严格的线性回归
之前我们讲过线性回归:在向量空间里用线性函数去拟合样本。
该模型以所有样本实际位置到该线性函数的综合距离为损失,通过最小化损失来求取线性函数的参数。参见下图:
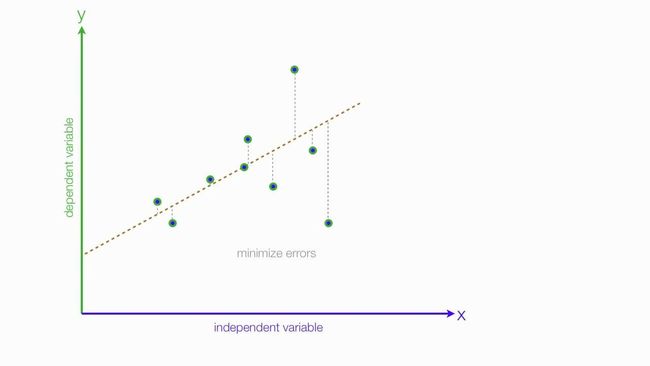
对于线性回归而言,一个样本只要不是正好落在最终作为模型的线性函数上,就要被计算损失。
如此严格,真的有利于得出可扩展性良好的模型吗?
宽容的支持向量回归(SVR)
今天我们来介绍一种“宽容的”回归模型:支持向量回归(Support Vector Regression,SVR)。
模型函数
支持向量回归模型的模型函数也是一个线性函数: y = wx + b。
看起来和线性回归的模型函数一样!
但 SVR 和线性回归,却是两个不同的回归模型。
不同在哪儿呢?不同在学习过程。
说得更详细点,就是:计算损失的原则不同,目标函数和最优化算法也不同。
原理
SVR 在线性函数两侧制造了一个“间隔带”,对于所有落入到间隔带内的样本,都不计算损失;只有间隔带之外的,才计入损失函数。之后再通过最小化间隔带的宽度与总损失来最优化模型。
如下图这样,只有那些圈了红圈的样本(或在隔离带边缘之外,或落在隔离带边缘上),才被计入最后的损失:

SVR 的两个松弛变量
这样看起来,是不是 SVR 很像 SVM?
不过请注意,有一点 SVR 和 SVM 正相反,那就是:SVR 巴不得所有的样本点都落在“隔离带”里面,而 SVM 则恰恰希望所有的样本点都在“隔离带”之外!
正是这一点区别,导致 SVR 要同时引入两个而不是一个松弛变量。
SVR 引入两个松弛变量:ξ 和 ξ∗

上图显示了 SVR 的基本情况:
f(x)=wx+b 是我们最终要求得的模型函数;
wx+b+ϵ 和 wx+b–ϵ(也就是 f(x)+ϵ 和 f(x)−ϵ)是隔离带的上下边缘;
ξ 是隔离带上边缘之上样本点的 y 值,与对应 x 坐标在“上边缘超平面”上投影的差;
而 ξ∗ 则是隔离带下边缘之下样本点,到隔离带下边缘上的投影,与该样本点 y 值的差。
这样说有些绕,我们用公式来表达:
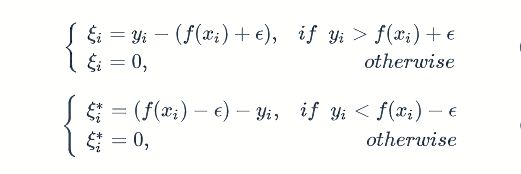
对于任意样本 xi,如果它在隔离带里面或者隔离带边缘上,则 ξi 和 ξ∗i 都为0; 如果它在隔离带上边缘上方,则 ξi>0,ξ∗i=0;如果它在下边缘下方,则 ξi=0,ξ∗i>0。
SVR 的主问题和对偶问题
SVR 的主问题
SVR 主问题的数学描述如下:
minw,b,ξ,ξ∗12||w||2+C∑mi=1(ξi+ξ∗i)
s.t.f(xi)−yi⩽ϵ+ξi;yi−f(xi)⩽ϵ+ξ∗i;ξi⩾0;ξ∗i⩾0,i=1,2,...,m.
SVR 的拉格朗日函数和对偶问题
我们引入拉格朗日乘子 μi⩾0,μ∗i⩾0,αi⩾0 和 α∗i⩾0,来针对上述主问题构建拉格朗日函数,得到拉格朗日函数如下:
L(w,b,ξ,ξ∗,α,α∗,μ,μ∗)=12||w||2+C∑mi=1(ξi+ξ∗i)+∑mi=1αi(f(xi)−yi−ϵ−ξi)+∑mi=1α∗i(yi−f(xi)−ϵ−ξ∗i)+∑mi=1μi(0−ξi)+∑mi=1μ∗i(0−ξ∗i)
它对应的对偶问题是:
maxα,α∗,μ,μ∗minw,b,ξ,ξ∗L(w,b,ξ,ξ∗,α,α∗,μ,μ∗)
求解 SVR 对偶问题
按照我们前面学习过的方法,首先要求最小化部分:
minw,b,ξ,ξ∗L(w,b,ξ,ξ∗,α,α∗,μ,μ∗)
分别对 w、b、ξi和ξ∗i 求偏导,并令偏导为0,可得:
w=∑mi=1(α∗i−αi)xi,
0=∑mi=1(α∗i−αi),
C=αi+μi,
C=α∗i+μ∗i.
