本博客是笔者在生产环境使用 Flink 遇到的 Checkpoint 相关故障后,整理输出,价值较高的 实战采坑记,本文会带你更深入的了解 Flink 实现增量 Checkpoint 的细节。
通过本文,你能 get 到以下知识:
- Flink Checkpoint 目录的清除策略
- 生产环境应该选择哪种清除策略
- 生产环境必须定期脚本清理 Checkpoint 和 Savepoint 目录
- RocksDB 增量 Checkpoint 实现原理
- 如何合理地删除 Checkpoint 目录?
- 通过解析 Flink Checkpoint 的元数据信息来合理清理 Checkpoint 信息
1. 故障背景
本次故障涉及到的知识面比较多,将从以下多个角度来详细描述。
1.1 Flink Checkpoint 目录的清除策略
如下图所示,红圈处的一行配置 env.getCheckpointConfig().enableExternalizedCheckpoints() 表示当 Flink 任务取消时,是否保留外部保存的 CheckPoint 信息。
参数有两种枚举,分别是:ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION 和 ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION。这两种枚举分别代表什么含义呢?看一下源码中的解释:
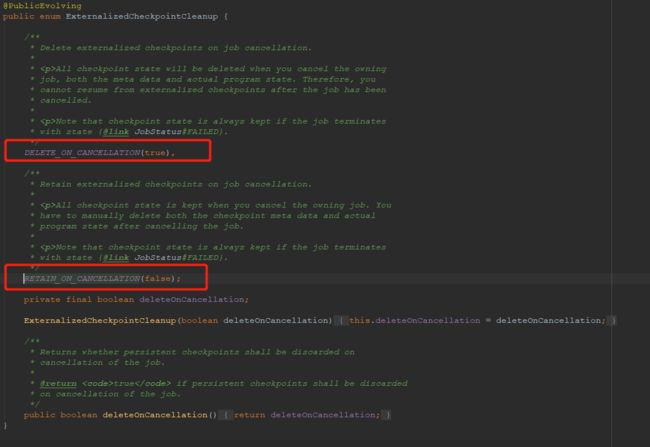
DELETE_ON_CANCELLATION:仅当作业失败时,作业的 Checkpoint 才会被保留用于任务恢复。当作业取消时,Checkpoint 状态信息会被删除,因此取消任务后,不能从 Checkpoint 位置进行恢复任务。
RETAIN_ON_CANCELLATION:当作业手动取消时,将会保留作业的 Checkpoint 状态信息。注意,这种情况下,需要手动清除该作业保留的 Checkpoint 状态信息,否则这些状态信息将永远保留在外部的持久化存储中。
无论是选择上述哪种方式,后面都提示了一句:如果 Flink 任务失败了,Checkpoint 的状态信息将被保留。
1.2 生产环境中,该参数应该配置为 DELETE_ON_CANCELLATION 还是 RETAIN_ON_CANCELLATION ?
