
我们已经学习 urllib、re、BeautifulSoup 这三个库的用法。但只是停留在理论层面上,还需实践来检验学习成果。因此,本文主要讲解如何利用我们刚才的几个库去实战。
1 确定爬取目标
任何网站皆可爬取,就看你要不要爬取而已。本次选取的爬取目标是当当网,爬取内容是 以 Python 为关键字搜索出来的页面中所有书籍的信息。具体如下图所示:
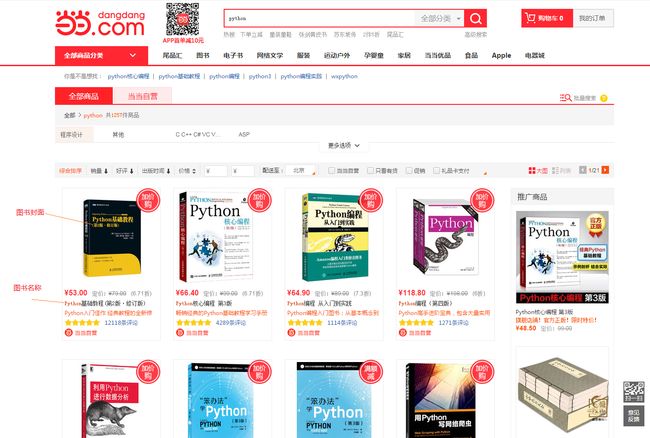
本次爬取结果有三项:
- 图书的封面图片
- 图书的书名
- 图书的链接页面
最后把这三项内容保存到 csv 文件中。
2 爬取过程
总所周知,每个站点的页面 DOM 树是不一样的。所以我们需要先对爬取页面进行分析,再确定自己要获取的内容,再定义程序爬取内容的规则。
2.1 确定 URL 地址
我们可以通过利用浏览器来确定URL 地址,为 urllib 发起请求提供入口地址。接下来,我们就一步步来确定请求地址。
搜索结果页面为 1 时,URL 地址如下:

搜索结果页面为 3 时,URL 地址如下:

搜索结果页面为 21 时,即最后一页,URL 地址如下:

