移动直播的兴起使得在移动端观看直播的需求日渐增多,相交于点播而言,直播提出了一个新的要求——实时性,也即要求主播端至观众端的总延时不能过高。而已有的移动端视频播放器如: 系统播放器、VLC和ijkplayer等开源播放器均是为了点播视频播放而设计,虽能播放直播视频,但是不能降低直播端至终端的延时。
针对以上问题,有必要以播放器为核心实现降低直播延时的功能。
一. 什么是直播延迟
移动直播的基本架构图如下所示:
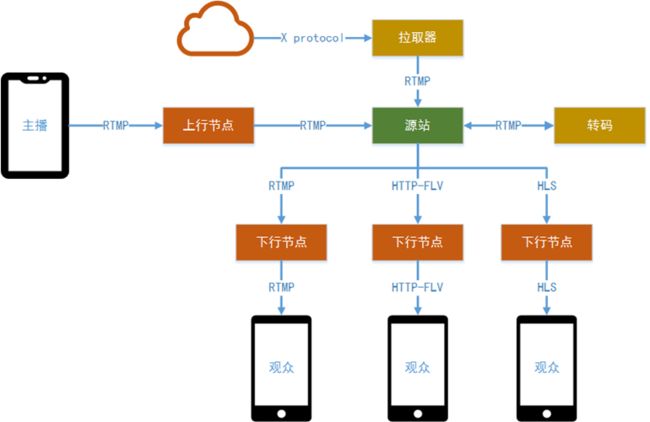
移动直播整体架构大致可分为五个部分:
- 主播端。主要负责音视频数据的采集、预览、处理(美声、美颜、滤镜等)、编码及将编码后的数据推送至源站(可能经过上行加速节点)。
- 源站。该部分属于云服务的一项功能,接收来自主播端的音视频数据,当来自CDN网络(下行节点)的数据拉取请求时,按照对应的格式返回给CDN。同时也担负将直播音视频数据落盘,生成点播回看视频。
- 转码。可以从源站拉取一路流,转码成多种分辨率、码率,再回推给源站。这样实现了一路主播视频流的推送,制造出码率不同的多路流。拉取器是转码的一种变种,它从其他源处拉取数据流(使用某种约定好的拉流协议),并remux成rtmp推送给源站。
- CDN。上下行节点都归为数据分发网络。该部分属于云服务的一项功能,多层下行节点从源站获取直播音视频数据,然后将数据分发给各地观众。
- 观众端。从下行节点获取直播数据,解析、解码并渲染音视频,以供观众观看。
如果一帧画面在主播侧被采集时刻为t0,某观众屏幕上展示出这帧画面的时候为t1,那么该观众能感知的延时为t1-t0。这个延时,我们叫直播延时。
主播端从摄像头、麦克风采集音视频数据,在移动端处理编码后,经由源站、CDN直至观众端解码并渲染播放整个链路引入的延时,直播延时涵盖了整个链路的完整延时。
二. 直播链路各模块对延时的"贡献"
直播延时大致可分为两个部分:
- 音视频数据在直播网络链路传输所引入的延时,此部分无法避免;
- 直播链路各模块对音视频数据的
cache、process操作引入的延时,则可以采用一定方法降低甚至消除;
下面将分析各模块对于直播延时的"贡献":
2.1 主播端
主播端在采集音视频数据后基本流程如下所示:
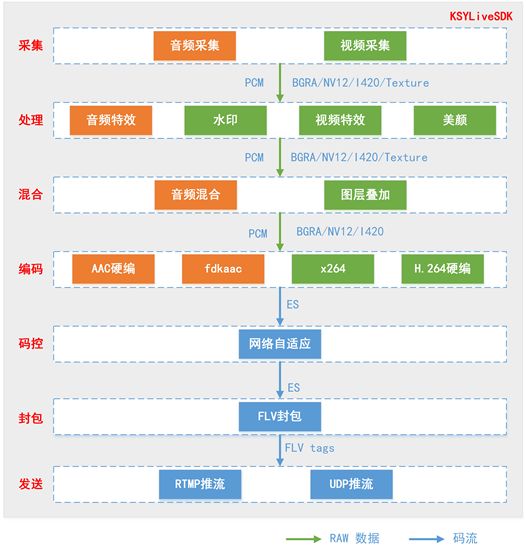
- 采集。首先使用麦克风采集音频,使用摄像头采集画面。在此时,打上对应的时间戳
t0。 - 处理。音频可以加上混响。画面可以做各种滤镜处理。
- 混合。将背景音乐、麦克风声音混合。将摄像头画面与背景图、连麦画面等做图层叠加。
- 预览。预览包括两部分:
- 耳返。音频处理后的数据,即可送入耳返通道,此时主播能听到
t0时刻的声音。主播耳朵提到对应声音时刻为t1。t1-t0表征了主播唱出一个词,到耳朵里面听到这个词的耗时。主播对耳返延时的要求比较高,该部分延时较小,大约40ms至80ms。 - 画面预览。 图像混合后的数据,接入主播屏幕画面预览,此时主播屏幕上的画面渲染时刻为
t1。一般来说t1与t0延时极其小。如果t1-t0大于40ms,人眼即能有所感知delay。
- 耳返。音频处理后的数据,即可送入耳返通道,此时主播能听到
如果Android设备不支持
Low-Latency时,耳返功能本身耗时较大,大约300ms以上,但是并不影响直播整体延时。
关于Android耳返测试效果,请见链接。
- 编码。如果直播准备采用30fps推流,那么视频编码需要达到至少30fps的性能。每帧编码耗时需要控制在33ms以下。整个编码的耗时除了单帧耗时,还有B帧参数数量。编码器配置和编码性能会引入耗时。