在 Flink 任务运行过程中,为了保障故障容错,会定期进行 Checkpoint 将状态信息保存到外部存储介质中,当 Flink 任务由于各种原因出现故障时,Flink 任务会自动从 Checkpoint 处恢复,这就是 Checkpoint 的作用。Flink 中还有一个 Savepoint 的概念,Savepoint 与 Checkpoint 类似,同样需要把状态信息存储到外部介质,当作业失败时,可以从外部存储中恢复。Savepoint 与 Checkpoint 的区别如下表所示:
| Checkpoint | Savepoint |
|---|---|
| 由 Flink 的 JobManager 定时自动触发并管理 | 有用户手动触发并管理 |
| 主要用于任务发生故障时,为任务提供自动恢复机制 | 主要时用户升级Flink版本、修改任务的代码逻辑、调整算子并行度等,且必须手动恢复 |
| 当时用RocksDBStateBackend时,支持增量房是对状态信息进行快照 | 仅支持全量快照 |
| Flink任务停止后,Checkpoint的状态快照信息默认被清除 | 一旦触发 Savepoint,状态信息就被持久化到外部存储,除非用户手动删除 |
| Checkpoint 设计目标:轻量级且尽可能快地恢复任务 | Savepoint 的生成和恢复成本会更高一些,Savepoint 更多地关注代码的可移植性和兼容任务的更改操作 |
相比 Savepoint 而言,Checkpoint 更加轻量级,但有些场景 Checkpoint 并不能完全满足我们的需求。所以在使用过程中,如果我们的需求能使用 Checkpoint 来解决优先使用 Checkpoint。当 Flink 任务中的一些依赖组件需要升级重启时,例如 hdfs、Kafka、yarn 升级或者 Flink 任务的 Sink 端对应的 MySQL、Redis 由于某些原因需要重启时,Flink 任务在这段时间也需要重启。但是由于 Flink 任务的代码并没有修改,所以 Flink 任务启动时可以从 Checkpoint 处恢复任务。
如果 Checkpoint 目录的清除策略配置为 DELETE_ON_CANCELLATION,那么在取消任务时 Checkpoint 的状态信息会被清理掉,我们就无法通过 Checkpoint 来恢复任务了。为了从 Checkpoint 中轻量级地进行任务恢复,我们需要将该参数配置为 RETAIN_ON_CANCELLATION。
注:对于状态超过 100G 的 Flink 任务 ,笔者在生产环境验证过:每次从 Savepoint 恢复任务时需要耗时 10分钟以上,而 Checkpoint 可以在 2分钟以内恢复完成。充分说明了 Checkpoint 相比 SavePoint 而言,确实是轻量级的,所以 Checkpoint 能满足的业务场景强烈建议使用 Checkpoint 恢复任务,而不是使用 SavePoint。
1.3 必须定期脚本清理 Checkpoint 和 Savepoint 目录
假设任务运行对应的 jobId 为 A,job A 停止且重启后对应的 jobId 为 B,此时 A 对应的 Checkpoint 可能已经没用了,可以将其清理掉从而节省 hdfs 的存储空间。同学们可能想,不清理可以吗?当然可以,但是如果一直不清理就会占用 hdfs 存储空间。下图是笔者生产环境中两个状态比较大的任务,第一个任务的状态信息在 hdfs 三副本总共占用了 1 T,第二个任务的状态信息在 hdfs 三副本中总共占用了 700G。如果 Flink 任务经常重启,那么这些大状态的任务将会在 Checkpoint 目录下对应很多个 job 目录,将会把大状态任务存储很多份。假如 1 T 的任务保存了 5 份,那就是占用 5 T 的磁盘空间,但其实只需要保存一份全量数据就够了。因此必须有定期清理 Checkpoint 目录的策略。

在 1.1 Flink Checkpoint 目录的清除策略 部分,源码中专门提示:如果选择 RETAIN_ON_CANCELLATION 策略,需要手动清除该作业保留的 Checkpoint 状态信息,否则这些状态信息将永远保留在外部的持久化存储中。那如果选择了 DELETE_ON_CANCELLATION 策略,就可以不定期清理 Checkpoint 目录吗?错,也需要定期清理,源码中有写:无论配合何种策略,如果 Flink 任务失败了,Checkpoint 的状态信息将被保留。
简言之,Flink 任务重启或者失败后,Checkpoint 信息会保存在 hdfs,如果不手动定期清理,那么一年以后 Checkpoint 信息还会保存在 hdfs 上。请问一年后这个 Checkpoint 信息还有用吗?肯定没用了,完全是浪费存储资源。
Savepoint 也是同样的道理,可以把那些旧的不再会使用的状态信息定期清理掉。
1.4 哪些状态信息应该被清理掉?
必须要有清理策略,关键问题来了:如果来判断哪些状态信息不会再使用了?我们会认为:不会再使用的状态信息就是那些应该被清理掉的状态信息。
清理的判断依据
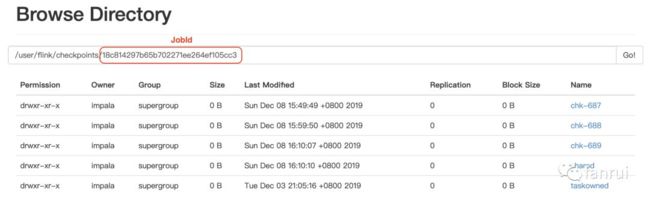
如下图所示,Flink 中配置了 Checkpoint 目录为:/user/flink/checkpoints,子目录名为 jobId 名。hdfs 的 api 可以拿到 jobId 目录最后修改的时间。对于一个正在运行的 Flink 任务,每次 Checkpoint 时 jobId 的 Checkpoint 目录最后修改时间会更新为当前时间。可以认为如果 jobId 对应的最后修改时间是 10 天之前,意味着这个 job 已经十天没有运行了。

对于 10 天没有运行的 job,我们会认为它已经重启了对应到其他新的 jobId,或者当前任务已经下线了。无论哪种情况,我们都认为 10 天没有运行的 job,它的 Checkpoint 目录也没有存在的意义了,应该被清理掉。
因此我们线上的清理策略就来了,定时每天调度一次,将那些最后修改时间是 10 天之前的 jobId 对应的 Checkpoint 目录清理掉。
故障出现了
就这么运行了 4 个月(专门看了清理策略上线时间),没出现过任何问题。突然在 12月3号晚上从 Checkpoint 位置重启某几个大状态任务时,突然起不来了,现象是这样的。
任务从 /user/flink/checkpoints/0165a1467c65a95a010f9c0134c9e576/chk-17052 目录恢复时,报出以下错误:
Caused by: java.io.FileNotFoundException: File does not exist: /user/flink/checkpoints/37c37bd26da17b2e6ac433866d51201d/shared/bdc46a09-fc2a-4290-af5c-02bd39e9a1ca
请注意一个重点,上述两个 hdfs 的目录不一样。简单描述故障现象是这样的:任务从 job A 的 Checkpoint 目录恢复,恢复后的 jobId 为 B,job B 并没有正常恢复,报错信息为在 hdfs 目录找不到 job C 的 Checkpoint 信息。解决问题的过程中是完全蒙的,手动去 hdfs 确认,发现 job A 的 Checkpoint 目录是存在的,非常纳闷:我的要从 job A 的 Checkpoint 处恢复任务,Flink 为什么要找 job C 的 Checkpoint 目录?甚至还怀疑是不是 hdfs 出问题了。。。摸爬滚打了一个小时,没找到根本原因,为了不发生事故,最后没有将任务从 Checkpoint 处恢复,选择了直接重启的方式。
2. 分析原因
简单描述就是:这次故障是因为 Flink 基于 RocksDB 的增量 Checkpoint 导致。不能怪 RocksDB 的增量 Checkpoint 导致我们故障,只能怪我们的清理策略没有实现闭环操作。闭环操作指清理 Checkpoint 信息时,应该有一个主动检测机制确保当前删除的 Checkpoint 信息 100% 已经没用了才能删除。而不应该凭借一个经验说 10 天过去了,应该没用了,所以去删除。
2.1 RocksDB 增量 Checkpoint 实现原理
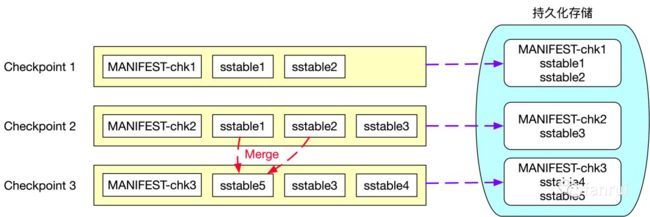
RocksDB 是一个基于 LSM 实现的 KV 数据库。LSM 全称 Log Structured Merge Trees,LSM 树本质是将大量的磁盘随机写操作转换成磁盘的批量写操作来极大地提升磁盘数据写入效率。一般 LSM Tree 实现上都会有一个基于内存的 MemTable 介质,所有的增删改操作都是写入到 MemTable 中,当 MemTable 足够大以后,将 MemTable 中的数据 flush 到磁盘中生成不可变且内部有序的 ssTable(Sorted String Table)文件,全量数据保存在磁盘的多个 ssTable 文件中。HBase 也是基于 LSM Tree 实现的,HBase 磁盘上的 HFile 就相当于这里的 ssTable 文件,每次生成的 HFile 都是不可变的而且内部有序的文件。基于 ssTable 不可变的特性,才实现了增量 Checkpoint,具体流程如下所示:

第一次 Checkpoint 时生成的状态快照信息包含了两个 sstable 文件:sstable1 和 sstable2 及 Checkpoint1 的元数据文件 MANIFEST-chk1,所以第一次 Checkpoint 时需要将 sstable1、sstable2 和 MANIFEST-chk1 上传到外部持久化存储中。第二次 Checkpoint 时生成的快照信息为 sstable1、sstable2、sstable3 及元数据文件 MANIFEST-chk2,由于 sstable 文件的不可变特性,所以状态快照信息的 sstable1、sstable2 这两个文件并没有发生变化,sstable1、sstable2 这两个文件不需要重复上传到外部持久化存储中,因此第二次 Checkpoint 时,只需要将 sstable3 和 MANIFEST-chk2 文件上传到外部持久化存储中即可。这里只将新增的文件上传到外部持久化存储,也就是所谓的增量 Checkpoint。
基于 LSM Tree 实现的数据库为了提高查询效率,都需要定期对磁盘上多个 sstable 文件进行合并操作,合并时会将删除的、过期的以及旧版本的数据进行清理,从而降低 sstable 文件的总大小。图中可以看到第三次 Checkpoint 时生成的快照信息为sstable3、sstable4、sstable5 及元数据文件 MANIFEST-chk3, 其中新增了 sstable4 文件且 sstable1 和 sstable2 文件合并成 sstable5 文件,因此第三次 Checkpoint 时只需要向外部持久化存储上传 sstable4、sstable5 及元数据文件 MANIFEST-chk3。
基于 RocksDB 的增量 Checkpoint 从本质上来讲每次 Checkpoint 时只将本次 Checkpoint 新增的快照信息上传到外部的持久化存储中,依靠的是 LSM Tree 中 sstable 文件不可变的特性。对 LSM Tree 感兴趣的同学可以深入研究 RocksDB 或 HBase 相关原理及实现。
2.2 为什么会出现 1.4 部分的故障呢?
如上图所示,job X 运行过程中,仅仅做了一次 Checkpoint,也就是图中的 Checkpoint 1。所以在 hdfs 上 job A 的 Checkpoint 目录中包含了 sstable1 和 sstable2。Checkpoint 1 之后由于某些原因任务挂了,所以任务从 Checkpoint 1 处恢复任务,恢复后的任务为 job Y。job Y 恢复后运行一段时间后进行第二次 Checkpoint,也就是图中的 Checkpoint 2,Checkpoint 2 包含了 MANIFEST-chk2、sstable1、sstable2 和 sstable3,由于使用的基于 RocksDB 的增量 Checkpoint,因此 Checkpoint 2 只需要将 MANIFEST-chk2 和 sstable3 上传到 hdfs 即可,此时 job Y 的 checkpoint 目录仅仅包含 sstable3,而 sstable1、sstable2 依然保存在 job X 的 Checkpoint 目录中。接着 job Y 继续运行,第三次 Checkpoint 时,新增了 sstable4 文件且 sstable1 和 sstable2 文件合并成 sstable5 文件,因此第三次 Checkpoint 时只需要向 hdfs 上传 sstable4、sstable5 及元数据文件 MANIFEST-chk3。
由于 job Y 运行一切良好,我就认为 job X 的 Checkpoint 信息已经没用了,为了节省 hdfs 存储空间,手动把 job X 的 Checkpoint 信息清理了。假设第三次 Checkpoint 后,任务突然需要重启,请问任务可以从 Checkpoint 3 恢复吗?当然可以,如图所示,Checkpoint 3 总共依赖 MANIFEST-chk3、sstable5、sstable3 和 sstable4,这四个文件都保存在了 job Y 的 Checkpoint 目录中,所以 job Y 可以正常恢复。那请问任务可以从 Checkpoint 2 恢复吗?NoNoNo!!!恢复不了,Checkpoint 2 包含了 MANIFEST-chk2、sstable1、sstable2 和 sstable3。其中 sstable1 和 sstable2 包含在 job X 的 Checkpoint 目录中,不好意思,我刚才把 job X 的 Checkpoint 全清理了。
所以大家明白为什么任务不能正常恢复了吗?虽然 job Y 任务已经启动了,但是 job Y 可能还会依赖 job X 的一些 Checkpoint 信息。我举的例子中,job Y 的 Checkpoint 3 已经不依赖 job X 了,但是在真实的生产环境中,job Y 进行了 100 次 Checkpoint 后可能还会依赖 job X 的 Checkpoint 信息。
图中所示的 merge 策略,完全依赖于 RocksDB 本身的合并策略,Flink 并不能主动控制。这里的 merge 操作就是 HBase 的 compact 操作,compact 操作就由外部的写入操作来自动触发的。如果遇到冷数据,经常不访问也不写入,那么合并操作可能会非常不频繁,所以并不能说 10 天过去了,RocksDB 中旧的 sstable 文件就肯定不需要了。
2.3 如何合理地删除 Checkpoint 目录?
由于合并操作完全依赖 RocksDB,所以时间策略肯定不靠谱。Checkpoint 的次数也不靠谱,不能说进行了 1000次 Checkpoint 了,第一次 Checkpoint 的 sstable 文件肯定已经被废弃了,还真有可能在使用,虽然几率很小。所以我们现在需要一个主动检测的策略,需要主动去发现,到底哪些 sstable 文件在使用呢?
笔者研究了 Flink Checkpoint 目录中的文件分布,发现 Checkpoint 过程中所有 sstable 文件都保存在当前 job Checkpoint 目录下的 shared 目录里。chk-689 表示第 689 次 Checkpoint,chk-689 目录下保存着本次 Checkpoint 的元数据信息及 OperatorState 的状态信息。
在 chk-689目录中有一个_metadata 命名的文件,这里存储着本次 Checkpoint 的元数据信息,元数据信息中存储了本次 Checkpoint 依赖哪些 sstable 文件并且 sstable 文件存储在 hdfs 的位置信息。所以只需要解析最近一次 Checkpoint 目录的元数据文件就可以知道当前的 job 依赖哪些 sstable 文件。原理分析清楚了,必须给大家分享解析元数据的源码。
// 读取元数据文件
File f=new File("module-flink/src/main/resources/_metadata");
//第二步,建立管道,FileInputStream文件输入流类用于读文件
FileInputStream fis=new FileInputStream(f);
BufferedInputStream bis = new BufferedInputStream(fis);
DataInputStream dis = new DataInputStream(bis);
// 通过 Flink 的 Checkpoints 类解析元数据文件
Savepoint savepoint = Checkpoints.loadCheckpointMetadata(dis,
MetadataSerializer.class.getClassLoader());
// 打印当前的 CheckpointId
System.out.println(savepoint.getCheckpointId());
// 遍历 OperatorState,这里的每个 OperatorState 对应一个 Flink 任务的 Operator 算子
// 不要与 OperatorState 和 KeyedState 混淆,不是一个层级的概念
for(OperatorState operatorState :savepoint.getOperatorStates()) {
System.out.println(operatorState);
// 当前算子的状态大小为 0 ,表示算子不带状态,直接退出
if(operatorState.getStateSize() == 0){
continue;
}
// 遍历当前算子的所有 subtask
for(OperatorSubtaskState operatorSubtaskState: operatorState.getStates()) {
// 解析 operatorSubtaskState 的 ManagedKeyedState
parseManagedKeyedState(operatorSubtaskState);
// 解析 operatorSubtaskState 的 ManagedOperatorState
parseManagedOperatorState(operatorSubtaskState);
}
}
/**
* 解析 operatorSubtaskState 的 ManagedKeyedState
* @param operatorSubtaskState operatorSubtaskState
*/
