1 自然语言处理简介
我们从讨论“什么是NLP”开始本章的内容
1.1 NLP有什么特别之处
自然(人工)语言为什么如此特别?自然语言是一个专门用来表达语义的系统,并且它不是由任何形式的物质表现产生。正因为如此,人工语言与视觉或者其他任何机器学习任务非常不同。
大多数单词只是一个超语言实体的符号:单词是映射到一个表征(想法或事物)的记号。例如,“火箭”一词是指火箭的概念,并且进一步可以指定火箭的实例。有一些单词例外,当我们使用单词和字母代表信号时,想“Whooompaa”一样。除此之外,语言符号可以用多种方式进行编码:语音、手势、文章等。他们可以通过连续的信号传递给大脑,而大脑本身似乎以连续的方式对事物进行编码。(关于语言和语言学的哲学的很多工作已经做到了概念化人类语言,并且可以从语言引用和语义识别单词)。
1.2 应用实例
NLP中有不同级别的任务,从语音处理到语义解释和演讲处理。总而言之,NLP的目标就是为了能够设计算法,是计算机能够理解自然语言。下面是不同难度级别的应用实例:
简单
- 拼写检查
- 关键字搜索
- 查找同义词
中等
- 从网站、文档中分析系信息
困难
- 机器翻译(例如将中文翻译成英文)
- 语义分析 (查询语句的含义是什么)
- 代词(在一个文档中,“它”或者“他”具体指代什么)
- 问答系统(例如回答Jeopardy Questions)
1.3 怎么表示单词
贯穿于整个自然语言处理任务中的第一个也是最重要的共同点就是:如何表示单词并作为我们所具有的任意模型的输入。前期大量的NLP工作将单词作为原子符号,但是我们今后将不会重复这个工作,我们首选需要考虑和具备词之间的相似性和差异概念。和词向量一样,我们可以很容易地将这些特征加入到向量之间(采用一些距离措施,如Jaccard,余弦,欧几里得算法等等)。
2 词向量(Word Vectors)
据估计大约有1300万的英文字符,难道它们之间一点联系也没有吗?猫科动物到猫,酒店到汽车旅馆?我不认为它们之间一点关系也没有。因此,我们想将每个单词字符转化为向量,以代表某种单词空间的一个点。这里有很多使用词向量的原因但是最直观的原因就是也许真正存一些足以包含人工语言所有语义的N-维向量空间。每个维度都会编码我们语言传递的含义。例如,语义维度可能表示时态(过去vs现在vs将来),计数(单数vs复数),性别(男性vs女性)。
所以让我们看看第一个词向量并且也可以说是最简单的,one-hot向量。将每个单词表示成IR|V|x1向量,这个词向量就是有很多0和一个1组成(1的位置就是该单词在排序英文出现的索引位置)。在上面的标记中,|V|是词汇的大小。以这种形式编码的词向量看起来如下:
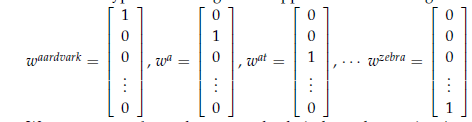
我们可以将每个单词表示成相互独立的实体。就如我们前面所讨论的,单词表示不会直观地给出单词之间的相似性。例如:
所以也许我们可以尝试将这个空间的大小从R |V|减小到更小的东西,从而找到一个编码词之间关系的子空间。
3 基于奇异值分解(SVD)的方法
对于这一类寻找词嵌入(也称作词向量)的方法,首先在一个大型数据集进行循环,并且从某种形式的矩阵X中积累单词共现的次数,然后对矩阵X执行奇异值分解来获得一个USVT.我们然后将U作为我们词典中所有单词的词嵌入(或词向量)。下面讨论下X的一些形式。
3.1 词-文档矩阵(Word-Document Matrix)
作为刚开始的尝试,我们大胆地推测:相关的单词经常出现在同一个文档中。例如,“银行”、“债券”、“股票”、“钱”等等,可能出现在一起。但是“银行”、“章鱼”、“香蕉”和“曲棍球”可能不会一起同时出现在一篇文章中。我们依据这个事实来创建一个词-文档矩阵X,其形成方式如下:遍历几十亿个文档,并且对于每一个单词i只要出现在文档j中,我们就将X自增1。很明显的是,X将会是一个巨大的矩阵(IR|V|xM)同时与文档数量(M)相关。因此我们或许还有改善的地方。
3.2 基于窗口的词共现矩阵(Window based Co-occurnece Matrix)
在这使用同样的逻辑,矩阵X存储了单词的共现次数,这样将会变成一个附属矩阵。在这个方法中,我们计算每个单词在一个特定大小的窗口内出现的次数,进而计算语料库中所有的单词的技术。下面将展示一个实例,我们语料中包含三个句子,窗口大小为1:
- I enjoy flying.