- 网络自适应内部有个发送
buffer,用于监控网络发送情况,并在网络恶劣情况下丢掉待发送的码流数据。基本逻辑如下(可以看到,只在网络从良好到恶劣的转变过程中,临时引入延时):- 网络良好时,发送
buffer内为空。该环节不引入延时。 - 网络恶劣时,发送
buffer堆积,超过阈值触发丢帧。该环节引入固定延时。 - 网络恶劣时,监控
buffer堆积,反馈编码器降低输出码率,buffer堆积情况转好,直至清空buffer。清空后延时归零。
- 网络良好时,发送
- 封包。flv封包过程简单,不引入延时。
- 发送。对于不同的协议:
- RTMP推流层不引入延时,客户端tcp协议栈buffer延时很小,可以忽略。TCP引入的延时主要在高丢包、高重传率网络下,链路引入的延时。
- 基于UDP的私有推流协议,协议层可能引入buffer,依照实际情况而定。高丢包或者高重传率的网络情况下,链路延时UDP优于TCP。
总结就是,推流端经过不懈努力,除了突变的网络情况临时引入的buffer延时,推流SDK的延时主要是滤镜处理(gpu性能相关)、编码性能引入的延时(cpu性能相关)。该延时一般在100ms左右。
2.2 上行节点
上行节点会透明转发数据,合理的上行加速,会降低主播直连源站的链路延时。
同时上行节点也支持就近分发,也能降低链路延时。
2.3 源站
源站在接收直播数据时会缓存该路直播的最新音视频数据,一般为若干个GOP,某CDN节点初次向源站请求某直播流数据时,源站会将缓存的数据全部传给该CDN节点。
在CDN已与源站建立链接并拉取该路直播的数据时,源站会将最新的数据转发给CDN。
2.4 转码
转码服务从源站拉取直播流,并转码转推回源站。此时会引入转码延时。实时转码延时一般会引入100ms-200ms延时。
2.5 拉取器
从其他数据源拉取直播流后,转推到源站。
如果拉取器与数据源带宽满足实时传输的前提下,延时主要依赖数据源的延时。
2.6 下行节点
在第一次接收到播放某直播流的请求后,CDN边缘节点会通过CDN网络拉取该直播流的数据并缓存最新若干*gop的数据,以便应答后续可能的播放请求。
当某一个观众端发起播放请求,播放器在与CDN节点初次建立链接后,播放器会快速从CDN边缘节点读取其缓存数据直至读取到最新数据。在播放器耗尽对应的gop缓存前,下行节点引入了短暂的延时。
耗尽gop缓存的场景大致几种:
- 播放端拉流速度足够快,会很快耗尽该
buffer; - 播放端拉流速度和直播流码率相差不大,该
buffer长期位于CDN边缘节点,该部分缓存无法清除; - 播放器拉流速度低于直播流码率,播放端频繁卡顿,该
buffer持续增长,触发CDN边缘节点对buffer的丢帧逻辑。该场景的延时等于CDN边缘节点的buffer最大阈值。该情况下,观众端观看体验很差,应该通过客户端监控断开连接并选择更低码率的直播流。
一般情况下,用户场景主要在1场景下,即观众拉流速度最大值大于直播流码率。下文重点考虑该场景。
2.7 播放端
观众端开始播放某直播流,大量gop cache数据到了播放器内存,这部分缓存是影响直播延时的关键部分。
举个例子,该直播流gop为3秒,CDN边缘节点gop配置为6秒。观众端拉流速度足够快,开播后,播放器内会出现6至9秒的音视频数据。
本文的核心考量是如何快速消耗这部分数据,以达到降低直播延时的目的。
三. 延时控制思路
3.1 延时的说明
章节2.6、2.7已经说明了原理,这里画个图说明一下。
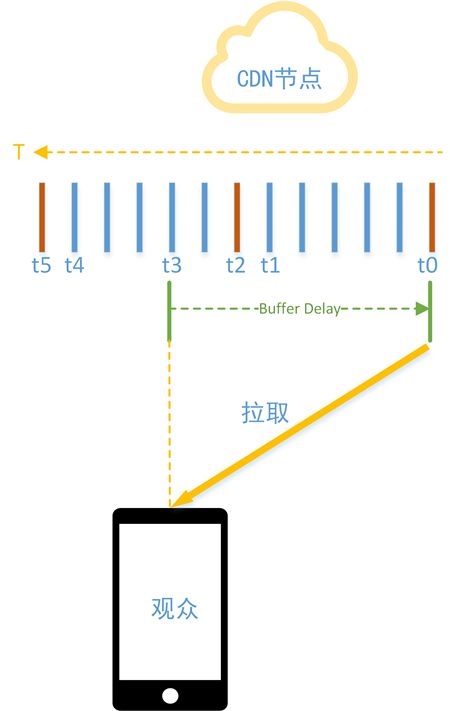
图中黄色箭头是时间轴,t0时刻首先到来。
