关于flink的任务执行架构,官网的这两张图就是最好的说明:
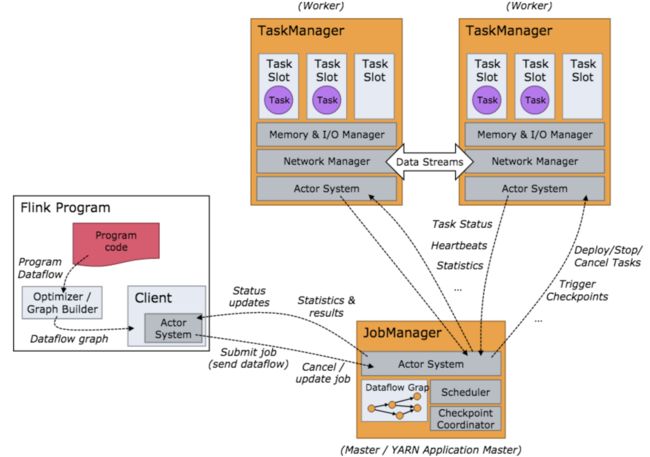
Flink 集群启动后,首先会启动一个 JobManger 和多个的 TaskManager。用户的代码会由JobClient 提交给 JobManager,JobManager 再把来自不同用户的任务发给 不同的TaskManager 去执行,每个TaskManager管理着多个task,task是执行计算的最小结构, TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述除了task外的三者均为独立的 JVM 进程。
要注意的是,TaskManager和job并非一一对应的关系。flink调度的最小单元是task而非TaskManager,也就是说,来自不同job的不同task可能运行于同一个TaskManager的不同线程上。

一个flink任务所有可能的状态如上图所示。图上画的很明白,就不再赘述了。
计算资源的调度
Task slot是一个TaskManager内资源分配的最小载体,代表了一个固定大小的资源子集,每个TaskManager会将其所占有的资源平分给它的slot。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输,也能共享一些数据结构,一定程度上减少了每个task的消耗。
每个slot可以接受单个task,也可以接受多个连续task组成的pipeline,如下图所示,FlatMap函数占用一个taskslot,而key Agg函数和sink函数共用一个taskslot:

为了达到共用slot的目的,除了可以以chain的方式pipeline算子,我们还可以允许SlotSharingGroup,如下图所示:
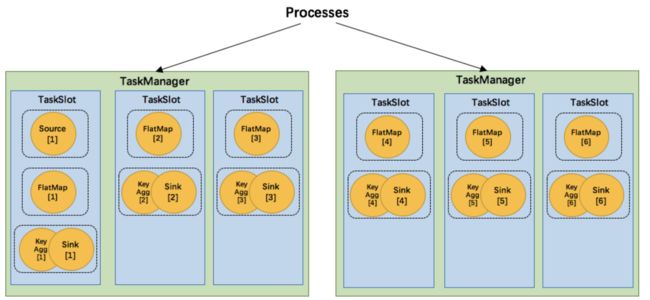
我们可以把不能被chain成一条的两个操作如flatmap和key&sink放在一个TaskSlot里执行,这样做可以获得以下好处:
- 共用slot使得我们不再需要计算每个任务需要的总task数目,直接取最高算子的并行度即可
- 对计算资源的利用率更高。例如,通常的轻量级操作map和重量级操作Aggregate不再分别需要一个线程,而是可以在同一个线程内执行,而且对于slot有限的场景,我们可以增大每个task的并行度了。
接下来我们还是用官网的图来说明flink是如何重用slot的:

- TaskManager1分配一个SharedSlot0
- 把source task放入一个SimpleSlot0,再把该slot放入SharedSlot0
- 把flatmap task放入一个SimpleSlot1,再把该slot放入SharedSlot0
- 因为我们的flatmap task并行度是2,因此不能再放入SharedSlot0,所以向TaskMange21申请了一个新的
SharedSlot0 - 把第二个flatmap task放进一个新的SimpleSlot,并放进TaskManager2的SharedSlot0
- 开始处理key&sink task,因为其并行度也是2,所以先把第一个task放进TaskManager1的SharedSlot
- 把第二个key&sink放进TaskManager2的SharedSlot
JobManager执行job
JobManager负责接收 flink 的作业,调度 task,收集 job 的状态、管理 TaskManagers。被实现为一个 akka actor。
JobManager的组件
- BlobServer 是一个用来管理二进制大文件的服务,比如保存用户上传的jar文件,该服务会将其写到磁盘上。还有一些相关的类,如BlobCache,用于TaskManager向JobManager下载用户的jar文件
- InstanceManager 用来管理当前存活的TaskManager的组件,记录了TaskManager的心跳信息等
- CompletedCheckpointStore 用于保存已完成的checkpoint相关信息,持久化到内存中或者zookeeper上
- MemoryArchivist 保存了已经提交到flink的作业的相关信息,如JobGraph等
JobManager的启动过程
先列出JobManager启动的核心代码:
def runJobManager(
configuration: Configuration,
executionMode: JobManagerMode,
listeningAddress: String,
listeningPort: Int)
: Unit = {
val numberProcessors = Hardware.getNumberCPUCores()
val futureExecutor = Executors.newScheduledThreadPool(
numberProcessors,
new ExecutorThreadFactory("jobmanager-future"))
val ioExecutor = Executors.newFixedThreadPool(
numberProcessors,
new ExecutorThreadFactory("jobmanager-io"))
val timeout = AkkaUtils.getTimeout(configuration)
// we have to first start the JobManager ActorSystem because this determines the port if 0
// was chosen before. The method startActorSystem will update the configuration correspondingly.
val jobManagerSystem = startActorSystem(
configuration,
listeningAddress,
listeningPort)
val highAvailabilityServices = HighAvailabilityServicesUtils.createHighAvailabilityServices(
configuration,
ioExecutor,
AddressResolution.NO_ADDRESS_RESOLUTION)
val metricRegistry = new MetricRegistryImpl(
MetricRegistryConfiguration.fromConfiguration(configuration))
metricRegistry.startQueryService(jobManagerSystem, null)
val (_, _, webMonitorOption, _) = try {
startJobManagerActors(
jobManagerSystem,
configuration,
executionMode,
listeningAddress,
futureExecutor,
ioExecutor,
highAvailabilityServices,
metricRegistry,
classOf[JobManager],
classOf[MemoryArchivist],
Option(classOf[StandaloneResourceManager])
)
} catch {
case t: Throwable =>
futureExecutor.shutdownNow()
ioExecutor.shutdownNow()
throw t
}
// block until everything is shut down
jobManagerSystem.awaitTermination()
.......
}
- 配置Akka并生成ActorSystem,启动JobManager
- 启动HA和metric相关服务
- 在startJobManagerActors()方法中启动JobManagerActors,以及webserver,TaskManagerActor,ResourceManager等等
- 阻塞等待终止
- 集群通过LeaderService等选出JobManager的leader
JobManager启动Task
override def handleMessage: Receive = {
case GrantLeadership(newLeaderSessionID) =>
log.info(s"JobManager $getAddress was granted leadership with leader session ID " +
s"$newLeaderSessionID.")
leaderSessionID = newLeaderSessionID
.......
有几个比较重要的消息:
- GrantLeadership 获得leader授权,将自身被分发到的 session id 写到 zookeeper,并恢复所有的 jobs
- RevokeLeadership 剥夺leader授权,打断清空所有的 job 信息,但是保留作业缓存,注销所有的 TaskManagers
- RegisterTaskManagers 注册 TaskManager,如果之前已经注册过,则只给对应的 Instance 发送消息,否则启动注册逻辑:在 InstanceManager 中注册该 Instance 的信息,并停止 Instance BlobLibraryCacheManager 的端口【供下载 lib 包用】,同时使用 watch 监听 task manager 的存活
- SubmitJob 提交 jobGraph
最后一项SubmintJob就是我们要关注的,从客户端收到JobGraph,转换为ExecutionGraph并执行的过程。
private def submitJob(jobGraph: JobGraph, jobInfo: JobInfo, isRecovery: Boolean = false): Unit = {
......
