1. Spark Streaming概述
1.1 什么是Spark Streaming
Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象语言的语法如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。

和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。
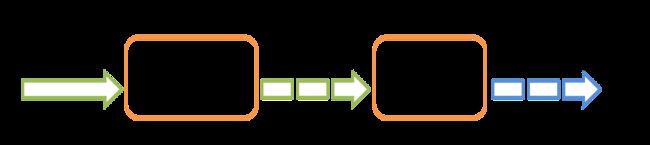
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
1.2 Spark Streaming的特点
易用
容错

易整合到Spark体系

1.3 Spark 与 Storm 对比
1.3.1 对比
对比点StormSpark Streaming
实时计算模型纯实时,来一条数据,处理一条数据准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理
实时计算延迟度毫秒级秒级
吞吐量低高
事务机制支持完善支持,但不够完善
健壮性 / 容错性ZooKeeper,Acker,非常强Checkpoint,WAL,一般
动态调整并行度支持不支持
1.3.2 Spark Streaming与Storm的应用场景
Storm
建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
Spark Streaming
如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
1.3.3 Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
1.4 Spark Streaming关键抽象
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据,如下图所示。
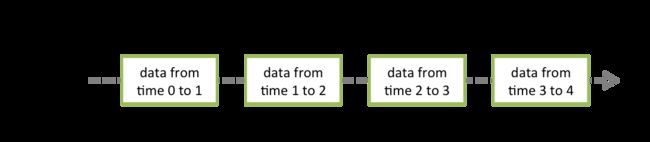
应用于DStream的任何操作都转换为底层RDD上的操作。例如,在先前将行流转换为字的示例中,flatMap操作应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。如下图所示。
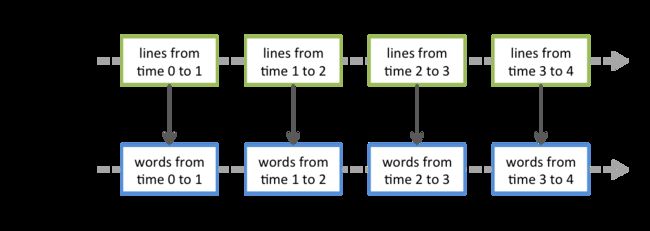
Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理,以批量生成最终结果流。
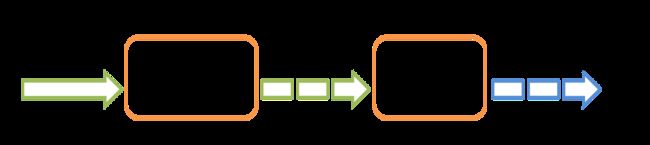
1.5 Spark Streaming 架构
Spark Streaming使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统。高层次的架构如图
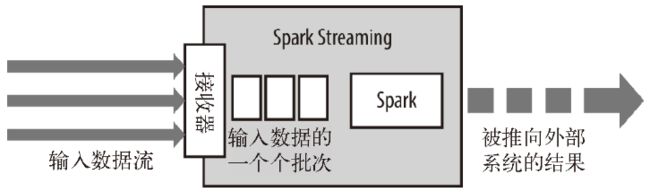
Spark Streaming在Spark的驱动器程序—工作节点的结构的执行过程如下图所示。Spark Streaming为每个输入源启动对 应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默 认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
1.6 背压机制
默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > batch interval的情况,其中batch processing time 为实际计算一个批次花费时间, batch interval为Streaming应用设置的批处理间隔。这意味着Spark Streaming的数据接收速率高于Spark从队列中移除数据的速率,也就是数据处理能力低,在设置间隔内不能完全处理当前接收速率接收的数据。如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟)。Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力。
背压机制: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted ”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
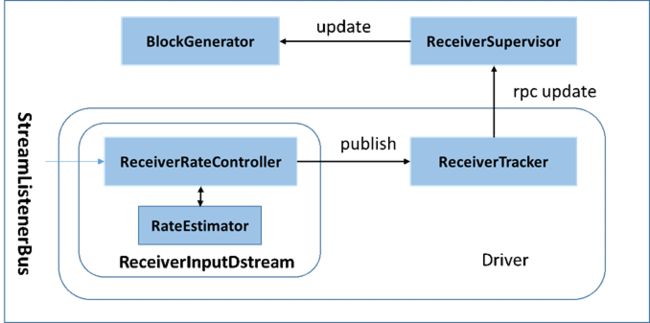
流量控制点
当Receiver开始接收数据时,会通过supervisor.pushSingle()方法将接收的数据存入currentBuffer等待BlockGenerator定时将数据取走,包装成block. 在将数据存放入currentBuffer之时,要获取许可(令牌)。如果获取到许可就可以将数据存入buffer, 否则将被阻塞,进而阻塞Receiver从数据源拉取数据。
其令牌投放采用令牌桶机制进行, 原理如下图所示:
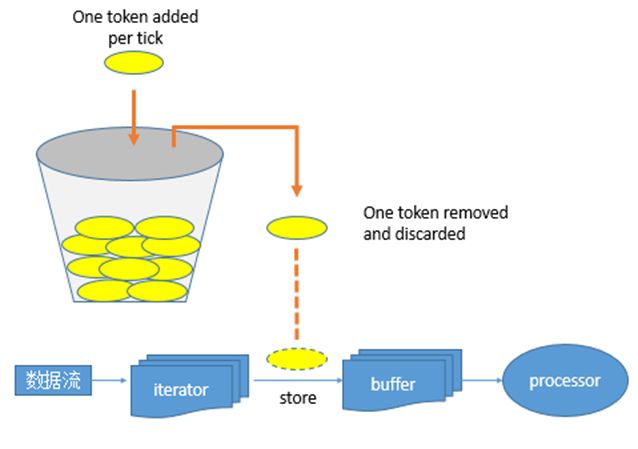
令牌桶机制
大小固定的令牌桶可自行以恒定的速率源源不断地产生令牌。如果令牌不被消耗,或者被消耗的速度小于产生的速度,令牌就会不断地增多,直到把桶填满。后面再产生的令牌就会从桶中溢出。最后桶中可以保存的最大令牌数永远不会超过桶的大小。当进行某操作时需要令牌时会从令牌桶中取出相应的令牌数,如果获取到则继续操作,否则阻塞。用完之后不用放回。