从上面的图片中,我们发现 URL 地址的差异就在于 page_index 的值,所以 URL 地址最终为 http://search.dangdang.com/?key=python&act=input&show=big&page_index=。而 page_index 的值,我们可以通过循环依次在地址后面添加。因此, urllib 请求代码可以这样写:
# 爬取地址, 当当所有 Python 的书籍, 一共是 21 页
url = "http://search.dangdang.com/?key=python&act=input&show=big&page_index="
index = 1
while index <= 21:
# 发起请求
request = urllib.request.Request(url=url+str(index), headers=headers)
response = urllib.request.urlopen(request)
index = index + 1
# 解析爬取内容
parseContent(response)
time.sleep(1) # 休眠1秒
2.2 确定爬取节点
有了 URL 地址,就能使用 urllib 获取到页面的 html 内容。到了这步,我们就需要找到爬取的节点的规则,以便于 BeautifulSoup 地解析。为了搞定这个问题,就要祭出大招 —— Chrome 浏览器的开发者功能(按下 F12 键就能启动)。我们按下 F12 键盘,依次对每本书进行元素检查(在页面使用鼠标右键,点击“检查”即可),具体结果如下:
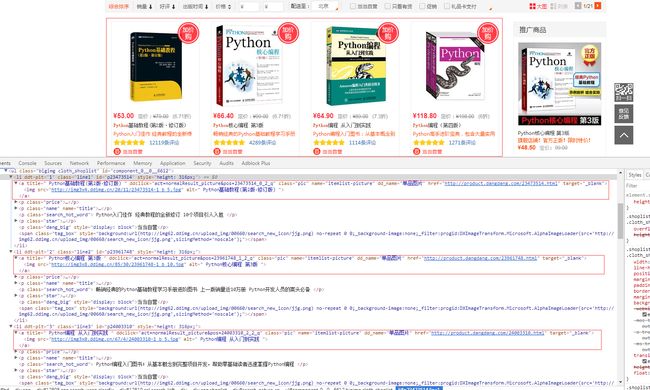
从上图可以得知解析规则:每本书的节点是一个 a 标签,a 标签具有 title,href,子标签 img 的 src 三个属性,这三者分别对应书名、书的链接页面、书的封图。看到这里也需你不会小激动,感叹这不就是我们要感兴趣的内容吗?得到解析规则,编写BeautifulSoup 解析代码就有了思路,具体代码如下:
# 提取爬取内容中的 a 标签, 例如:
#
#
#  #
soup = BeautifulSoup(response)
books = soup.find_all('a', class_='pic')
print(books)
#
soup = BeautifulSoup(response)
books = soup.find_all('a', class_='pic')
print(books)
运行结果如下:
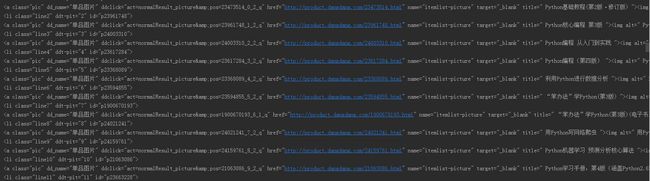
这证明刚才制定规则是正确爬取我们所需的内容。
2.3 保存爬取信息
我写爬虫程序有个习惯,就是每次都会爬取内容持久化到文件中。这样方便以后查看使用。如果爬取数据量比较大,我们可以用其做数据分析。我这里为了方便,就将数据保存到 csv 文件中。用 Python 将数据写到文件中,我们经常中文乱码问题所烦恼。如果单纯使用 csv 库,可能摆脱不了这烦恼。所以我们将 csv 和 codecs 结合一起使用。在写数据到 csv 文件的时候,我们可以通过指定文件编码。这样中文乱码问题就迎刃而解。具体代码如下:
fileName = 'PythonBook.csv'
# 指定编码为 utf-8, 避免写 csv 文件出现中文乱码
with codecs.open(fileName, 'w', 'utf-8') as csvfile:
filednames = ['书名', '页面地址', '图片地址']
writer = csv.DictWriter(csvfile, fieldnames=filednames)
writer.writeheader()
for book in books:
# print(book)
# print(book.attrs)
# 获取子节点![]() # (book.children)[0]
if len(list(book.children)[0].attrs) == 3:
img = list(book.children)[0].attrs['data-original']
else:
img = list(book.children)[0].attrs['src']
writer.writerow({'书名': book.attrs['title'], '页面地址': book.attrs['href'], '图片地址': img})
# (book.children)[0]
if len(list(book.children)[0].attrs) == 3:
img = list(book.children)[0].attrs['data-original']
else:
img = list(book.children)[0].attrs['src']
writer.writerow({'书名': book.attrs['title'], '页面地址': book.attrs['href'], '图片地址': img})
看到这里,你可能会问为什么不把编码指定为 gb2312 呢,这样用 ecxel 打开就不会乱码了?原因是当书名全部为英文单词时,使用 gb2312 编码,writer.writerow()会出现编码错误的问题。
如果你要用 excel 打开 PythonBook.csv文件, 你则需多执行下面几步:
-
- 打开 Excel
-
- 执行“数据”->“自文本”
-
- 选择 CSV 文件,出现文本导入向导
-
- 选择“分隔符号”,下一步
-
- 勾选“逗号”,去掉“ Tab 键”,下一步,完成
- 6)在“导入数据”对话框里,直接点确定
3 爬取结果
最后,我们将上面代码整合起来即可。这里就不把代码贴出来了,具体阅读原文即可查看源代码。我就把爬取结果截下图:
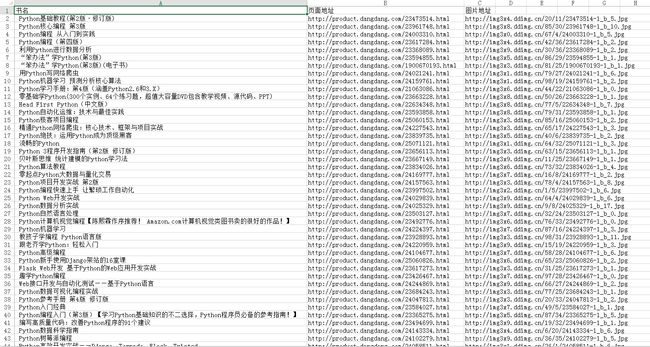
4 写在最后
这次实战算是结束了,但是我们不能简单地满足,看下程序是否有优化的地方。我把该程序不足的地方写出来。
- 该程序是单线程,没有使用多线程,执行效率不够高。
- 没有应用面向对象编程思想,程序的可扩展性不高。
- 没有使用随机 User-Agent 和 代理,容易被封 IP。
附:源代码地址
上篇文章:内容提取神器 beautiful Soup 的用法
推荐阅读:Python 正则表达式