作 者: 月牙眼的楼下小黑
联 系: zhanglf_tmac (Wechat)
声 明: 欢迎转载本文中的图片或文字,请说明出处
0. 动机
论文没有给出超参 batch_size ,我以 128 为界进行尝试。当我将batch_size 设置为 256 后,提示显存用尽。我们实验室服务器有 8 张卡,运气好我能占到 2 张卡,所以想尝试进行 multi-gpus training. 参考 pytorch 给出的官方教程: 【可选:数据并行】,依然踩了不少坑。
先查看一下我实验室的显卡使用情况:
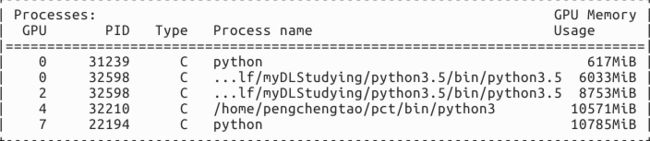
显卡0,2,4,7 都有人在跑实验,我们就用显卡 1,3 吧。设好目标后,我们来修改官方提供的例子。
1. 导入和参数
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
# 参数和数据加载
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
2. 伪数据集
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, 100),
batch_size=batch_size, shuffle=True)
修改: 将 rand_loader 中的初始化参数 100 修改为 data_size, 即:
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
3. 简单模型
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
4. 创建模型和 DataParallel
model = Model(input_size, output_size)
model = nn.DataParallel(model)
model = model.cuda()
修改: 基于对实验结果的观察, 多卡训练的基本过程是(可能不严谨):首先将模型加载到一个指定设备上作为 controller, 然后将模型 浅复制 到多个设备中,将 大batch 数据 也 等分 到不同设备中, 每个设备分配到不同的数据,然后将所有设备计算得到 梯度合并 用以更新 controller 模型的参数。
我们需要修改两个地方:
model = nn.DataParallel(model) 会将模型 浅复制 到 所有 可用的显卡中(如果是我实验室的服务器,就是复制到
8张卡中),我们希望只占用显卡1和3, 所以需要传入参数 device_ids=[1,3]model = model.cuda() 会将模型加载到
0号显卡并作为controller. 但是我们并不打算使用0号显卡。所以需要修改为:model = model.cuda(device_ids[0]), 即我们将模型加载1号显卡并作为controller。
综上,上面这段代码修改为:
model = Model(input_size, output_size)
model = nn.DataParallel(model,device_ids=[1,3])
model = model.cuda(device_ids[0])
5.运行模型
for data in rand_loader:
input_var = Variable(data.cuda())
output = model(input_var)
print("Outside: input size", input_var.size(),
"output_size", output.size())
修改:
这里也有一个大坑。input_var = