一 集群节点
Elstaicsearch的集群是由多个节点组成都,通过cluster.name设置集权名称,比能切用与区分其他的集群,每个节点通过node.name指定节点
在Elasticsearch中,接待你的类型主要有4种
1.1 master节点
配置文件中的node.master属性为true(默认是true),就有资格被选为master节点
master节点用于控制整个集群的操作,比如创建或删除索引,管理其他非master节点等
[root@node1 ~]# curl http://192.168.132.131:9200/_cat/master
9qVjdVSvSAGlZ7lpB9O78g 192.168.132.132 192.168.132.132 node-2
1.2 data节点
配置文件中的node.data,属性为true(默认是true),就有资格被选为data节点
data节点主要用域执行数据相关的操作,比如文档的CRUD
[root@node1 ~]# curl -XGET http://127.0.0.1:9200/_cat/nodes?pretty
192.168.132.133 32 95 0 0.00 0.01 0.05 dilm - node-3 192.168.132.131 35 80 0 0.00 0.01 0.05 dilm - node-1 192.168.132.132 29 96 0 0.00 0.01 0.05 dilm * node-2
1.3客户端节点
配置文件中的node.master和node.data属均为false
该节点不能作为master节点,也不能作为data节点
可以作为客户端节点,用于相应用户的请求,把请求转发到其他节点
1.4 部落节点
当一个节点配置为tribe.*的时候,他就是一个特殊的客户端,它可以连接多个集群,在所有连接的集权上执行搜索和其他操作
二 集群的配置属性
设置两个参数
[root@node1 ~]# grep -Ev "^$|[#;]" /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-elktest-cluster node.name: node-1 network.host: 0.0.0.0 http.port: 9200 discovery.seed_hosts: ["192.168.132.131","192.168.132.132","192.168.132.133"] gateway.recover_after_nodes: 2 #这个参数目的是,当集群需要重启的时候,有两个机器开启,才开始进行数据的平衡 discovery.zen.minimum_master_nodes: 2 #这表示至少两个节点同意某一个节点成为master,节点才会成为master cluster.initial_master_nodes: ["node-1","node-2","node-3"] http.cors.enabled: true http.cors.allow-origin: "*"
gateway.recover_after_nodes
2.1 集群恢复设置
在向外扩展至多节点集群之后,可能会发现偶尔需要重新启动整个集群。需要重新启动整个集群时,必须考虑恢复设置。如果集群包含 10 个节点,每次启动集群的一个节点时,主节点会假定需要在每个节点到达集群后立即开始均衡数据。如果允许主节点如此操作,那么需要进行大量不必要的重新均衡。必须将集群设置配置为等到某一最少数量的节点加入集群后才允许主节点开始指示节点进行重新均衡。这样可将集群重新启动从数小时缩短至几分钟。
gateway.recover_after_nodes 属性必须设置为首选项,以防止 Elasticsearch 在集群中指定数量的节点启动并连接之前开始重新均衡。如果集群具有 10 个节点,那么 gateway.recover_after_nodes 属性值为 8 可能是合理设置。
discovery.zen.minimum_master_nodes
2.2 属性设置
这表示至少两个节点同意某一个节点成为master,节点才会成为master,属性必须设置为 ceil((<集群中的主合格节点数> / 2) + 1),以避免脑裂。
- 集群中属于主合格节点的 Elasticsearch 节点必须确立定额,以确定哪个主合格节点为主节点。
- 如果将主合格节点添加到集群中,那么主合格节点数量会发生改变,因此设置必须更改。如果将新的主合格节点引入集群,必须修改配置。
2.3 不要对集群做一下操作
- 请勿忽略生产集群。
- 集群需要监控和培养。针对此任务有许多有效的专属 Elasticsearch 监控工具。
- 请勿对 datapath 设置使用网络连接存储器 (NAS)。NAS 造成更长时间的延迟,并且会产生单一故障点。始终使用本地主机磁盘。
- 避免集群跨多个数据中心,务必避免集群的地域距离跨度过大。节点之间的延迟是严重的性能瓶颈。
- 实施您自己的集群配置管理解决方案。有许多有效的配置管理解决方案可用,例如,Puppet、Chef 和 Ansible。
三 集群的分片和副本
3.1 重新创建一个索引

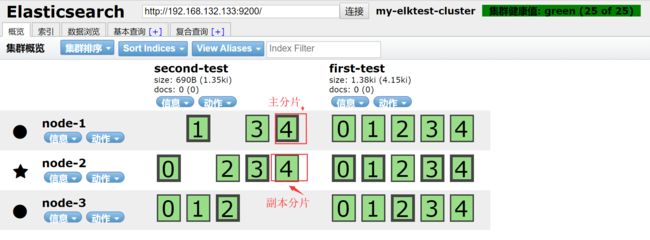
3.2 集群状态的三种颜色
| 颜色 | 意义 |
| green | 所有的主要分片和复制分片都可用 |
| yello | 所有主分片可用,但不是所有的副分片都可用 |
| red | 不是所有的主分片都可用 |
3.3 分片和副本介绍
为了将数据添加到Elasticsearch,我们需要将索引(index)--一个存储相关联数据的地方。实际上,索引只是一个用来指向一个或者多个分片(shards)的逻辑命令空间(logic namespace)
- 一个分片是一个最小级别的工作单元(worker unit),他只是保存了索引中数据的部分
- 我们需要知道是分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎,引用程序不会和他直接通信
- 分片可以是主分片(primary shard)或者是复制分片(replica shard)
- 索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多存储多少数据
- 复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档
- 当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调正
3.4 故障转移
关于实验及效果,请参考上一章实验,下面做几点说明
在一个节点宕机之后,集群状态会变为黄色,表示主节点可用,但是副本节点不完全可用
过一段时间观察,发现节点列表中看不到宕机的节点,副本分配到了其他两个节点,集群会恢复到绿色
将宕机节点开启后,会重新加入集群,并且重新分配了节点信息
主节点宕机
将node-1关闭服务,模拟宕机状态
集群会对master进行了重新的选择,选择node-2未知节点,并且集群状态变更成黄色
等待一段时间后,集群会从黄色状态恢复为绿色状态
恢复node1节点,发现node-1可以加入到集群中,集群状态依然为绿色
四 对于文档的操作
4.1 分布式文档

如图所示:当我们想要一个集群保存文档时,文档该存到那个节点,是随机的,还是轮询的
实际上,在Elasticsearch中,会采用i计算的方式来确定存到哪一个节点上,计算公式如下
shard = hash(routing)%number_of_primary_shards
routing的值是一个任意字符串,它默认的时_id但是也可以定义
这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量会得到一个余数(remainder),余数的范围永远是0到number_of_promary_shards -1,这个数字就是特定文档的分片
这就是为什么创佳主分片后,不能修改的原因
4.2 文档的写操作
新建索引和删除请求都是写操作,他必须在主分片上成功完成才能复制到相关的复制分片上
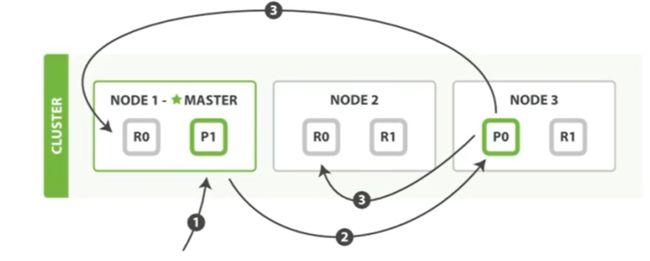
下面罗列在分片和复制分片生成功新建索引或删除一个文档的必要顺序步骤
- 客户端个node1发送新建索引或删除的请求
- 节点使用文档的_id确定文档属于分片0,它传达转发请求到node3,分片0位于这个节点上
- node3在主分片上执行请求,如果成功,它转发请求到相应的位于node1和node2的复制节点上,当所有的复制节点报告成功,node3报告成功请求的节点上,请求的节点在报告给客户端
- 客户端接收到成功相应的时候,文档的修改已经被应用于主分片和所有的复制分片,你的修改已经成功了
4.3 搜索文档
文档能够从主分片或者任意一个复制分片被检索

下面我们罗列在主分片或者复制分片上检索一个文档必要的顺序
- 客户端给node1 发送get请求
- 节点使用文档的_id确定文档属于分片0,分片0对应的复制分片在三个节点上都有,此时,它转发请求到node2
- node2返回文档给node1,然后返回给客户端
- 对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片,他会循环所有的分片副本
可能的情况是,一个索引的文档已经存在于主分片上,却还没来得及同步到复制分片上,这是复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给给客户,文档则在主分片和复制分片都是可用的
4.4 全文搜索
对于全文搜索而言, 文档可能分布在各个节点上,那么在分布式的情况下,如何搜索文档呢
搜索分为两个阶段,搜索(query)+取回(fetch)
搜索
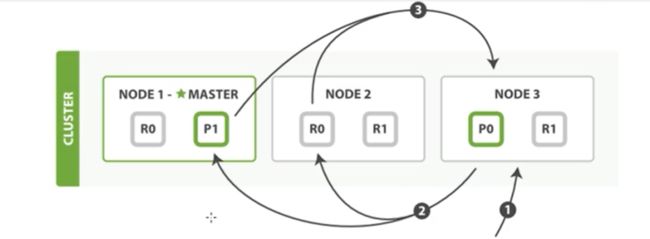
查询阶段
- 客户端发送一个search请求给node3,node3建立一个长度为from+size的空优先级队列
- node3转发这个请求到索引中每个分片的原本或者副本,每个分片在本地执行这个查询并且将这个结果到一个大小为from+size的有序本地优先队列里去
- 每个分片返回document的ID和它优先队列里的所有文档的排序值给协调节点node3.node3把这些值合并到自己的优先队列里产生全局排序结果
取回
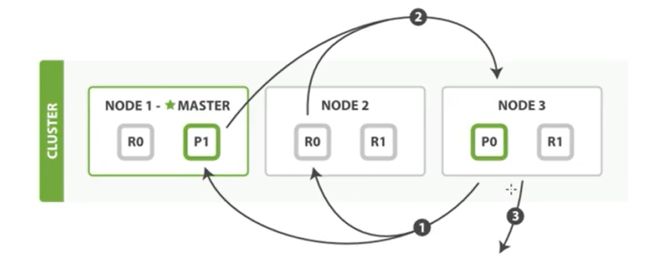
取回步骤
- 协调节点分辨好处哪个文档需要取回,并且向相关的分片发出GET请求
- 每个分片加载文档并且根据需要fentch他们,然后再将文档返回给协调点
- 一旦所有的文档被取回,协调节点会将结果返回给客户端
以上就是关于集群的一些皆不能概念和介绍