- I like NLP.
-
I like deep learning.
由此产生的计数矩阵将会是:
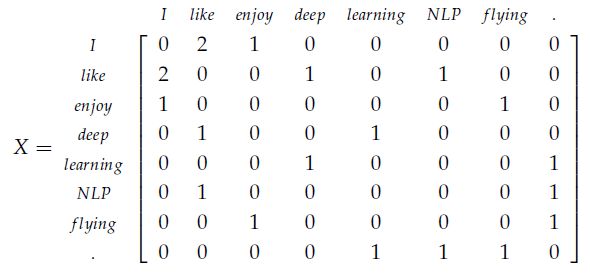
下面解释下结果:
首先要记住窗口(window)大小1。对于矩阵中(I,I)的值为什么为0呢?对于单词I,我们扫描第一个句子,因为I enjoy flying中单词I出现了,I前面为空,后面紧跟单词enjoy,所以(I,I)的值为0;然后扫描第二个句子同样前后没有出现I,这是(I,I)为0;同样扫描第三个句子之后,(I,I)值仍为0。对于(I,like)的值为什么为2呢?扫描第一个句子后,I的前后一个单位没有出现like。对于第2个和第3个句子,I的后面出现了like,所以最后(I,like)的值为2,其他同理。

3.3 对共现矩阵使用奇异值分解
我们在X上执行SVD,观察奇异值(结果矩阵S的对角线数据项),并根据所需要的百分比方差在索引k处进行切割:
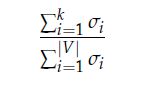
然后我们把这个子矩阵变成我们的单词嵌入矩阵。这样,能够在词汇表中给出每个单词的k维表示方法。
对X应用SVD:
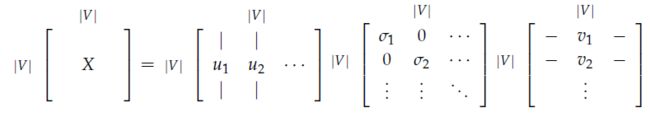
通过选择第一个k维奇异来减少维度:
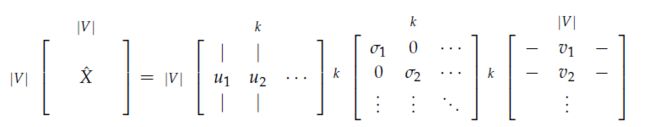
这两种方法能够提供给我们编码足够语义和语法信息的词向量,但是也伴随着很多其他问题:
- 矩阵的维度变化非常频繁(新词添加和语料大小变化非常频繁)
- 大多数单词没有共现,矩阵会非常稀疏
- 通常矩阵维度非常高(约为106x106)
- 训练成本比较高
- 为了形成词频的严重不平衡,需要进行对矩阵X进行“打乱”。
目前已经存在了一些方法来解决上面提到的问题: - 忽略一些功能词汇,例如“the”,“he”,“has”,etc。
- 使用一个不规则窗口-根据文档中单词之间的距离来计算共现次数
- 使用Pearson相关系数和将原始计数设置为负数。
正如我们下一节中提到的,基于迭代的方法以更加优雅的方式解决了许多问题。
4 基于迭代的算法-Word2vec
让我们后退一步尝试新的方法,我们可以尝试创建一个模型,它可以在一段时间内学习一个迭代,并最终能够根据上下文对一个单词的概率进行编码,而不是计算和存储一些巨大的数据集(可能是几十亿个句子)。
这个想法就是设计一个模型,其参数为一个词向量(word vector)。然后,在一定的目标上训练模型。在每次迭代中,我们都运行模型,评估错误,并遵循一个规则,对引起模型错误的参数进行更新替换。因此我们最终学习了单词向量。这是一个可以追溯到1986年的古老思想,我们将其称作“后向传播”。模型和任务越简单,其训练学习的速度就越快。
一些方法已经被测试过。[Collobert et al.,2011]设计了将一些自然语言处理模型,这些模型的第一步就是将每个单词转换为向量。对于每个特殊的任务(命名实体识别、语义标注等),尽管可以计算出很好得单词向量,但是它们除了训练模型的参数同时也训练单词向量,最终显著地提高了模型性能。其他有趣的读物可以阅读[Bengio et al.,2003]。
与此相似,我们将讲述一种更加简单,更加先进,更加可行的方法:word2vec[Mikolov et al.,2003].Word2vec是一个软件包,其包含了以下内容:
- 2个算法:连续词袋(continuous bag-of-words,缩写CBOW)和skip-gram(跨词序列?)。CBOW可以根据一系列词向量中的上下文环境来预测中心词汇。Skip-gram刚好相反,是根据一个中心词汇来预测上下文单词的分布。
- 2个训练方法:负采样(negative sampling)和分级的softmax(hierarchical softmax)。negative sampling通过抽样对立例子来定义一个对象,而hierarchical softmax使用高校的树形结构来定义一个对象,以计算所有词汇的概率。
4.1 语言模型(Unigrams,Bigrams,etc.)
首先,我们需要创建这样一个模型,它将为一个单词序列分配一个概率。以下面的足迹为例:
“The cat jumped over the puddle”
一个好的语言模型将会给这个句子一个很高的概率,因为它在语法和语义上是完全有效的。句子“stock boil fish is toy”出现的概率很低,因为它没有任何意义。在数学上,我们可以计算出包含n个单词的句子的概率:
我们采用一元语言模型(Unigrams)方法,然后假设句子中的单词出现相互独立,那么概率可以写为:
我们知道这种做法看起来很可笑,因为下一个单词的出现会高度依赖于之前的单词序列。并且这种简单句子例子实际上出现的概率会很高。所以,我们尝试使句子出现的概率取决于每个单词和相邻单词组成的单词对的概率。我们将这种方法称为二元语言模型(Bigrams)并表示为:
同样,这个方法看起来也很天真,因为我们仅仅考虑了相邻单词对,而不是评估整体句子。但是我们看到,这种做法使我们更进一步,在一个语义环境下的单词-单词矩阵中,我们基本可以学习这些单词对的概率,但同样,这需要计算和存储大量数据的全局信息。
为了更好地理解如何计算单词序列概率,我们下面将会研究下学些这些概率的序列模型。
4.2 连续词袋模型(Continuous Bag of Words Model ,缩写CBOW)
该方法就是将{“The”,“cat”,“over”,“the”,“puddle”}当做一个上下文(或语义背景),然后根据这些单词,预测并产生中心单词“jumped”,这种模型我们称作为CBOW模型。
补充:
CBOW Model:
从上下文预测中心词
对于每个单词我们需要学习2个向量:
-v: 作为周围单词时的词向量,也称为输入向量
-u:作为中心单词时的词向量,也成为输出向量
CBOW模型中的符号:
• wi: 词汇中的第i个单词
• V ∈Rnn×|V| : 输入词矩阵
• vi: 矩阵V中的第i列,代表单词wi的输入向量
• U∈ R|V|×n : 输出词矩阵
• ui: 矩阵U的第i行, 代表单词wi的输出向量