2. Spark Streaming 简单应用
2.1 安装Telnet向端口发送消息
2.2 使用SparkStreaming监控端口数据展示到控制台
3. DStream 的输入
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local或者local[1]。
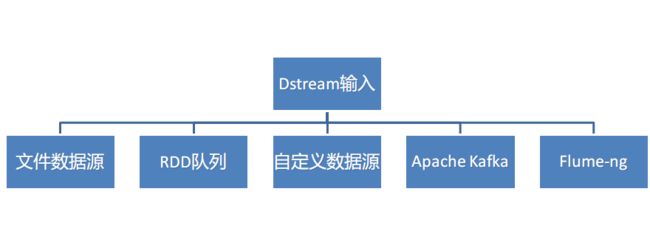
3.1 文件数据源
文件数据流:能够读取所有HDFS API兼容的文件系统文件,通过fileStream方法进行读取
Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,记住目前不支持嵌套目录。
文件需要有相同的数据格式
文件进入 dataDirectory的方式需要通过移动或者重命名来实现。
一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据。
如果文件比较简单,则可以使用 streamingContext.textFileStream(dataDirectory)方法来读取文件。文件流不需要接收器,不需要单独分配CPU核。
案例实操
## 导入相应的jar包
scala> import org.apache.spark.streaming._
## 创建StreamingContext操作对象
scala> val ssc = new StreamingContext(sc,Seconds(5))
scala> val lines = ssc.textFileStream("hdfs://master:9000/spark/data")
scala> val wordCount = lines.flatMap(_.split("\t")).map(x=>(x,1)).reduceByKey(_+_)
scala> wordCount.print
scala> ssc.start
3.2 自定义数据源
通过继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
案例实操
3.3 RDD队列
可以通过使用streamingContext.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
案例实操
3.4 Kafka
Spark 与 Kafka集成指南

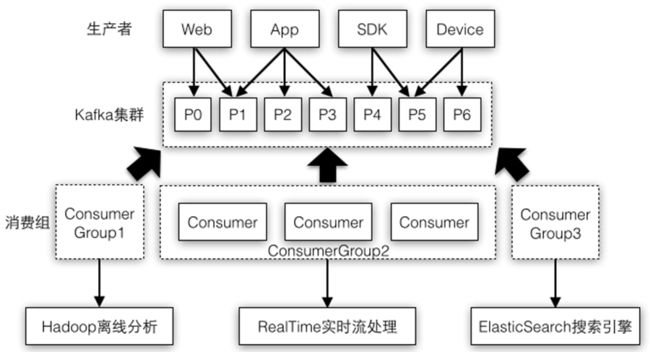
下面我们进行一个实例,演示SparkStreaming如何从Kafka读取消息,如果通过连接池方法把消息处理完成后再写会Kafka
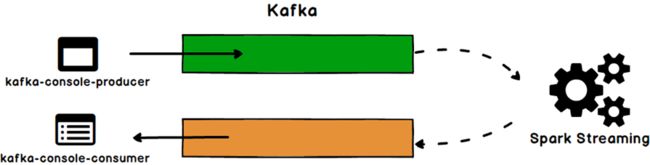
整合
1.引入jar包依赖
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
2.代码编写
//Stream2Kafka
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Stream2Kafka extends App {
//创建配置对象
val conf = new SparkConf().setAppName("kafka").setMaster("local[3]")
//创建SparkStreaming操作对象
val ssc = new StreamingContext(conf,Seconds(5))
//连接Kafka就需要Topic
//输入的topic
val fromTopic = "source"
//输出的Topic
val toTopic = "target"
//创建brokers的地址
val brokers = "master:9092,slave1:9092,slave3:9092,slave2:9092"
//Kafka消费者配置对象
val kafkaParams = Map[String, Object](
//用于初始化链接到集群的地址
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
//Key与VALUE的序列化类型
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
ConsumerConfig.GROUP_ID_CONFIG->"kafka",
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest自动重置偏移量为最新的偏移量
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"latest",
//如果是true,则这个消费者的偏移量会在后台自动提交
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG->(false: java.lang.Boolean)
)
//创建DStream,连接到Kafka,返回接收到的输入数据
val inputStream = {
KafkaUtils.createDirectStream[String, String](
ssc,
//位置策略(可用的Executor上均匀分配分区)
LocationStrategies.PreferConsistent,