private static void parseManagedKeyedState(OperatorSubtaskState operatorSubtaskState) {
// 遍历当前 subtask 的 KeyedState
for(KeyedStateHandle keyedStateHandle:operatorSubtaskState.getManagedKeyedState()) {
// 本案例针对 Flink RocksDB 的增量 Checkpoint 引发的问题,
// 因此仅处理 IncrementalRemoteKeyedStateHandle
if(keyedStateHandle instanceof IncrementalRemoteKeyedStateHandle) {
// 获取 RocksDB 的 sharedState
Map sharedState =
((IncrementalRemoteKeyedStateHandle) keyedStateHandle).getSharedState();
// 遍历所有的 sst 文件,key 为 sst 文件名,value 为对应的 hdfs 文件 Handle
for(Map.Entry entry:sharedState.entrySet()){
// 打印 sst 文件名
System.out.println("sstable 文件名:" + entry.getKey());
if(entry.getValue() instanceof FileStateHandle) {
Path filePath = ((FileStateHandle) entry.getValue()).getFilePath();
// 打印 sst 文件对应的 hdfs 文件位置
System.out.println("sstable文件对应的hdfs位置:" + filePath.getPath());
}
}
}
}
}
/**
* 解析 operatorSubtaskState 的 ManagedOperatorState
* 注:OperatorState 不支持 Flink 的 增量 Checkpoint,因此本案例可以不解析
* @param operatorSubtaskState operatorSubtaskState
*/
private static void parseManagedOperatorState(OperatorSubtaskState operatorSubState) {
// 遍历当前 subtask 的 OperatorState
for(OperatorState operatorStateHandle:operatorSubState.getManagedOperatorState()) {
StreamStateHandle delegateState = operatorStateHandle.getDelegateStateHandle();
if(delegateState instanceof FileStateHandle) {
Path filePath = ((FileStateHandle) delegateStateHandle).getFilePath();
System.out.println(filePath.getPath());
}
}
}
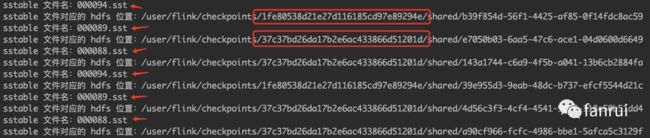
上述代码解析的是 jobId 为 1fe80538d21e27d116185cd97e89294e 任务的 Checkpoint 元数据信息,我们可以看到有很多的 sstable 文件,并且看到 sstable 文件既包含 jobId 为 1fe80538d21e27d116185cd97e89294e 的 Checkpoint 文件,也包含 jobId 为 37c37bd26da17b2e6ac433866d51201d 的 Checkpoint 文件,也就是说依赖了之前 job 的 Checkpoint 数据。所以 jobId 为 37c37bd26da17b2e6ac433866d51201d 的任务虽然结束了,但是由于后续任务还依赖它的 Checkpoint 信息,所以不能删除它的 Checkpoint 信息。
于是我们的清理 Checkpoint 的新策略来了,完全闭环的操作。删除元数据时加了检测,因此能保证清理的 Checkpoint 目录都是不可能再使用的目录。大功告成。
3. 总结
本博客来自于对一次 Flink 故障引发的思考,再次加深了对 Flink Checkpoint 相关的理解和认识。
参考:https://mp.weixin.qq.com/s/oh53V_IQwgrD_GPRht1F5A