executionGraph = ExecutionGraphBuilder.buildGraph(
executionGraph,
jobGraph,
flinkConfiguration,
futureExecutor,
ioExecutor,
scheduler,
userCodeLoader,
checkpointRecoveryFactory,
Time.of(timeout.length, timeout.unit),
restartStrategy,
jobMetrics,
numSlots,
blobServer,
log.logger)
......
if (leaderElectionService.hasLeadership) {
log.info(s"Scheduling job $jobId ($jobName).")
executionGraph.scheduleForExecution()
} else {
self ! decorateMessage(RemoveJob(jobId, removeJobFromStateBackend = false))
log.warn(s"Submitted job $jobId, but not leader. The other leader needs to recover " +
"this. I am not scheduling the job for execution.")
......
}
首先做一些准备工作,然后获取一个ExecutionGraph,判断是否是恢复的job,然后将job保存下来,并且通知客户端本地已经提交成功了,最后如果确认本JobManager是leader,则执行executionGraph.scheduleForExecution()方法,这个方法经过一系列调用,把每个ExecutionVertex传递给了Excution类的deploy方法:
public void deploy() throws JobException {
......
try {
// good, we are allowed to deploy
if (!slot.setExecutedVertex(this)) {
throw new JobException("Could not assign the ExecutionVertex to the slot " + slot);
}
// race double check, did we fail/cancel and do we need to release the slot?
if (this.state != DEPLOYING) {
slot.releaseSlot();
return;
}
if (LOG.isInfoEnabled()) {
LOG.info(String.format("Deploying %s (attempt #%d) to %s", vertex.getTaskNameWithSubtaskIndex(),
attemptNumber, getAssignedResourceLocation().getHostname()));
}
final TaskDeploymentDescriptor deployment = vertex.createDeploymentDescriptor(
attemptId,
slot,
taskState,
attemptNumber);
final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
final CompletableFuture submitResultFuture = taskManagerGateway.submitTask(deployment, timeout);
......
}
catch (Throwable t) {
markFailed(t);
ExceptionUtils.rethrow(t);
}
}
我们首先生成了一个TaskDeploymentDescriptor,然后交给了taskManagerGateway.submitTask()方法执行。接下来的部分,就属于TaskManager的范畴了。
TaskManager执行task
TaskManager的基本组件
TaskManager是flink中资源管理的基本组件,是所有执行任务的基本容器,提供了内存管理、IO管理、通信管理等一系列功能,本节对各个模块进行简要介绍。
- MemoryManager flink并没有把所有内存的管理都委托给JVM,因为JVM普遍存在着存储对象密度低、大内存时GC对系统影响大等问题。所以flink自己抽象了一套内存管理机制,将所有对象序列化后放在自己的MemorySegment上进行管理。MemoryManger涉及内容较多,将在后续章节进行继续剖析。
-
IOManager flink通过IOManager管理磁盘IO的过程,提供了同步和异步两种写模式,又进一步区分了block、buffer和bulk三种读写方式。
IOManager提供了两种方式枚举磁盘文件,一种是直接遍历文件夹下所有文件,另一种是计数器方式,对每个文件名以递增顺序访问。
在底层,flink将文件IO抽象为FileIOChannle,封装了底层实现。
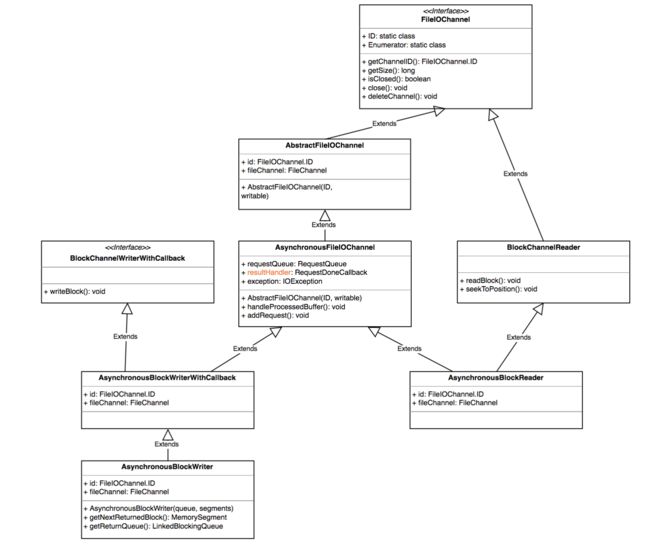
可以看到,flink在底层实际上都是以异步的方式进行读写。
- NetworkEnvironment 是TaskManager的网络 IO 组件,包含了追踪中间结果和数据交换的数据结构。它的构造器会统一将配置的内存先分配出来,抽象成 NetworkBufferPool 统一管理内存的申请和释放。意思是说,在输入和输出数据时,不管是保留在本地内存,等待chain在一起的下个操作符进行处理,还是通过网络把本操作符的计算结果发送出去,都被抽象成了NetworkBufferPool。后续我们还将对这个组件进行详细分析。
TaskManager执行Task
对于TM来说,执行task就是把收到的TaskDeploymentDescriptor对象转换成一个task并执行的过程。TaskDeploymentDescriptor这个类保存了task执行所必须的所有内容,例如序列化的算子,输入的InputGate和输出的ResultPartition的定义,该task要作为几个subtask执行等等。
按照正常逻辑思维,很容易想到TM的submitTask方法的行为:首先是确认资源,如寻找JobManager和Blob,而后建立连接,解序列化算子,收集task相关信息,接下来就是创建一个新的Task对象,这个task对象就是真正执行任务的关键所在。
val task = new Task(
jobInformation,
taskInformation,
tdd.getExecutionAttemptId,
tdd.getAllocationId,
tdd.getSubtaskIndex,
tdd.getAttemptNumber,
tdd.getProducedPartitions,
tdd.getInputGates,
tdd.getTargetSlotNumber,
tdd.getTaskStateHandles,
memoryManager,
ioManager,
network,
bcVarManager,
taskManagerConnection,
inputSplitProvider,
checkpointResponder,
blobCache,
libCache,
fileCache,
config,
taskMetricGroup,
resultPartitionConsumableNotifier,
partitionStateChecker,
context.dispatcher)
如果读者是从头开始看这篇blog,里面有很多对象应该已经比较明确其作用了(除了那个brVarManager,这个是管理广播变量的,广播变量是一类会被分发到每个任务中的共享变量)。接下来的主要任务,就是把这个task启动起来,然后报告说已经启动task了:
// all good, we kick off the task, which performs its own initialization
task.startTaskThread()
sender ! decorateMessage(Acknowledge.get())
生成Task对象
在执行new Task()方法时,第一步是把构造函数里的这些变量赋值给当前task的fields。
接下来是初始化ResultPartition和InputGate。这两个类描述了task的输出数据和输入数据。
for (ResultPartitionDeploymentDescriptor desc: resultPartitionDeploymentDescriptors) {
ResultPartitionID partitionId = new ResultPartitionID(desc.getPartitionId(), executionId);
this.producedPartitions[counter] = new ResultPartition(
taskNameWithSubtaskAndId,
this,
jobId,
partitionId,
desc.getPartitionType(),
desc.getNumberOfSubpartitions(),
desc.getMaxParallelism(),
networkEnvironment.getResultPartitionManager(),
resultPartitionConsumableNotifier,
ioManager,
desc.sendScheduleOrUpdateConsumersMessage());
//为每个partition初始化对应的writer
writers[counter] = new ResultPartitionWriter(producedPartitions[counter]);
++counter;
}
// Consumed intermediate result partitions
this.inputGates = new SingleInputGate[inputGateDeploymentDescriptors.size()];
this.inputGatesById = new HashMap<>();
counter = 0;
for (InputGateDeploymentDescriptor inputGateDeploymentDescriptor: inputGateDeploymentDescriptors) {
SingleInputGate gate = SingleInputGate.create(
taskNameWithSubtaskAndId,
jobId,
executionId,
inputGateDeploymentDescriptor,
networkEnvironment,
this,
metricGroup.getIOMetricGroup());
inputGates[counter] = gate;
inputGatesById.put(gate.getConsumedResultId(), gate);
++counter;
}
最后,创建一个Thread对象,并把自己放进该对象,这样在执行时,自己就有了自身的线程的引用。
运行Task对象
Task对象本身就是一个Runable,因此在其run方法里定义了运行逻辑。
第一步是切换Task的状态:
while (true) {
ExecutionState current = this.executionState;
////如果当前的执行状态为CREATED,则将其设置为DEPLOYING状态
if (current == ExecutionState.CREATED) {
if (transitionState(ExecutionState.CREATED, ExecutionState.DEPLOYING)) {
// success, we can start our work