将上述4个等式带回到对偶问题中,在通过求负将极大化问题转化为极小化问题,得到如下结果:
minα,α∗[∑mi=1yi(αi−α∗i)+ϵ∑mi=1(αi+α∗i)+12∑mi=1∑mj=1(αi−α∗i)(αj−α∗j)xTixj]
s.t.∑mi=1(α∗i−αi)=0;0⩽αi,α∗i⩽C.
用 SMO 算法求解 SVR
到了这一步我们可以采用 SMO 算法了吗?
直觉上,好像不行。因为 SMO 算法针对的是任意样本 xi 只对应一个参数 αi 的情况,而此处,这个样本却对应两个参数 αi和α∗i。
有没有办法把 αi 和 α∗i 转化为一个参数呢?办法还是有的!
我们整个求解过程采用的是拉格朗日对偶法,对偶问题有解的充要条件是满足 KKT 条件。
那么对于 SVR 的对偶问题,它的 KKT 条件是什么呢?它的 KKT 条件如下:
αi(f(xi)−yi−ϵ−ξi)=0,
α∗i(yi−f(xi)−ϵ−ξ∗i)=0,
αiα∗i=0,
ξiξ∗i=0,
(C−αi)ξi=0,
(C−α∗i)ξ∗i=0.
由 KKT 条件可见,当且仅当 f(xi)−yi−ϵ−ξi=0 时,αi 才可以取非0值;当且仅当 yi−f(xi)−ϵ−ξ∗i=0 时,α∗i 才可以取非0值。
f(xi)−yi−ϵ−ξi=0=>yi=f(xi)−ϵ−ξi 对应的是在隔离带下边缘以下的样本。
而 yi−f(xi)−ϵ−ξ∗i=0=>yi=f(xi)+ϵ+ξ∗i 对应的是在隔离带上边缘之上的样本。
一个样本不可能同时既在上边缘之上,又在上边缘之下,所以这两个等式最多只有一个成立,相应的 αi 和 α∗i 中至少有一个为0。
我们设:λi=αi–α∗i。
既然 αi 和 α∗i 中至少有一个为0,且 0⩽αi,α∗i,⩽C (参见上节“求解 SVR 对偶问题”结尾),于是有 : |λi|=αi+α∗i。
将 λi 和 |λi| 带入对偶问题,则有:
minλ[∑mi=1yi(λi)+ϵΣmi=1(|λi|)+12∑mi=1∑mj=1λiλjxTixj]
s.t.∑mi=1(λi)=0;−C⩽λi⩽C.
如此一来,不就可以应用 SMO 求解了嘛!
当然,这样一个推导过程仅仅用于说明 SMO 也可以应用于 SVR,具体的求解过程和 SVM 的 SMO 算法还是有所差异的。
支持向量与求解线性模型参数
因为 f(x)=wx+b,又因为前面已经求出 w=∑mi=1(α∗i−αi)xi,因此:
f(x)=∑mi=1(α∗i−αi)xTix+b
由此可见,只有满足 α∗i−αi≠0 的样本才对 w 取值有意义,才是 SVR 的支持向量。
也就是说,只有当样本满足下列两个条件之一时,它才是支持向量:
f(xi)−yi−ϵ−ξi=0
或
yi−f(xi)−ϵ−ξ∗i=0
换言之,这个样本要么在隔离带上边缘以上,要么在隔离带下边缘以下(含两个边缘本身)。
也就是说,落在 ϵ-隔离带之外的样本,才是 SVR 的支持向量!
可见,无论是 SVM 还是 SVR,它们的解都仅限于支持向量,即只是全部训练样本的一部分。因此 SVM 和 SVR 的解都具有稀疏性。
通过最优化方法求解出了 w 之后,我们还需要求 b。
f(xi)=wxi+b=>b=f(xi)–wxi
而且,对于那些落在隔离带上边缘上的支持向量,有 f(xi)=yi+ϵ,落在隔离带下边缘上的支持变量有 f(xi)=yi−ϵ。
因此,b=1|Su|+|Sd|[∑s∈Su(ys+ϵ−wxs)+∑s∈Sd(ys−ϵ−wxs)]
其中 Su 是位于隔离带上边缘的支持向量集合,而 Sd 则是位于隔离带下边缘的支持向量集合。
SVR 的核技巧
前面讲到的适用于 SVM 的核技巧也同样适用于 SVR。
SVR 核技巧的实施办法和 SVM 一样,也是将输入空间的 x 通过映射函数 ϕ(x) 映射到更高维度的特征空间。然后再在特征空间内做本文前面所述的一系列操作。
因此,在特征空间中的线性模型为:
f(x)=wϕ(x)+b
其中:
w=∑mi=1(α∗i−αi)ϕ(xi)
对照 SVM 核函数的做法,我们也令:
k(xi,xj)=ϕ(xi)Tϕ(xj)
**则: **
f(x)=∑mi=1(α∗i−αi)k(x,xi)+b
具体核技巧的实施过程,也对照 SVM 即可。