从1开始计数,直到最后一个结点从链表中删除算法结束。 步骤:1、创建和遍历环形单向链表。2、出圈 1、构建和遍历环形单向链表代码: public classJosepfu { public static void main(String[] args) { JosepfuNodeListjosepfuNodeList= newJosepfuNodeList(); josepfuNodeList.add(5); josepfuNodeList.show(); } } class JosepfuNodeList{ private JosepfuNode first; public void add(int num) { JosepfuNodecurrentNode= null; for(int i=1;i<=num;i++) { JosepfuNodenode= newJosepfuNode(i); if(i == 1) { first = node; first.setNext(first); currentNode = first; }else { currentNode.setNext(node); node.setNext(first); currentNode = node; } } } public void show() { JosepfuNodecurrentNode= first; while(true) { System.out.println("编号为:"+currentNode.getNo()); if(currentNode.getNext() == first) { break; } currentNode = currentNode.getNext(); } } } class JosepfuNode{ private int no; private JosepfuNode next; public JosepfuNode(int no) { this.no = no; } public int getNo() { return no; } public void setNo(int no) { this.no = no; } public JosepfuNode getNext() { return next; } public void setNext(JosepfuNode next) { this.next = next; } } 2、出圈:假如有5个人(n=5),从第一个人开始报数(k=1),数两下(m=2),(1)创建一个辅助指针helper并指向链表的最后一个节点.(2)报数前先让first和helper移动k-次.(3)当报数时让first和helper同时移动m-1次.(4)将first指向的节点出圈(first=first.next,helper.next=first时,原来的first指向的节点没有任何引用,就会被回收,即出圈) /** *根据用户的输入,计算出小孩出圈的顺序 *@param startNo表示从第几个小孩开始数数 *@param countNum表示数几下 *@param nums表示最初有多少小孩在圈中 */ public void countBoy(int startNo, intcountNum, int nums) { //先对数据进行校验 if (first == null || startNo <1 || startNo > nums) { System.out.println("参数输入有误, 请重新输入"); return; } //创建要给辅助指针,帮助完成小孩出圈 Boy helper = first; //需求创建一个辅助指针(变量) helper , 事先应该指向环形链表的最后这个节点 while (true) { if (helper.getNext() ==first) {//helper指向最后小孩节点 break; } helper = helper.getNext(); } //小孩报数前,先让 first 和 helper移动 k - 1次 for(int j = 0; j < startNo - 1;j++) { first = first.getNext(); helper = helper.getNext(); } //报数时,让first和helper指针同时的移动m - 1次, 然后出圈 //这里是一个循环操作,知道圈中只有一个节点 while(true) { if(helper == first) { //说明圈中只有一个节点 break; } //让 first 和 helper 指针同时 的移动countNum - 1 for(int j = 0; j first =first.getNext(); helper= helper.getNext(); } //这时first指向的节点,就是要出圈的小孩节点 System.out.printf("小孩%d出圈\n", first.getNo()); //这时将first指向的小孩节点出圈 first = first.getNext(); helper.setNext(first); } System.out.printf("最后留在圈中编号%d \n", first.getNo()); } } 待续…… 待续……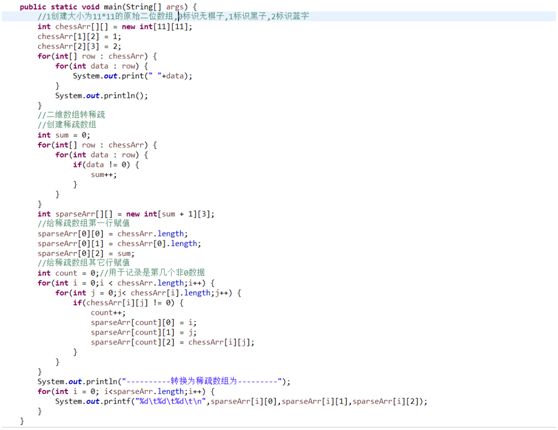
队列







三、栈
II 非线性结构