下面我们更加详细地讨论CBOW模型。首先,我们准备已知参数,使用one-hot向量表示参数。在CBOW中,我们将输入one-hot向量或者上下文记为x(c),输出记为y(c),因为只有一个输出,我们又将其称为y(一个中心词的one-hot向量)。现在我们定义模型中的未知参数。
我们创建两个矩阵,V∈IRn×|V|和U|V|×n.其中n可以使任意大小的,它定义了嵌入空间的大小。V是输入矩阵,当单词wi作为模型的输入时,V的第i列是wi的输入向量,记为vi。同样地,U是输出矩阵,当单词wj作为模型的输出时,U的第j行为单词wi的输出向量,记为uj。注意,我们实际上为每个单词wi学习两个向量(即输入词向量vi和输出词向量ui)。
我们将模型的原理分解下面几个步骤:
-
为大小为m的上下文生成一个one-hot 向量:
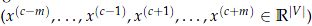
 [参考](http://www.cnblogs.com/Determined22/p/5804455.html)
[参考](http://www.cnblogs.com/Determined22/p/5804455.html) - 计算得出上下文的嵌入词向量:
(vc-m =Vx(c-m), vc-m+1 = Vx(c-m+1), . . ., vc+m = Vx(c+m)∈Rn) -
将上下文的输入词向量求平均值:
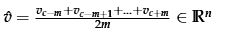
-
计算出一个评分向量:
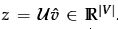
作为两个相似向量的点积越高时,为了获得更高的分数,该公式会将相似的单词放在一块。
-
将评分转化为概率:

-
我们希望产生的概率y-hat能够匹配真实概率,这也恰好适用于one hot向量。
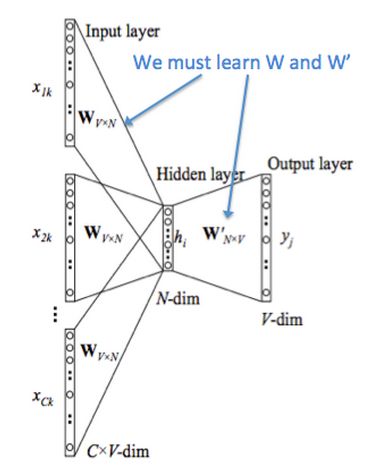 这幅图片解释了CBOW的工作原理
这幅图片解释了CBOW的工作原理
现在当我们拥有一个V和U时我们将会理解CBOW如何工作,将如何学习这两个矩阵?那么我们需要创建一个目标函数。 很多时候,当我们尝试从一些真实概率学习概率时,我们期望使用信息理论给出我们两个分布之间距离的度量。 在这里,我选择使用流行的距离/损耗方法来计算交叉熵H(y-hat,y)。
在离散情况下,可以通过损失函数来计算交叉熵得出:
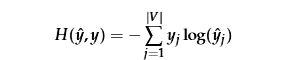
因为y是一个one-hot向量,上面公式可以简写为:
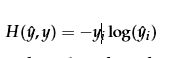
除此之外,使用随机梯度(stochastic gradient)下降优化V和U:
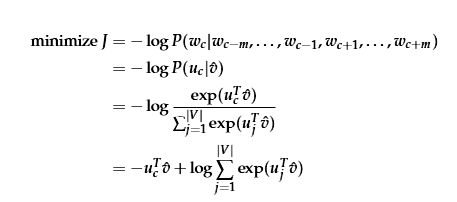
4.3 Skip-Gram 模型
这种方法就是通过给出的中心词“jumped”来创建一个模型,来预测和产生周围词汇(或者中心词的上下文)“The”,“cat”,"over,“the”,“puddle”。这里我们称之为“跳跃”的上下文,将这种类型的模型称为Skip-Gram模型。