为了方便举例,先说前提条件:当前直播流是固定关键帧间隔,固定帧率30fps。在CDN边缘节点,t0时刻到了第一个关键帧。t1时刻到了第一个gop最后一帧。t2时刻到了第二个关键帧。t2-t0值为3秒。t3-t2为1秒。t4是第二个gop最后一帧。t5时刻到了第三个关键帧。当前CDN边缘节点缓存配置为3秒。那么有如下结论:
-
t2-t0为关键帧间隔,值为3秒; - CDN
buffer的最小数据长度为t0至t1,即3秒缓存数据; - CDN
buffer的最大数据长度为t0至t4,即6秒缓存数据; -
t5时刻关键帧的到来,会触发t0至t1的整个gop从当前buffer中清空;
如果观众在t3时刻发起播放请求,如果观众的拉流速度足够快,从t0对应的关键帧到t3对应的视频数据,会快速转移到播放器待解码队列中。由于t3位于t2后一秒,即此时播放器待解码队列中cache了4秒音视频数据,观众看到的画面与主播画面最小延时4秒(忽略了链路延时)。后续拉流的再次卡顿,会持续引入更多的延时。
3.2 思路
缓存即延时,播放器缓存的数据即引入延时的关键点,将播放器的缓存快速消耗就能降低直播延时。有两种方案可供选择,各有优劣:
- 倍速播放
若想快速消耗播放器缓存的数据,则需要设置较高的播放倍速,可能导致音频播放时有尖锐的声音。
播放倍速较低时不会有尖锐的声音,但是持续时间较长。 - 丢弃数据
此方案必须考虑音视频数据各自的特性,即音频数据可视情况随意丢弃,而视频帧就必须考虑帧与帧之间的参考关系,不能随意丢弃。与此同时还需考虑音视频同步的情况,以免造成新的问题。
NetStream bufferTimeMax提供了播放RTMP/HTTP-FLV直播流时flash播放内核控制延时的思路,金山云多媒体团队借鉴了该思路。
flash控制时延的思路是,当大于阈值bufferTimeMax时,NetStream会根据当前延时的具体情况,audio播放速度提速1.5%到6.25%。这个较小的提速,可以保证音频下采样引入的变声无法察觉。
四. 直播延时控制实践
金山云多媒体SDK直播实践中,降低直播延时采用的第二种方案,该方案涉及播放器使用的音视频同步策略。下面将简述播放器使用的音视频同步策略视频同步至音频,即
- 音频解码后分次将数据写入播放音频的对象,根据该音频帧
PTS及已写入数据量更新音频时间轴; - 视频解码后将数据放入队列,由视频渲染线程从队列中取一帧视频,根据该视频帧的PTS及音频时间轴等信息判断是否可渲染。
4.1 降低直播延迟的条件
文件解析后,播放器内部会有待解码的音频数据缓存队列与视频数据缓存队列,根据现有的音视频同步策略,音频时间轴是基准时间轴,音频缓存队列的可播放时长反映了播放器的缓存时长。因此可以
- 使用音频缓存队列的可播放时长是否超过设定阈值做为判断是否发起降低直播延迟的动作的条件;
- 音频缓存队列的可播放时长是否低于阈值作为判断是否停止降低直播延迟的条件;
4.2 丢弃音频数据
基于现有的音视频同步策略,当音频时间轴出现跳跃时视频帧会使用最新的音频时间轴做同步,导致视频快速渲染,也即多余的缓存被快速消耗。
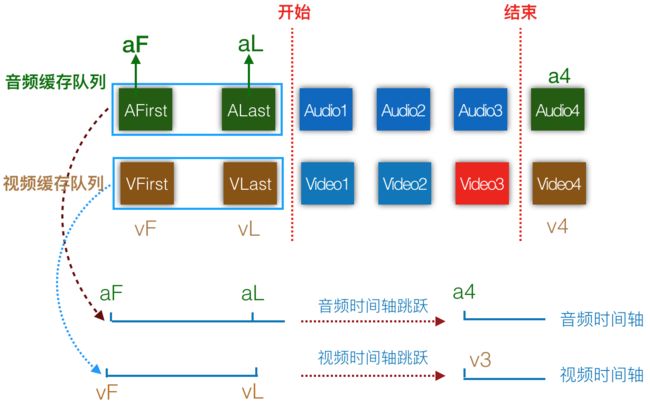
下图为降低直播延时时对音视频数据操作的示意图,竖直红色虚线表示降低直播延时行为的开始与结束。
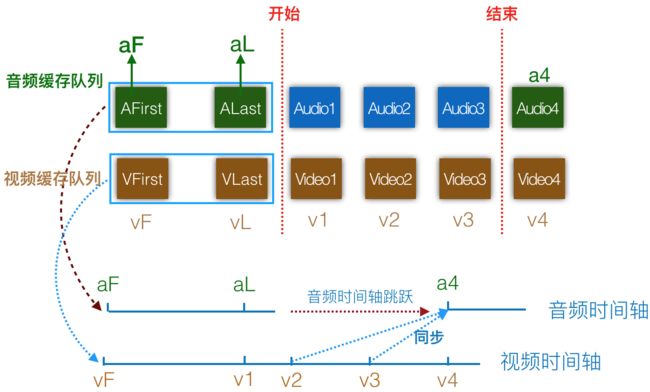
- 音频缓存队列中首帧与尾帧的
PTS为aF、aL,视频缓存队列中首帧与尾帧的PTS为vF、vL,后续读取的视频帧的PTS为v1、v2等。正常情况下Video1、Video2的视频数据大致分别同步至Audio1、Audio2的音频数据。 - 降低直播延迟期间新读取到的音频数据会被丢弃,也即蓝色方块所代表的音频数据会被丢弃。读取到音频帧