break;
}
}
//如果当前执行状态为FAILED,则发出通知并退出run方法
else if (current == ExecutionState.FAILED) {
// we were immediately failed. tell the TaskManager that we reached our final state
notifyFinalState();
if (metrics != null) {
metrics.close();
}
return;
}
//如果当前执行状态为CANCELING,则将其修改为CANCELED状态,并退出run
else if (current == ExecutionState.CANCELING) {
if (transitionState(ExecutionState.CANCELING, ExecutionState.CANCELED)) {
// we were immediately canceled. tell the TaskManager that we reached our final state
notifyFinalState();
if (metrics != null) {
metrics.close();
}
return;
}
}
//否则说明发生了异常
else {
if (metrics != null) {
metrics.close();
}
throw new IllegalStateException("Invalid state for beginning of operation of task " + this + '.');
}
}
接下来,就是导入用户类加载器并加载用户代码。
然后,是向网络管理器注册当前任务(flink的各个算子在运行时进行数据交换需要依赖网络管理器),分配一些缓存以保存数据
然后,读入指定的缓存文件。
然后,再把task创建时传入的那一大堆变量用于创建一个执行环境Envrionment。
再然后,对于那些并不是第一次执行的task(比如失败后重启的)要恢复其状态。
接下来最重要的是
invokable.invoke();
方法。为什么这么说呢,因为这个方法就是用户代码所真正被执行的入口。比如我们写的什么new MapFunction()的逻辑,最终就是在这里被执行的。这里说一下这个invokable,这是一个抽象类,提供了可以被TaskManager执行的对象的基本抽象。
这个invokable是在解析JobGraph的时候生成相关信息的,并在此处形成真正可执行的对象
// now load the task's invokable code
//通过反射生成对象
invokable = loadAndInstantiateInvokable(userCodeClassLoader, nameOfInvokableClass);
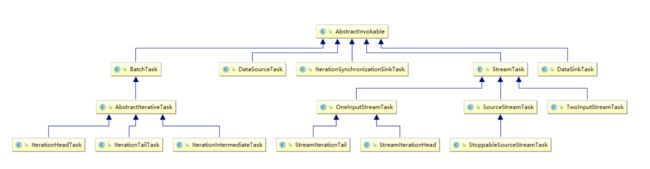
上图显示了flink提供的可被执行的Task类型。从名字上就可以看出各个task的作用,在此不再赘述。
接下来就是invoke方法了,因为我们的wordcount例子用了流式api,在此我们以StreamTask的invoke方法为例进行说明。
StreamTask的执行逻辑
先上部分核心代码:
public final void invoke() throws Exception {
boolean disposed = false;
try {
// -------- Initialize ---------
//先做一些赋值操作
......
// if the clock is not already set, then assign a default TimeServiceProvider
//处理timer
if (timerService == null) {
ThreadFactory timerThreadFactory =
new DispatcherThreadFactory(TRIGGER_THREAD_GROUP, "Time Trigger for " + getName());
timerService = new SystemProcessingTimeService(this, getCheckpointLock(), timerThreadFactory);
}
//把之前JobGraph串起来的chain的信息形成实现
operatorChain = new OperatorChain<>(this);
headOperator = operatorChain.getHeadOperator();
// task specific initialization
//这个init操作的起名非常诡异,因为这里主要是处理算子采用了自定义的checkpoint检查机制的情况,但是起了一个非常大众脸的名字
init();
// save the work of reloading state, etc, if the task is already canceled
if (canceled) {
throw new CancelTaskException();
}
// -------- Invoke --------
LOG.debug("Invoking {}", getName());
// we need to make sure that any triggers scheduled in open() cannot be
// executed before all operators are opened
synchronized (lock) {
// both the following operations are protected by the lock
// so that we avoid race conditions in the case that initializeState()
// registers a timer, that fires before the open() is called.
