博客链接地址:https://blog.csdn.net/qq_33187206/article/details/80824414
一、什么是Phonenix?
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。
Phoenix
完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
Phoenix
通过以下方式使我们可以少写代码,并且性能比我们自己写代码更好:
将SQL编译成原生的HBase scans。确定scan关键字的最佳开始和结束让scan并行执行
二、phoenix下载
1、点击连接
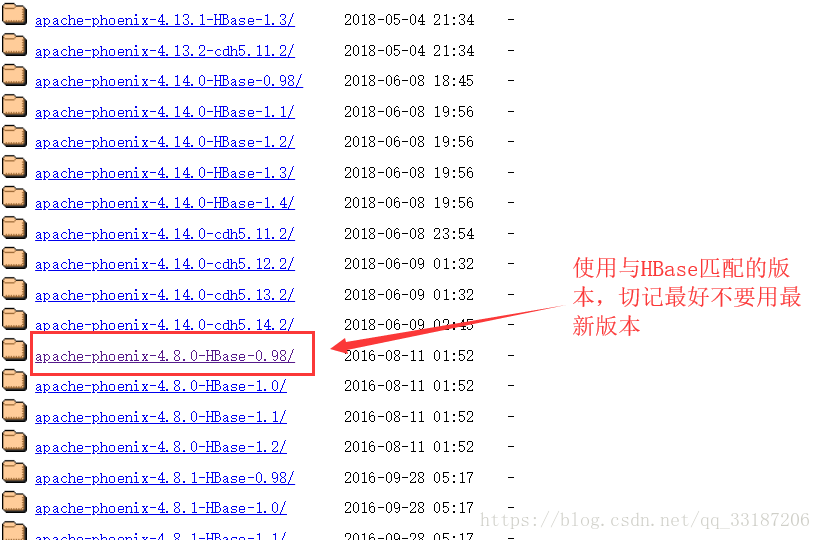
2、点击连接<官网下载>下载
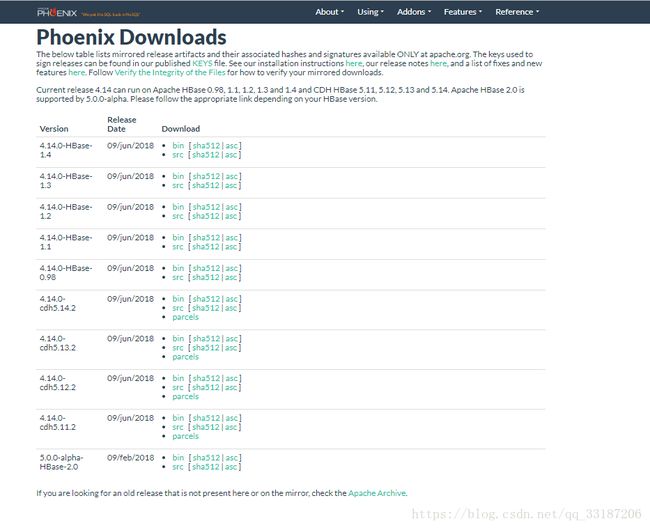
三、安装phoenix
1、解压
$ tar -zxfapache-phoenix-4.8.0-HBase-0.98-bin.tar.gz -C ../modules/
2、 与hbase集成
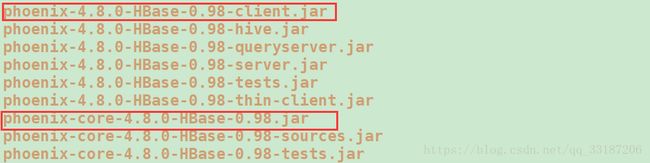
1)、将phoenix安装目录下的
phoenix-4.8.0-HBase-0.98-client.jar
phoenix-core-4.8.0-HBase-0.98.jar
拷贝到hbase的lib目录下
2)、将hbase/conf目录下hbase-site.xml 文件放到phoenix的bin目录下
四、启动phoenix
首先:zookeeper 进程需要打开
$ bin/zkServer.shstart
其次:hadoop 的进程需要开启
$ bin/start-dfs.sh
再次:hbase 的需要重启
$bin/start-hbase.sh
最后: 在Phoenix文件夹下执行,指定zk的地址作为hbase的访问入口:
bin/sqlline.py [hostname]:2181
进入Phoenix命令行,执行
!tables

注意:第一次启动可能需要1分多钟的时间,之后就会很快,主要是在hbase中做了一些初始化工作,会创建以下3张表
SYSTEM.CATALOG
SYSTEM.SEQUENCE
SYSTEM.STATS
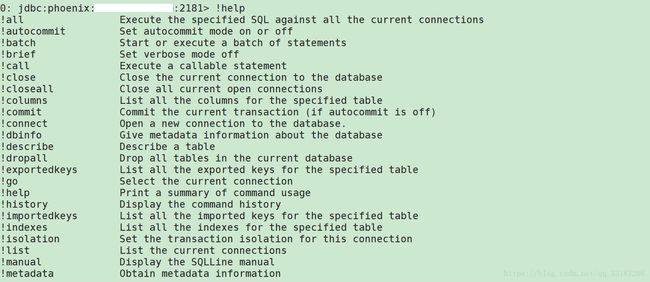
使用命令 !help 可以显示phoenix用法,下面是部分
如果 出现 import argparse 这个错误:
需要安装:$ sudoyum -y install python-argparse
五、测试
1、在show databases以及show tables是不支持的
2、-》!tables查看有什么表,hbase里面也会有phoenix的系统表
3、在phoenix中创建表
create table user(
id varchar primary key,
name varchar,
password varchar
);
1)、在hbase中是区分大小写的,在phoenix中不区分大小写,但是默认都是大写,加上双引号就是小写
2)、在hbase中desc "USER" 发现映射过来的表列簇默认是0,NAME => '0'
3)、重新创建,指定列簇与列
drop table user;
create table user(
id varchar primary key,
info.name varchar,
info.password varchar
);
4、添加数据:updata+insert结合--》upsert
upsert into user(id,name,password)values('001','admin','admin');
upsert into user(id,name,password)values('002','admin','admin');