Audio4时,音频缓存队列可播放时长已低于预设的阈值,降低直播延时的行为结束,Audio4会被放入音频缓存队列 - 从上图可以看到,播放过程中音频时间轴的发生了一次跳跃,在音频帧ALast播放完毕时会继续播放音频帧
Audio4,音频时间轴会跳跃至音频帧Audio4的PTS: a4 - 视频帧
Video2会被解码并等待渲染时已经开始播放音频帧Audio4,Video2会同步至Audio4,但此时音频时间轴已经领先于视频时间轴(a4 > v2),导致Video2会被立刻渲染,同理于Video3。此过程持续至音频时间轴与视频时间轴的差值在阈值内
此方法会导致视频快速渲染,出现类似于快进效果以及解码后丢帧。
4.3 丢弃视频数据
上一步骤讲述了通过丢弃音频数据快速消耗播放缓存数据以降低直播延时的方法,该方法会要求视频解码器的快速解码。
在降低直播延时的过程中,满足一定条件的情况下是可以丢弃视频数据的。
下图为降低直播延时过程中丢弃音频及视频数据的示意图:
- 在开始降低直播延时之后读取的视频数据均会先放入视频缓存队列,上图中
Video1与Video2均为降低直播延时过程中读取到的非关键视频帧
+Video3视频帧为IDR帧(关键帧,此帧之后的视频帧不能以此帧之前的视频帧为参考帧),此刻可查找视频队列,DTS大于aL(音频缓存队列尾帧的PTS)的视频帧可被丢弃,例如Video1与Video2。然后将Video3放入视频缓存队列中 - 这样操作会使视频内容与时间轴发生跳跃。
降低直播延时的过程中,音频缓存队列尾帧ALast之后的音频帧均会被丢弃,在读到视频的IDR帧时,将视频缓存队列中DTS大于音频帧ALast的PTS的视频帧丢弃,可视为丢弃与已丢弃音频对应的视频帧。可避免出现只丢弃音频帧时视频画面快进的效果。
五. ijkplayer代码实践
本节会基于ijkplayer最新版本k0.8.4,简要介绍降低直播延时功能的关键代码实现。本节后续代码默认诸位读者对ijkplayer的基本结构、核心结构体与关键函数有基本的认识,对ijkplayer不熟悉的同学可以参考文章ijkplayer架构深入剖析。
5.1 基本定义
关于下述结构体的定义于文件 ijkmedia/ijkplayer/ff_ffplay_def.h
struct VideoState {
int audio_stream; // 音频流索引
PacketQueue audioq; // 音频缓存队列
int video_stream; // 视频流索引
PacketQueue videoq; // 视频缓存队列
int realtime; // 标志是否为直播视频
int chasing_status; // 标志是否开启 降低直播延时功能
int64_t latest_pts_in_audio_queue; // 音频队列尾帧的PTS
int buffer_time_max; // 开始降低直播延时的阈值
};
struct FFPlayer {
VideoState *is;
FFStatistic stat;
}
5.2 状态管理与丢弃音频数据
上文提到降低直播延时功能的开启与关闭是以音频缓存队列可播放时长为基准,因此在播放过程中每次读取到音频数据之后需判断音频缓存队列可播放时长,开启、关闭降低直播延时的操作或无操作。
文件ijkmedia/ijkplayer/ff_ffplay.c中函数read_thread
static int read_thread(void *arg) {