//初始化操作符状态,主要是一些state啥的
initializeState();
//对于富操作符,执行其open操作
openAllOperators();
}
// final check to exit early before starting to run
f (canceled) {
throw new CancelTaskException();
}
// let the task do its work
//真正开始执行的代码
isRunning = true;
run();
StreamTask.invoke()方法里,第一个值得一说的是TimerService。Flink在2015年决定向StreamTask类加入timer service的时候解释到:
This integrates the timer as a service in StreamTask that StreamOperators can use by calling a method on the StreamingRuntimeContext. This also ensures that the timer callbacks can not be called concurrently with other methods on the StreamOperator. This behaviour is ensured by an ITCase.
第二个要注意的是chain操作。前面提到了,flink会出于优化的角度,把一些算子chain成一个整体的算子作为一个task来执行。比如wordcount例子中,Source和FlatMap算子就被chain在了一起。在进行chain操作的时候,会设定头节点,并且指定输出的RecordWriter。
接下来不出所料仍然是初始化,只不过初始化的对象变成了各个operator。如果是有checkpoint的,那就从state信息里恢复,不然就作为全新的算子处理。从源码中可以看到,flink针对keyed算子和普通算子做了不同的处理。keyed算子在初始化时需要计算出一个group区间,这个区间的值在整个生命周期里都不会再变化,后面key就会根据hash的不同结果,分配到特定的group中去计算。顺便提一句,flink的keyed算子保存的是对每个数据的key的计算方法,而非真实的key,用户需要自己保证对每一行数据提供的keySelector的幂等性。至于为什么要用KeyGroup的设计,这就牵扯到扩容的范畴了,将在后面的章节进行讲述。
对于openAllOperators()方法,就是对各种RichOperator执行其open方法,通常可用于在执行计算之前加载资源。
最后,run方法千呼万唤始出来,该方法经过一系列跳转,最终调用chain上的第一个算子的run方法。在wordcount的例子中,它最终调用了SocketTextStreamFunction的run,建立socket连接并读入文本。
StreamTask与StreamOperator
前面提到,Task对象在执行过程中,把执行的任务交给了StreamTask这个类去执行。在我们的wordcount例子中,实际初始化的是OneInputStreamTask的对象(参考上面的类图)。那么这个对象是如何执行用户的代码的呢?
protected void run() throws Exception {
// cache processor reference on the stack, to make the code more JIT friendly
final StreamInputProcessor inputProcessor = this.inputProcessor;
while (running && inputProcessor.processInput()) {
// all the work happens in the "processInput" method
}
}
它做的,就是把任务直接交给了InputProcessor去执行processInput方法。这是一个StreamInputProcessor的实例,该processor的任务就是处理输入的数据,包括用户数据、watermark和checkpoint数据等。我们先来看看这个processor是如何产生的:
public void init() throws Exception {
StreamConfig configuration = getConfiguration();
TypeSerializer inSerializer = configuration.getTypeSerializerIn1(getUserCodeClassLoader());
int numberOfInputs = configuration.getNumberOfInputs();
if (numberOfInputs > 0) {
InputGate[] inputGates = getEnvironment().getAllInputGates();
inputProcessor = new StreamInputProcessor<>(
inputGates,
inSerializer,
this,
configuration.getCheckpointMode(),
getCheckpointLock(),
getEnvironment().getIOManager(),
getEnvironment().getTaskManagerInfo().getConfiguration(),
getStreamStatusMaintainer(),
this.headOperator);
// make sure that stream tasks report their I/O statistics
inputProcessor.setMetricGroup(getEnvironment().getMetricGroup().getIOMetricGroup());
}
}
这是OneInputStreamTask的init方法,从configs里面获取StreamOperator信息,生成自己的inputProcessor。那么inputProcessor是如何处理数据的呢?我们接着跟进源码:
