7.4.2 正则表达式
正则表达式(regex)提供了一种灵活的在文本中搜索或匹配字符串模式的方式。
正则表达式是根据正则表达式语言编写的字符串。
re模块的函数可以分为三类:模式匹配;替换;拆分。他们之间相辅相成。
一个regex描述了需要在文本定位的一个模式。
例子:假如想拆分一个字符串,分隔符为数量不定的一组空白符(制表符、空格、换行符)。描述一个或多个空白符的regex是 :\s+
In [57]: import re
In [58]: text="foo bar\t baz \tqux"
In [59]: re.split('\s+',text)
Out[59]: ['foo', 'bar', 'baz', 'qux']
调用re.split('\s+',text)时,正则表达式会先被编译,然后再在text上调用其split方法。
可以用re.compile自己编译regex以得到一个可重用的regex对象:
In [60]: regex=re.compile('\s+')
In [61]: regex.split(text)
Out[61]: ['foo', 'bar', 'baz', 'qux']
如果只希望匹配到regex的所有模式,可以使用findall方法
In [62]: regex.findall(text)
Out[62]: [' ', '\t ', ' \t']
如果想对许多字符串应用同一条正则表达式,建议通过re.compile创建regex对象。节省CPU时间。
findall返回的是字符串中所有的匹配项,而search则只返回第一个匹配项。
match更严格,只匹配字符串的首部。
例子,假设我们有一段文本和一段能识别大部分电子邮件的地址的正则表达式。
In [63]: text = """Dave [email protected]
...: Steve [email protected]
...: Rob [email protected]
...: Ryan [email protected]
...: """
In [64]: pattern=r'[A-Z0-9._%+-]+@[A-Z0-9._]+\.[A-Z]{2,4}'
#re.IGNORECASE的作用是使得正则表达式对于大小写不敏感
In [65]: regex=re.compile(pattern,flags=re.IGNORECASE)
In [68]: regex.split(text)
Out[68]: ['Dave ', '\nSteve ', '\nRob ', '\nRyan ', '\n']
#text使用fillall得到一组电子邮件地址
In [69]: regex.findall(text)
Out[69]: ['[email protected]', '[email protected]', '[email protected]', '[email protected]']
#search返回的是文本中的第一个电子邮件地址
In [70]: m=regex.search(text)
In [71]: m
Out[71]: <_sre.SRE_Match at 0xb992e68>
#对于regex,匹配项对象只能告诉我们模式在原始字符串中的开始和结束位置
In [72]: text[m.start():m.end()]
Out[72]: '[email protected]'
In [74]: regex.match(text)
#regex返回None,因为它只匹配出现在字符串开头的模式
In [75]: print regex.match(text)
None
#sub方法将匹配到的模式替换为指定的字符串,并返回所得到的新字符串
In [76]: regex.sub('RECACTED',text)
Out[76]: 'Dave RECACTED\nSteve RECACTED\nRob RECACTED\nRyan RECACTED\n'
In [77]: print regex.sub('RECACTED',text)
Dave RECACTED
Steve RECACTED
Rob RECACTED
Ryan RECACTED
#将地址分为用户名、域名、以及域后缀,将分段模式括号括起来
In [78]: pattern=r'([A-Z0-9._%+-]+)@([A-Z0-9._]+)\.([A-Z]{2,4})'
In [79]: regex=re.compile(pattern,flags=re.IGNORECASE)
#通过groups方法返回一个由模式各段组成的元组
In [80]: m=regex.match('[email protected]')
In [81]: m.groups()
Out[81]: ('wesm', 'bright', 'net')
#对于带有分组功能的模式,findall会返回一个元组列表
In [82]: regex.findall(text)
Out[82]:
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
#sub还能通过\1 、 \2 之类的特殊符号访问各项匹配项中的分组
In [83]: print regex.sub(r'Username:\1,Domain:\2,Suffix:\3',text)
Dave Username:dave,Domain:google,Suffix:com
Steve Username:steve,Domain:gmail,Suffix:com
Rob Username:rob,Domain:gmail,Suffix:com
Ryan Username:ryan,Domain:yahoo,Suffix:com
In [84]: regex=re.compile(r"""(?P[A-Z0-9._%+-]+)@(?P[A-Z0-9._]+)\.(?P[A-Z]{2,4})""",flags=re.IGNORECASE|re.VERBOSE)
#产生了一个带有分组名称的字典
In [85]: m=regex.match('[email protected]')
In [86]: m.groupdict()
Out[86]: {'domain': 'bright', 'suffix': 'net', 'username': 'wesm'}

7.4.3 pandas中矢量化的字符串函数
清理待分析的散乱数据的时,需要做一些字符串规整化工作。
有时候情况复杂,含有字符串的列有时还含有缺失数据:
In [90]: data = {'Dave':'[email protected]','Steve':'[email protected]','Rob':'[email protected]','Web':np.nan}
In [91]: data=Series(data)
In [92]: data
Out[92]:
Dave [email protected]
Steve [email protected]
Web NaN
dtype: object
In [93]: data.isnull()
Out[93]:
Dave False
Rob False
Steve False
Web True
dtype: bool
所有的字符串和正则表达式都能被应用于各个值,如果存在NA就会报错。为了解决这个问题,Series有一些能够跳过NA值的字符串操作方法,通过Series的str属性就可以访问这些方法。
In [94]: data.str.contains('gmail')
Out[94]:
Dave False
Rob True
Steve True
Web NaN
dtype: object
In [95]: pattern='([A-Z0-9._%+-]+)@([A-Z0-9._]+)\\.([A-Z]{2,4})'
In [97]: data.str.findall(pattern,flags=re.IGNORECASE)
Out[97]:
Dave [(dave, google, com)]
Rob [(rob, gmail, com)]
Steve [(steve, gmail, com)]
Web NaN
dtype: object
#两个方法可以实习矢量化,使用str.get或者在str属性上面使用索引
In [98]: matches=data.str.match(pattern,flags=re.IGNORECASE)