下面将详细讨论Skip-Gram。与CBOW相比,初始化时大部分是相同的,只是我们需要将x和y,就是在CBOW中的x现在是y,反之亦然。我将输入one hot向量记为x,输出向量记为y(c),V、U和CBOW模型一样。
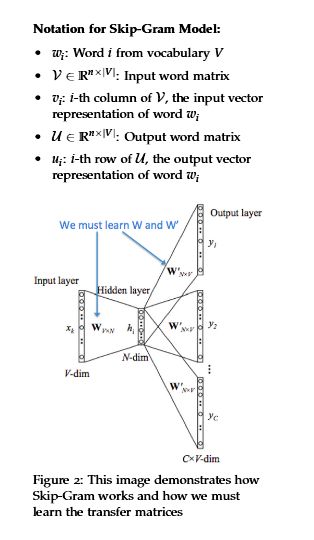
下面是Skip-Gram模型的步骤:
- 将中心词汇转化为one hot向量x∈IR|V|
- 获得中心词汇嵌入词向量vc=Vx∈IRn
- 计算出评分向量z=Uvc
-
将评分向量转化为概率:
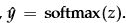
-
用随机梯度下降更新V和U,使预测更加接真实概率
就像在CBOW模型中,我们需要产生一个目标函数来评估模型效果。一个关键不同的地方是,我们需要调用贝叶斯理论来分离概率。在给出中心词条件下,所有的单词都是完全独立的。
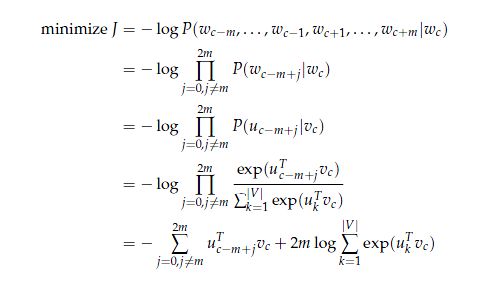
有了这个目标函数,在每次迭代更新后,我们通过随机梯度下降就可以计算未知参数的梯度。
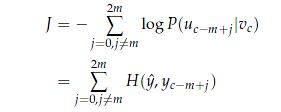
4.4 负采样(Negative Sampling)
其实负采样和分级的softmax对Skip-Gram和CBOW两个优化策略。
我们回头看看目标函数,就会发现|V|的求和在计算上是巨大的。我们更新或者评估目标函数都需要花费O(|V|)百万级的时间。所以一种简单的方法就是近似实现目标函数。
对于每一个训练步骤,我们可以仅仅抽取几个负面例子,而不是遍历整个词汇表。从噪声分布(P(w))中“抽样”,其概率与词汇频率的排序一致,从而增加了我们对问题的描述。我们需要更新以下内容:
- 目标函数(objectiv function)
- 梯度(gradients)
- 更新规则(update rules)
Mikolov在“Distributed Representations of Words and Phrases and their Compositionality”中提出了负采样。尽管负采样是基于Skip-Gram模型,但是事实上,它可以用来优化不同的目标。考虑一组单词(word)和上下(context)(w,c),这组数据是来自我们的训练数据吗?我们将(w,c)来自训练数据的概率记为P(D=1|w,c),相应地,(w,c)不是来自训练数据的概率记为P(D=0|w,c)。首选,使用sigmoid函数建立P(D=1|w,c)的模型:
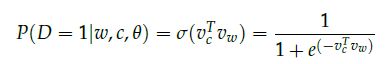
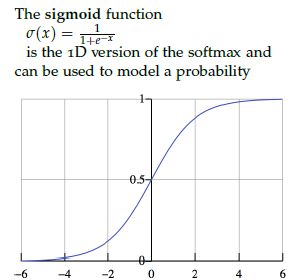
sigmoid函数的图像:
现在,我们建立一个新的目标函数,试图最大化语料库数据中的单词和上下文的概率,如果过词语和上下文刚好在语料库中,我们将词语和上下文在语料库数据中的概率最大化。如果过词语和上下文刚好不在语料库中,我们将词语和上下文不在语料库数据中的概率最大化。 下面是我们所采用这两个概率的简单最大似然法。 (这里我们将q作为模型的参数,在我们的例子中是V和U.)
