趁着工作业余时间,趁着内心对技术追求的热情,还是对Spark这个大数据内存计算框架动手了,毕竟人与人之间的差距都是在工作业余时间拉开的……
Spark官网:http://spark.apache.org/
一、Spark概述
官网已经说的很明白了,我这里记录一些重点。Spark是一种分布式计算框架,对标Hadoop的MapReduce;MapReduce适用于离线批处理(处理延迟在分钟级)而Spark既可以做离线批处理,也可以做实时处理(SparkStreaming)
①Spark集批处理、实时流处理、交互式查询、机器学习与图计算一体
②Spark实现了一种分布式的内存抽象,称为弹性分布式数据集;RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,极大提升了查询速度
二、Spark VS MapReduce
1.MapReduce存在的问题
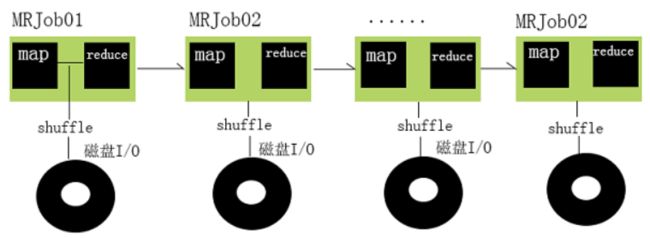
一个Hadoop的Job通常经过以下几个步骤:
①从HDFS中读取输入数据
②在Map阶段使用用户定义的mapper function,然后将结果spill到磁盘
③在Reduce阶段从各个处于Map阶段的机器读取Map计算的中间结果,使用用户自定义的reduce function,通常最后把结果写回HDFS
Hadoop的问题在于,一个Hadoop Job会进行多次磁盘读写,比如写入机器本地磁盘,或是写入分布式文件系统中(这个过程包含磁盘的读写以及网络传输)。考虑到磁盘读取比内存读取慢了几个数量级,所以像Hadoop这样高度依赖磁盘读写的架构就一定会有性能瓶颈;而且有些场景比如一些迭代性质的算法(逻辑回归)会重复利用某些Job的结果,导致触发重新计算带来大量的磁盘I/O。
2.Spark优势
Spark没有像Hadoop那样使用磁盘读写,而转用性能高得多的内存存储输入数据、处理中间结果和存储中间结果。在大数据的场景中,很多计算都有循环往复的特点,像Spark这样允许在内存中缓存写入输出,上一个Job的结果马上被下一个使用,性能自然比Hadoop Map Reduce好的多。
①Spark会尽量避免产生shuffle过程
②可以将指定的步骤的数据进行缓存,这样的好处:在需要时不要重新计算,直接从缓存中获取结果
三、Spark-RDD
官网的介绍呢,翻译成人话(个人口语不喜勿喷)
①RDD就是一种集合类型,类比于ArrayList和List
②RDD是一种特殊的集合类型,有分区机制(引入分区机制的目的:可以分布式的处理数据,加快处理速度)
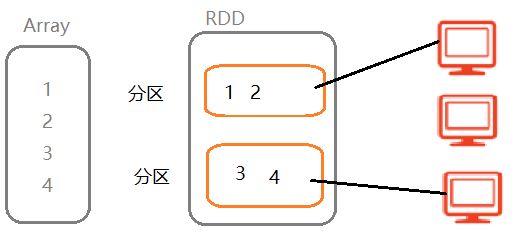
③RDD是一种特殊的集合,具有容错机制,即当分区数据丢失时,可以进行恢复
综上所述,RDD就是一种特殊的集合类型,有分区机制,有容错机制。因为Spark框架处理任何数据,都要把数据封装到RDD中,然后针对RDD来计算,所以说RDD是Spark最核心的概念。
创建RDD的2种方式:
(1)将一个普通的集合类型(Array或List)转变成RDD
(2)读取文件数据,将文件数据转变RDD
PS:操作RDD,可以使用所有关于普通集合的方法来操作,比如:map,flatMap,filter,sortBy,groupBy等
四、RDD操作(变换与执行)
针对RDD的操作,分2种,一种是Transformation(变换),一种是Actions(执行),Transformation(变换)操作属于懒操作(算子),不会真正触发RDD的处理计算;Actions(执行)操作才会真正触发。
1.Transformation操作

2.Actions操作

3.RDD操作总结
①RDD操作分为:变换操作(Transformation)和执行操作(Action)
②变换操作(Transformation)都是懒操作,即并不是马上计算,每执行一次懒操作,都会产生一个新的RDD
③执行操作(Action)会触发计算
五、RDD的依赖关系
RDD的依赖关系总的来分有2种
(1)窄依赖,父分区和子分区是一对一关系,产生窄依赖的懒方法:map,flatMap,filter……
(2)宽依赖,父分区和子分区是一对多关系,产生宽依赖的懒方法:groupByKey,reduceByKey等分组方法

针对窄依赖,不会产生shuffle,所以执行效率很高。此外,如果一个DAG中存在多个连续的窄依赖,则会放到一起执行,这种优化方式,称为流水线优化。所以从这点来看,Spark尽量避免产生shuffle,避免产生磁盘I/O
针对宽依赖,会产生shuffle,所谓的Shuffle,就是按照某种分组条件,将数据分发到对应的分区,所以这个过程会产生大量的数据,会发生多次的磁盘读写,所以,Spark并不是完全基于内存的,也是有磁盘I/O过程的,只是已经极力避免这样的过程。注:一旦宽依赖的子分区数据丢失,最严重的情况是要计算所有RDD的父分区数据,相当于重新计算,这种计算过大,所以shuffle过程将中间结果落地(临时文件)
六、DAG与Stage的划分

①Stage本质是一组Task的集合
②Task对应分区,一个分区对应一个Task(Spark处理任务其实就是处理分区数据)
③Task分为MapTask和ResultTask
七、WordCount单词计数案例

上图中演示了WordCount的计算链,Spark把计算链抽象成一个DAG(有向无环图)DAG中记录了RDD之间的依赖关系,比如RDD1是RDD2的父RDD,他们之间的依赖关系由flatMap方法所生成。借助依赖关系,RDD可以实现数据容错(数据丢失后可以恢复)即当子RDD某个分区数据丢失时,根据依赖关系找父RDD对应的分区即可恢复
八、总结
(1)RDD:弹性分布式数据集,是Spark最核心的数据结构,有分区机制,所以可以分布式进行处理;有容错机制,通过RDD之间的依赖关系来恢复数据
(2)依赖关系:RDD的依赖关系是通过各种Transformation来得到的,父RDD和子RDD之间的依赖关系分为以下2种:
①窄依赖:父RDD和子RDD的分区关系是一对一,窄依赖不会发生Shuffle,执行效率高,spark框架底层会针对多个连续的窄依赖执行进行流水线优化,从而提高性能。例如map,flatMap等都是窄依赖方法
②宽依赖:父RDD和子RDD的分区关系是一对多,宽依赖会产生Shuffle会产生磁盘读写,无法优化。
(3)DAG有向无环图,当一整条会根据RDD之间的依赖关系进行stage划分,流程是:以Action为基准,向前回溯,遇到宽依赖,就形成一个stage。遇到窄依赖则执行流水线优化(将多个窄依赖放到一起执行)
(4)task:任务,一个分区对应一个task,可以理解为:一个Stage是一组Task的集合
(5)RDD的Transformation变换操作属于懒操作,并不会立即执行;Action操作触发真正的执行