__main__:1: FutureWarning: In future versions of pandas, match will change to always return a bool indexer.
In [99]: matches
Out[99]:
Dave (dave, google, com)
Rob (rob, gmail, com)
Steve (steve, gmail, com)
Web NaN
dtype: object
In [100]: matches.str.get(1)
Out[100]:
Dave google
Rob gmail
Steve gmail
Web NaN
dtype: object
In [101]: matches.str[0]
Out[101]:
Dave dave
Rob rob
Steve steve
Web NaN
dtype: object
#对字符串进行截取
In [102]: data.str[:5]
Out[102]:
Dave dave@
Rob rob@g
Steve steve
Web NaN
dtype: object

7.5 示例:USDA视频数据库
In [219]: import numpy as np
...: import pandas as pd
...: from pandas import Series,DataFrame
...: import matplotlib.pyplot as plt
...: import json
...: import re
#加载json数据
In [220]: db=json.load(open(r"F:\pydata-book-master\ch07\foods-2011-10-03.json"))
...: len(db)
Out[220]: 6636
#查看db这个数据里面有多少个keys
In [221]: db[0].keys()
Out[221]:
[u'portions',
u'description',
u'tags',
u'nutrients',
u'group',
u'id',
u'manufacturer']
#对其中的nutrients单独显示
In [222]: db[0]['nutrients'][0]
...:
Out[222]:
{u'description': u'Protein',
u'group': u'Composition',
u'units': u'g',
u'value': 25.18}
In [223]: nutrients=DataFrame(db[0]['nutrients'])
...:
In [224]: nutrients[:7]
...:
Out[224]:
description group units value
0 Protein Composition g 25.18
1 Total lipid (fat) Composition g 29.20
2 Carbohydrate, by difference Composition g 3.06
3 Ash Other g 3.28
4 Energy Energy kcal 376.00
5 Water Composition g 39.28
6 Energy Energy kJ 1573.00
#我们将取出食物名称,分类,编号和制造商信息
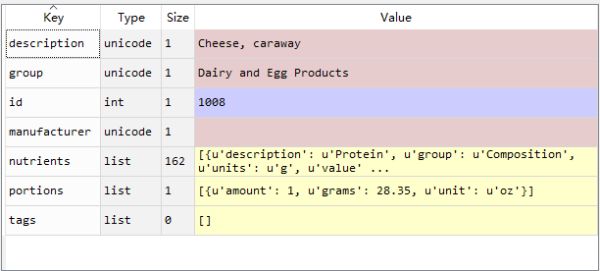
In [225]: info_keys=['description','group','id','manufacturer']
...: info=DataFrame(db,columns=info_keys)
...: info[:5]
...:
Out[225]:
description group id \
0 Cheese, caraway Dairy and Egg Products 1008
1 Cheese, cheddar Dairy and Egg Products 1009
2 Cheese, edam Dairy and Egg Products 1018
3 Cheese, feta Dairy and Egg Products 1019
4 Cheese, mozzarella, part skim milk Dairy and Egg Products 1028
manufacturer
0
1
2
3
4
#查看食物分类情况
In [226]: pd.value_counts(info.group)[:10]
...:
Out[226]:
Vegetables and Vegetable Products 812
Beef Products 618
Baked Products 496
Breakfast Cereals 403
Legumes and Legume Products 365
Fast Foods 365
Lamb, Veal, and Game Products 345
Sweets 341
Fruits and Fruit Juices 328
Pork Products 328
Name: group, dtype: int64
#为nutrients添加一列id
In [227]: nutrients = []
...:
...: for rec in db:
...: fnuts = DataFrame(rec['nutrients'])
...: fnuts['id'] = rec['id'] #广播
...: nutrients.append(fnuts)
...:
...:
...: nutrients = pd.concat(nutrients,ignore_index = True)
In [228]: nutrients[:5]
...:
Out[228]:
description group units value id
0 Protein Composition g 25.18 1008
1 Total lipid (fat) Composition g 29.20 1008
2 Carbohydrate, by difference Composition g 3.06 1008
3 Ash Other g 3.28 1008
4 Energy Energy kcal 376.00 1008
#检查重复的列
In [229]: nutrients.duplicated().sum()
...:
Out[229]: 14179
#直接丢弃重复的数据
In [230]: nutrients=nutrients.drop_duplicates()
...: nutrients.duplicated().sum()
Out[230]: 0
In [231]: col_mapping={'description':'food','group':'fgroup'}
...: info=info.rename(columns=col_mapping,copy=False)
...: info[:5]
Out[231]:
food fgroup id \
0 Cheese, caraway Dairy and Egg Products 1008
1 Cheese, cheddar Dairy and Egg Products 1009
2 Cheese, edam Dairy and Egg Products 1018
3 Cheese, feta Dairy and Egg Products 1019
4 Cheese, mozzarella, part skim milk Dairy and Egg Products 1028
manufacturer
0
1
2
3
4
In [232]: col_mapping={'description':'nutrient','group':'nutgroup'}
...: nutrients=nutrients.rename(columns=col_mapping,copy=False)
...: nutrients[:5]
Out[232]:
nutrient nutgroup units value id
0 Protein Composition g 25.18 1008
1 Total lipid (fat) Composition g 29.20 1008
2 Carbohydrate, by difference Composition g 3.06 1008
3 Ash Other g 3.28 1008
4 Energy Energy kcal 376.00 1008
#将col_mapping和ifo两个表合并起来
In [233]: ndata=pd.merge(nutrients,info,on='id',how='outer')
...: len(ndata)
Out[233]: 375176
In [234]: ndata[:5]
...:
Out[234]:
nutrient nutgroup units value id \
0 Protein Composition g 25.18 1008
1 Total lipid (fat) Composition g 29.20 1008
2 Carbohydrate, by difference Composition g 3.06 1008
3 Ash Other g 3.28 1008
4 Energy Energy kcal 376.00 1008
food fgroup manufacturer
0 Cheese, caraway Dairy and Egg Products
1 Cheese, caraway Dairy and Egg Products
2 Cheese, caraway Dairy and Egg Products
3 Cheese, caraway Dairy and Egg Products
4 Cheese, caraway Dairy and Egg Products
In [235]: ndata.ix[30000]
...:
Out[235]:
nutrient Glycine
nutgroup Amino Acids
units g
value 0.04
id 6158
food Soup, tomato bisque, canned, condensed
fgroup Soups, Sauces, and Gravies
manufacturer
Name: 30000, dtype: object
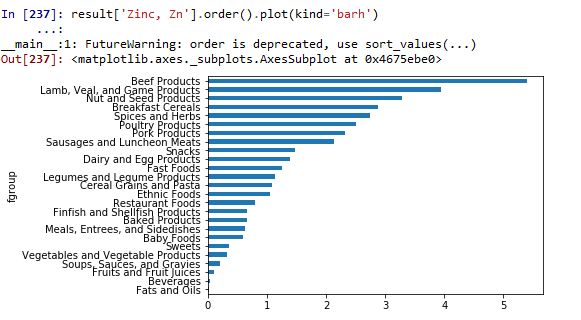
In [236]: result=ndata.groupby(['nutrient','fgroup'])['value'].quantile(0.5)
...:
In [237]: result['Zinc, Zn'].order().plot(kind='barh')
...:
__main__:1: FutureWarning: order is deprecated, use sort_values(...)
Out[237]:
In [238]: by_nutrient=ndata.groupby(['nutgroup','nutrient'])
...:
In [239]: get_maximum=lambda x: x.xs(x.value.idxmax())
...: get_minimum=lambda x: x.xs(x.value.idxmin())
In [240]: max_foods=by_nutrient.apply(get_maximum)[['value','food']]
...:
#让food小一点
In [241]: max_foods.food=max_foods.food.str[:50]
...:
In [242]: max_foods.ix['Amino Acids']['food']
...:
Out[242]:
nutrient
Alanine Gelatins, dry powder, unsweetened
Arginine Seeds, sesame flour, low-fat
Aspartic acid Soy protein isolate
Cystine Seeds, cottonseed flour, low fat (glandless)
Glutamic acid Soy protein isolate
Glycine Gelatins, dry powder, unsweetened
Histidine Whale, beluga, meat, dried (Alaska Native)
Hydroxyproline KENTUCKY FRIED CHICKEN, Fried Chicken, ORIGINA...
Isoleucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Leucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Lysine Seal, bearded (Oogruk), meat, dried (Alaska Na...
Methionine Fish, cod, Atlantic, dried and salted
Phenylalanine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Proline Gelatins, dry powder, unsweetened
Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Name: food, dtype: object