5、查询数据:
select * from user;
6、删除数据:
delete from user where id='002';
在phoenix中的client界面中进行的crud操作,与RDBMS的操作没有太大的区别
7、hbase与phoenix表与表之间进行关联,将hbase中的表映射到phoenix
create table "stu_info"(
rowkey varchar primary key,
info"."name" varchar,
"info"."age" varchar,
"info"."sex" varchar,
"degree"."xueli" varchar,
"work"."job" varchar
);
缺陷:hbase中的字段类型都是String类型,所以,phoenix中的映射表都得是 varchar类型为好
六、在Java项目中集成Phoenix
在Java项目中实现Phoenix操作Hbase,maven引入Phoenix的依赖包:
org.apache.phoenix
phoenix-core
4.8.0-HBase-0.98
但是引入这个包是不够的,还需要另外引入一个依赖包
phoenix-4.8.0-HBase-0.98-client.jar
,这个依赖包可以在Phoenix文件中找到,也可以通过下载Phoenix源码,自行编译后导入,自此就可以通过java的JDBC访问操作Hbase。
java测试的源码如下:
public static void main(String args[]) {
Connectionconnection = null;
Statementstatement = null;
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
connection=DriverManager.getConnection("jdbc:phoenix:master:2181","","");
statement =connection.createStatement();
statement.execute("upsert into yinxiang_note values (3, 'note ofhuhong')");
} catch(Exception e) {
e.printStackTrace();
} finally {
try {
connection.close();
statement.close();
} catch(Exception e) {
e.printStackTrace();
}
}
}
相关博客:
hive整合phoenix :https://www.aliyun.com/jiaocheng/828057.html
phoenix四贴:Phoenix四贴之一:扫盲贴
https://blog.csdn.net/qq1226317595/article/details/80375009
Phoenix三贴之二:Phoenix二级索引系统
https://blog.csdn.net/qq1226317595/article/details/82833782#comments
Phoenix四贴之三:hive整合
https://blog.csdn.net/qq1226317595/article/details/80375032
Phoenix安装使用及使用SQuirrel客户端连接操作Hbase
https://blog.csdn.net/NDF923/article/details/77838267
Phoenix 介绍和基本用法
https://blog.csdn.net/naioonai/article/details/80680023
Phoenix二级索引(Secondary
Indexing)的使用
https://www.cnblogs.com/MOBIN/p/5467284.html