
一、Druid是什么
Druid 单词来源于西方古罗马的神话人物,中文常常翻译成德鲁伊。
玩过魔兽世界,暗黑破坏神,Dota,炉石传说,Dota自走棋的朋友,对这个词一定不陌生。
本文中所介绍的Druid是一个分布式的支持实时分析的数据存储系统。通俗一点:高性能实时分析数据库。它由美国广告技术公司MetaMarkets于2011年创建,并且于2012年开源。MetaMarkets是一家专门为在线媒体公司提供数据服务的公司,主营是DSP广告运营推送平台,由于对实时性要求非常高,公司不得不放弃原始的大数据方案,Druid也就应运而生。
Druid的官方网站地址是:http://druid.io/
目前Druid已基于Apache License 2.0协议开源,正在由Apache孵化,代码托管于Github。
最新官网地址为:
https://druid.apache.org/
阿里曾开源过一个项目叫做Druid是一个数据库连接池。与本文所述Driud只是名字相同,并没有什么联系,Github上两者都有相应的版本库。
本文说的Druid是Apache Druid
Github地址:https://github.com/apache/druid/ 已经有9k+star 最新release版本已经到0.17 正处于上升期。
二、Druid特性与基本概念
Druid主要解决的问题就是传统数据库无法解决的大数据量查询性能的问题。
所以她的本质就是一个分布式支持实时数据分析的数据存储系统。
能够快速的实现查询与数据分析,高可用,高扩展能力。
特性
1.快速查询:druid提供了快速的聚合能力以及快速OLAP查询能力,多租户的设计,是面向用户分析应用的理想方式。druid的数据聚合粒度可以是1分钟,5分钟,1小时或者1天等。数据的内存化提高了druid的查询速度。
OLAP:与之相对的是OLTP,这里通过一个在线商城举例,比如在一个在线商城中两者都是做什么呢?
- OLTP就是商品浏览,交易,用户数据。必须支持事务,频繁查询修改。 OLTP(联机事务处理),传统数据库的主要应用,面向最基本的CRUD操作,特点是实时性高,数据量小,可以修改删除数据,要求有严格的事务。
- OLAP就是对商城数据进行分析,数据量大。 OLAP(联机分析处理),支持复杂的分析操作,对决策的支持,特点是数据量大,吞吐量大,只支持查询。
2.实时数据注入:druid支持流数据的注入,并提供了数据的事件驱动,保证在实时和离线环境下事件的实效性和统一性。历史数据不改变,实时数据实时接入。
3.可扩展的PB级存储:druid集群可以很方便的扩容到PB的数据量,每秒百万级别的数据注入。即便在加大数据规模的情况下,也能保证时其效性。druid可以按照时间范围把聚合数据进行分区处理。
4.多环境部署:druid既可以运行在商业的硬件上,也可以运行在云上。它可以从多种数据系统中注入数据,包括hadoop,spark,kafka,storm和samza等。
5.丰富的社区:druid拥有丰富的社区,供大家学习。
Metamarkets之前几个druid开发者成立了一家叫做imply.io的新公司:https://imply.io/
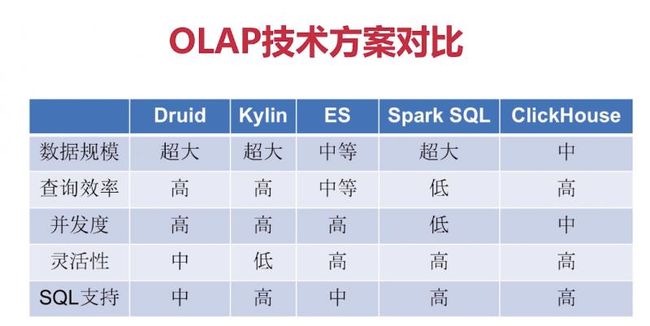
Druid与其他OLAP方案对比:
使用场景
根据Druid的特性可知,druid适合的场景:
查询多修改很少
查询以聚合或分组为主
快速查询
需要支持离线和实时的数据源
由此可见Druid在实时计算中,作为实时报表和实时大屏的查询环节非常的合适。
而且druid具有非常好的性能:
高扩展使用列式存储的分布式系统;高容错,自平衡,保证查询延迟和数据完整性;自动聚合,索引数据,提供多种算法优化查询效率。
所以druid中一般保存的是聚合后的数据。
基本概念
1、数据格式
druid在数据摄入之前,首先需要定义一个数据源也就是Datasource,这个dataSource的结构是 时间列(TimeStamp),维度列(Dimension)和指标列(Metric)。
时间列:druid会将时间相近的一些数据聚合在一起,查询的时候指定时间范围。
维度列:作为标识一些统计的维度,比如各种类型。
指标列:就是用于聚合和计算的列,包括count,sum等等。
2、数据摄入
druid提供了两种数据摄入方式,实时和批处理。
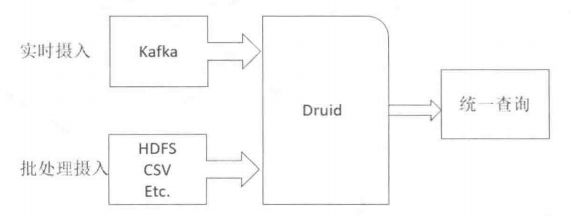
3、数据查询
druid支持两种查询,原生和sql
sql查询大同小异
[ EXPLAIN PLAN FOR ]
[ WITH tableName [ ( column1, column2, ... ) ] AS ( query ) ]
SELECT [ ALL | DISTINCT ] { * | exprs }
FROM table
[ WHERE expr ]
[ GROUP BY exprs ]
[ HAVING expr ]
[ ORDER BY expr [ ASC | DESC ], expr [ ASC | DESC ], ... ]
[ LIMIT limit ]
[ UNION ALL ] druid的原生查询采用json方式,通过http传送。
一个druid查询groupby的例子,指定了时间范围,聚合粒度,数据源等。
{
"queryType": "groupBy",
"dataSource": "sample_datasource",
"granularity": "day",
"dimensions": ["country", "device"],
"limitSpec": { "type": "default", "limit": 5000, "columns": ["country", "data_transfer"] },
"filter": {
"type": "and",
"fields": [
{ "type": "selector", "dimension": "carrier", "value": "AT&T" },
{ "type": "or",
"fields": [
{ "type": "selector", "dimension": "make", "value": "Apple" },
{ "type": "selector", "dimension": "make", "value": "Samsung" }
]
}
]
},
"aggregations": [
{ "type": "longSum", "name": "total_usage", "fieldName": "user_count" },
{ "type": "doubleSum", "name": "data_transfer", "fieldName": "data_transfer" }
],
"postAggregations": [
{ "type": "arithmetic",
"name": "avg_usage",
"fn": "/",
"fields": [
{ "type": "fieldAccess", "fieldName": "data_transfer" },
{ "type": "fieldAccess", "fieldName": "total_usage" }
]
}
],
"intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ],
"having": {
"type": "greaterThan",
"aggregation": "total_usage",
"value": 100
}
}三、应用场景
druid常见应用领域包括:
- 点击流分析(网络和移动分析)
- 风险/欺诈分析
- 网络遥测分析(网络性能监控)
- 服务器指标存储
- 供应链分析(制造指标)
- 应用程序性能指标
- 商业智能/ OLAP
用户行为分析
Druid可以用于,点击流,视图流,活动流。
准确地和近似地计算用户指标,计算出日常活动用户之类的平均指标,以查看总体趋势,或者精确计算以呈现给运营部门。
数字营销
Druid常用于存储和查询在线广告数据。这些数据通常来自广告服务器,对于衡量和了解广告系列的效果,点击率,转化率(损耗率)等等。
OLAP和BI
Druid通常用于BI,与Hive之类的SQL-on-Hadoop引擎不同,Druid专为高并发性和亚秒级查询而设计,可通过UI进行交互式数据探索。
总之,在实时计算应用越来越广泛的今天,druid将凭借着她的高性能和OLAP的优势,在实时的BI已经大屏等领域大放异彩!
静下心来,努力的提升自己,永远都没有错。更多实时计算相关博文,欢迎关注实时流式计算