FFPlayer *ffp = arg;
VideoState *is = ffp->is;
AVFormatContext *ic = NULL;
AVPacket pkt1, *pkt = &pkt1;
int ret, pkt_in_play_range = 0;
// ...
ret = av_read_frame(ic, pkt);
// ...
if (is->realtime && pkt->stream_index == is->audio_stream) {
// 开启降低直播延时功能
if( ffp->stat.audio_cache.duration > ffp->buffer_time_max) {
is->chasing_status = 1;
if(is->audioq.last_pkt)
is->latest_pts_in_audio_queue = is->audioq.last_pkt->pkt.pts;
else
is->latest_pts_in_audio_queue = pkt->pts;
}
// 关闭降低直播延时的功能
if (is->chasing_status && ffp->stat.audio_cache.duration < ffp->i_buffer_time_max) {
is->chasing_status = 0;
is->latest_pts_in_audio_queue = INT64_MAX;
}
// 丢弃音频数据
if (is->chasing_status)
pkt_in_play_range = 0;
}
}
5.3 丢弃视频数据
文件ijkmedia/ijkplayer/ff_ffplay.c中函数read_thread
static void packet_queue_flush_by_dts(PacketQueue *q, int64_t dts) {
// 实现根据输入dts丢弃PacketQueue里的相应数据
}
static int read_thread(void *arg) {
FFPlayer *ffp = arg;
VideoState *is = ffp->is;
AVFormatContext *ic = NULL;
AVPacket pkt1, *pkt = &pkt1;
int ret, pkt_in_play_range = 0;
// ...
ret = av_read_frame(ic, pkt);
// ...
// 丢弃视频数据
if (is->realtime && pkt->stream_index == is->video_stream) {
if (pkt->flags & ((pkt->flags & AV_PKT_FLAG_KEY) == AV_PKT_FLAG_KEY)) {
if (is->chasing_status)
packet_queue_flush_by_dts(&is->videoq, is->latest_pts_in_audio_queue);
}
}
}
六. 结语
通过以上介绍的方法就实现了降低直播延时的功能,在探索实现降低直播延时的过程中遇到不少坑,这样的实现方案只对有音频的直播视频有效,对纯视频的直播没有效果,后续会改进此不足之处。
转载请注明:
作者金山视频云,首发 Jianshu.com
也欢迎大家使用我们的直播、短视频SDK。金山云SDK仓库地址:
https://github.com/ksvc
金山云SDK相关的QQ交流群:
- 视频云技术交流群:574179720
- 视频云Android技术交流:6200036233