public boolean processInput() throws Exception {
if (isFinished) {
return false;
}
if (numRecordsIn == null) {
numRecordsIn = ((OperatorMetricGroup) streamOperator.getMetricGroup()).getIOMetricGroup().getNumRecordsInCounter();
}
//这个while是用来处理单个元素的(不要想当然以为是循环处理元素的)
while (true) {
//注意 1在下面
//2.接下来,会利用这个反序列化器得到下一个数据记录,并进行解析(是用户数据还是watermark等等),然后进行对应的操作
if (currentRecordDeserializer != null) {
DeserializationResult result = currentRecordDeserializer.getNextRecord(deserializationDelegate);
if (result.isBufferConsumed()) {
currentRecordDeserializer.getCurrentBuffer().recycle();
currentRecordDeserializer = null;
}
if (result.isFullRecord()) {
StreamElement recordOrMark = deserializationDelegate.getInstance();
//如果元素是watermark,就准备更新当前channel的watermark值(并不是简单赋值,因为有乱序存在),
if (recordOrMark.isWatermark()) {
// handle watermark
statusWatermarkValve.inputWatermark(recordOrMark.asWatermark(), currentChannel);
continue;
} else if (recordOrMark.isStreamStatus()) {
//如果元素是status,就进行相应处理。可以看作是一个flag,标志着当前stream接下来即将没有元素输入(idle),或者当前即将由空闲状态转为有元素状态(active)。同时,StreamStatus还对如何处理watermark有影响。通过发送status,上游的operator可以很方便的通知下游当前的数据流的状态。
// handle stream status
statusWatermarkValve.inputStreamStatus(recordOrMark.asStreamStatus(), currentChannel);
continue;
} else if (recordOrMark.isLatencyMarker()) {
//LatencyMarker是用来衡量代码执行时间的。在Source处创建,携带创建时的时间戳,流到Sink时就可以知道经过了多长时间
// handle latency marker
synchronized (lock) {
streamOperator.processLatencyMarker(recordOrMark.asLatencyMarker());
}
continue;
} else {
//这里就是真正的,用户的代码即将被执行的地方。从章节1到这里足足用了三万字,有点万里长征的感觉
// now we can do the actual processing
StreamRecord record = recordOrMark.asRecord();
synchronized (lock) {
numRecordsIn.inc();
streamOperator.setKeyContextElement1(record);
streamOperator.processElement(record);
}
return true;
}
}
}
//1.程序首先获取下一个buffer
//这一段代码是服务于flink的FaultTorrent机制的,后面我会讲到,这里只需理解到它会尝试获取buffer,然后赋值给当前的反序列化器
final BufferOrEvent bufferOrEvent = barrierHandler.getNextNonBlocked();
if (bufferOrEvent != null) {
if (bufferOrEvent.isBuffer()) {
currentChannel = bufferOrEvent.getChannelIndex();
currentRecordDeserializer = recordDeserializers[currentChannel];
currentRecordDeserializer.setNextBuffer(bufferOrEvent.getBuffer());
}
else {
// Event received
final AbstractEvent event = bufferOrEvent.getEvent();
if (event.getClass() != EndOfPartitionEvent.class) {
throw new IOException("Unexpected event: " + event);
}
}
}
else {
isFinished = true;
if (!barrierHandler.isEmpty()) {
throw new IllegalStateException("Trailing data in checkpoint barrier handler.");
}
return false;
}
}
}
到此为止,以上部分就是一个flink程序启动后,到执行用户代码之前,flink框架所做的准备工作。回顾一下:
- 启动一个环境
- 生成StreamGraph
- 注册和选举JobManager
- 在各节点生成TaskManager,并根据JobGraph生成对应的Task
- 启动各个task,准备执行代码
接下来,我们挑几个Operator看看flink是如何抽象这些算子的。