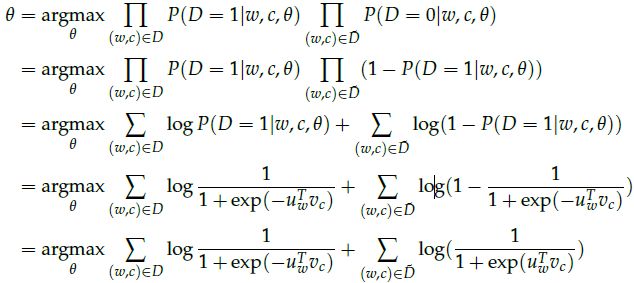
注意,最大化似然性与最小化负对数似然性相同:
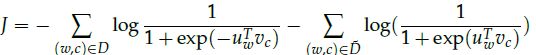
D′是“错误的”或者“负面的”语料库,像“stock boil fish is toy”这种不自然的句子出现的概率会很低,我们可以快速地随机地从词库中生成负语料D′。
-
在给定中心词c和上下文c-m+j,对于Skip-Gram得到的新目标函数:
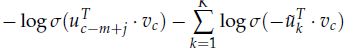
-
对于CBOW模型,得到的新函数为:
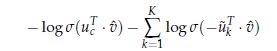
之前的函数:
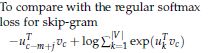
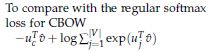
4.5 分层Softmax(Hierarchical Softmax)
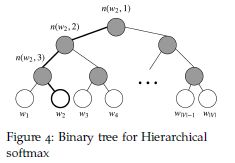
Mikolov还提出将分层softmax替换常规softmax的更有效方案。 在实践中,对于不频繁的单词,分层的softmax效果更好,而负采样对于频繁单词和较低维度向量表现更好。
Hierarchical softmax使用一个二叉树来表示词汇表中的所有单词,树的每一个叶节点是一个单词,并且从根节点到叶节点的路径是唯一的。在模型汇没有单词的输出表示,相反,图中的每个节点(除了根节点和叶节点)都是与一个模型学习的向量有关系。
在方法中,在给出单词w的词向量w i后,则单词w的概率为P(w|w i.),等于从根节点随机游走到相应的叶节点W的概率。这种计算概率的方法主要优势就是时间复杂度降低到O(log(|V|)).
符号与标记:
- L(w):指从根节点到叶节点w的路径上的节点个数
比如在Firgure 4中,L(w2)为3 - n(w,i)是指与向量vn(w,i)相关的节点,其中n(w,1)是根节点。
- n(w,L(w))是指w的父节点。
- ch(n)节点n的子节点(例如总是左节点)
那么概率计算公式为:
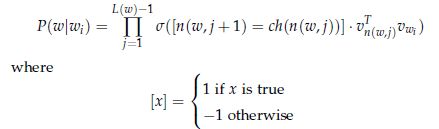
其中σ(▪)是sigmoid函数。
下面解释下公式:
我们假设ch(n)总算是节点n的左孩子,那么当路径向左时,[n(w,j+1)=ch(n(w,j))]返回1;当路径向右时,[n(w,j+1)=ch(n(w,j))]返回-1.
以Firgure4中的w 2为例,从根节点到w 2节点我们必须经过两次左边和一个右边,那么
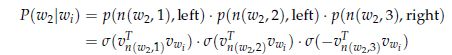
在此模型中,我们的目标仍然是最小化负对数似然P(w|w i)。但是,我们没有更新每个单词的输出向量,而是更新了从根到叶节点的二叉树中的节点的向量。该方法的速度取决于构造二叉树的方法和将单词分配给叶节点的方法,Mikolov使用二叉霍夫曼树来分配频繁词汇的最短路径。
文章推荐
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
- [Lecture Notes 1]
- Softmax 函数及其作用(含推导)