//消费策略(订阅固定的主题集合)
ConsumerStrategies.Subscribe[String, String](Array(fromTopic), kafkaParams))
}
inputStream.map{record => "hehe--"+record.value}.foreachRDD { rdd =>
//在这里将RDD写回Kafka,需要使用Kafka连接池
rdd.foreachPartition { items =>
val kafkaProxyPool = KafkaPool(brokers)
val kafkaProxy = kafkaProxyPool.borrowObject()
for (item <- items) {
//使用这个连接池
kafkaProxy.kafkaClient.send(new ProducerRecord[String, String](toTopic, item))
}
kafkaProxyPool.returnObject(kafkaProxy)
}
}
ssc.start()
ssc.awaitTermination()
}
//Kafka连接池
import org.apache.commons.pool2.impl.{DefaultPooledObject, GenericObjectPool}
import org.apache.commons.pool2.{BasePooledObjectFactory, PooledObject}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig}
import org.apache.kafka.common.serialization.StringSerializer
//因为要将Scala的集合类型转换成Java的
import scala.collection.JavaConversions._
class KafkaProxy(broker:String){
val conf = Map(
//用于初始化链接到集群的地址
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG -> broker,
//Key与VALUE的序列化类型
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG->classOf[StringSerializer],
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG->classOf[StringSerializer]
)
val kafkaClient = new KafkaProducer[String,String](conf)
}
//创建一个创建KafkaProxy的工厂
class KafkaProxyFactory(broker:String) extends BasePooledObjectFactory[KafkaProxy]{
//创建实例
override def create(): KafkaProxy = new KafkaProxy(broker)
//包装实例
override def wrap(t: KafkaProxy): PooledObject[KafkaProxy] = new DefaultPooledObject[KafkaProxy](t)
}
object KafkaPool {
private var kafkaPool:GenericObjectPool[KafkaProxy]=null
def apply(broker:String): GenericObjectPool[KafkaProxy] ={
if(kafkaPool == null){
this.kafkaPool = new GenericObjectPool[KafkaProxy](new KafkaProxyFactory(broker))
}
kafkaPool
}
}
3.启动zookeeper
4.启动kafka
kafka-server-start.sh /opt/apps/Kafka/kafka_2.11_2.0.0/config/server.properties &
5.创建两个主题
[root@master ~]# kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181 --replication-factor 2 --partitions 2 --topic source
[root@master ~]# kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181 --replication-factor 2 --partitions 2 --topic target
6.启动producer 写入数据到source
[root@master ~]# kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092,slave3:9092,slave4:9092 --topic source
7.启动consumer 监听target的数据
[root@master ~]# kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092,slave3:9092,slave4:9092 --topic target
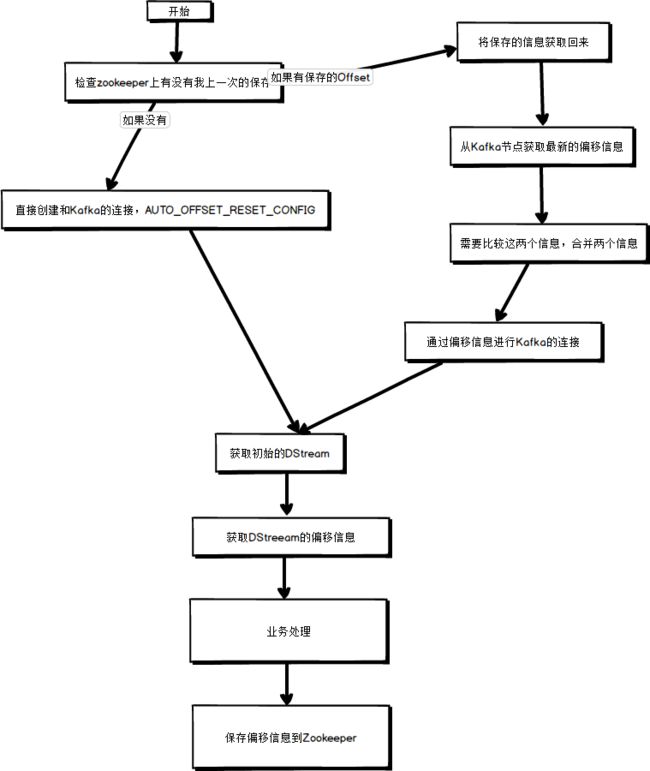
手动设置offset
4. DStream 转换
DStream上的原语与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的语法,如:updateStateByKey()、transform()以及各种Window相关的语法。
TransformationMeaning
map(func)将源DStream中的每个元素通过一个函数func从而得到新的DStreams。
flatMap(func)和map类似,但是每个输入的项可以被映射为0或更多项。
filter(func)选择源DStream中函数func判为true的记录作为新DStreams
repartition(numPartitions)通过创建更多或者更少的partition来改变此DStream的并行级别。
union(otherStream)联合源DStreams和其他DStreams来得到新DStream
count()统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams。
reduce(func)通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算。
countByValue()对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率。
reduceByKey(func, [numTasks])对(K,V)对的DStream调用此函数,返回同样(K,V)对的新DStream,但是新DStream中的对应V为使用reduce函数整合而来。Note:默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。你也可以传入可选的参数numTaska来设置不同数量的任务。
join(otherStream, [numTasks])两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream。
cogroup(otherStream, [numTasks])两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams
transform(func)将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作。
updateStateByKey(func)得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据。
DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map()、filter()、reduceByKey() 等,都是无状态转化操作。
相对地,有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。
4.1 无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。 注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加import StreamingContext._ 才能在 Scala中使用。
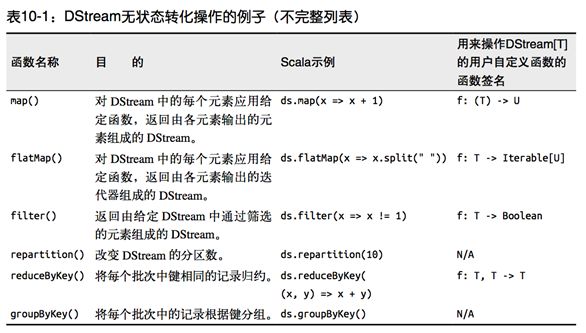
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如, reduceByKey() 会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
举个例子,在之前的wordcount程序中,我们只会统计1秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对 DStream 拥有和 RDD 一样的与连接相关的转化操作,也就是 cogroup()、join()、 leftOuterJoin() 等。我们可以在 DStream 上使用这些操作,这样就对每个批次分别执行了对应的 RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并多个流。
4.2 有状态转化操作
4.2.1 追踪状态变化UpdateStateByKey
UpdateStateByKey原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件 更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,你需要做下面两步:
1. 定义状态,状态可以是一个任意的数据类型。
2. 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
4.2.2 Window
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
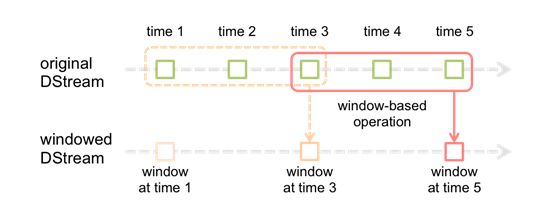
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作reduceByKeyAndWindow.