本项目主要实现目标为:1根据热水器采集的数据,划分一次完整用水事件。2在划分好的一次完整用水事件中,识别出洗浴事件。
1. 划分一次完整的用水事件
本案例要分两个步骤来做,第一步是根据数据划分一次完整的用水事件,而一次完整的用水事件是根据水流量和停顿事件间隔的阈值划分的,所以需要建立阈值寻优模型。
1.1 使用固定阈值来划分
在用水状态记录中,水流量不为0表示用户正在用热水,而水流量为0时表示用热水发生停顿或结束,如果水流量为0的状态记录之间的事件间隔超过阈值T,则从该段水流量为0的状态记录向前找到最后一条水流量不为0的用水记录作为上一次用水事件的结束,而先后找到水流量不为0的状态记录作为下一个用水事件的开始。
threshold = pd.Timedelta('4 min') #阈值为分钟
data = data[data['水流量'] > 0] #只要流量大于0的记录
d = data['发生时间'].diff() > threshold #相邻时间作差分,比较是否大于阈值
data['事件编号'] = d.cumsum() + 1 #通过累积求和的方式为事件编号
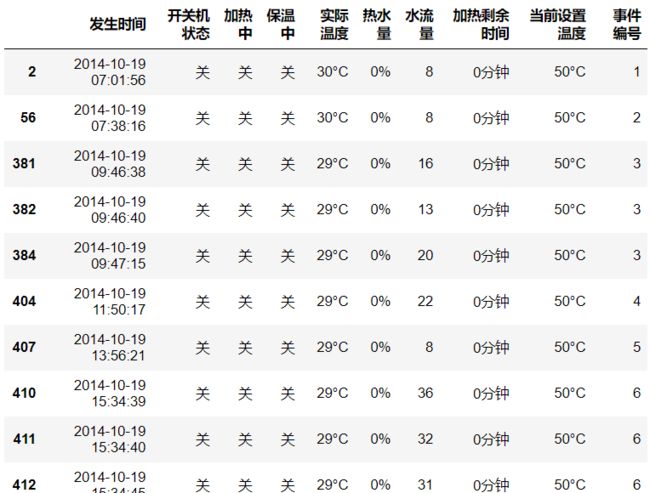
上面的代码中,通过累计求和的方式来作为事件编号是一种非常巧妙的方法。可以保证前后间隔小于阈值(即4min)的事件标注为同一个事件编号。
1.2 用水事件阈值寻优模型
上面用固定的4min作为阈值来划分用水事件,但不同地区的用水习惯不同,且同一个地区,季节不同用水习惯也不同,固定的阈值在某些情况并不理想,所以需要建立阈值寻优模型来更新寻找最优的阈值。
data=pd.read_excel(r"E:\PyProjects\DataSet\PyMining\Data\chapter10\demo\data\water_heater.xls")
data['发生时间'] = pd.to_datetime(data['发生时间'], format = '%Y%m%d%H%M%S')
data = data[data['水流量'] > 0] #只要流量大于0的记录
dt = [pd.Timedelta(minutes = i) for i in np.arange(1, 9, 0.25)]
# 获取不同的阈值,从1min-9min, 间隔0.25min
h = pd.DataFrame(dt, columns = ['阈值']) #定义阈值列
n = 4 #使用以后四个点的平均斜率
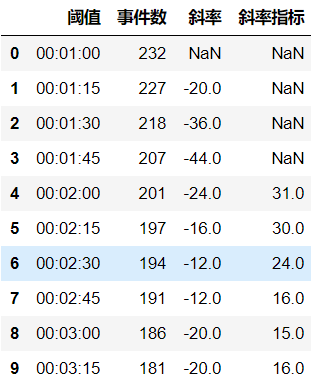
h[u'事件数'] = h[u'阈值'].apply(event_num) #计算每个阈值对应的事件数
h[u'斜率'] = h[u'事件数'].diff()/0.25 #计算每两个相邻点对应的斜率
h[u'斜率指标'] = h[u'斜率'].abs().rolling(n).mean() #采用n个点的斜率绝对值平均作为斜率指标
h.head()
ts = h[u'阈值'][h[u'斜率指标'].idxmin() - n]
#注:用idxmin返回最小值的Index,由于rolling_mean()自动计算的是前n个斜率的绝对值平均
#所以结果要进行平移(-n)
plt.plot(h['阈值'],h['斜率指标'],'r+')

上面的ts指标就是4min,表明最佳阈值为4min,这个寻优过程的基本原理是:在某段阈值范围内,下降趋势明显,说明在该段阈值范围类,用户的停顿习惯比较几种,所以可以用该段时间开始作为阈值。
2. 在完整事件中,识别出洗浴事件
这个本质上就是一个分类模型,将完整事件进行分类,可以是二分类,是/不是洗浴事件,或多分类,对每一个事件进行分类,其中包括有洗浴事件。
建模首先要构建数据集,特别是抽取特征,这是一个非常重要的步骤,本项目建立了4种特征:时长指标,频率指标,用水量,用水波动指标。

2.1 构建二分类模型
数据中的标记是通过日志的来,故而比较准确。所以此处构建神经网络的二分类模型
train=pd.read_excel(r"E:\PyProjects\DataSet\PyMining\Data\chapter10\demo\data\train_neural_network_data.xls")
trainX=train.iloc[:,5:17]
trainX=(trainX-trainX.mean(axis=0))/trainX.std(axis=0)
trainy=train.iloc[:,4]
testX=test.iloc[:,5:17]
testX=(testX-testX.mean(axis=0))/testX.std(axis=0)
testy=test.iloc[:,4]
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
model=Sequential()
model.add(Dense(20,activation='relu',input_shape=(11,))) # 此处有11个特征
model.add(Dense(10,activation='relu'))
model.add(Dense(1,activation='sigmoid')) # 二分类模型用sigmoid
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['acc'])
model.fit(trainX,trainy,batch_size=20,epochs=100,validation_data=(testX,testy))


由此可以看出,大约在70epochs之后出现过拟合,最终的val acc为0.95左右,而train acc达到了1.0.
所以模型的结果比较好。
参考资料:
《Python数据分析和挖掘实战》张良均等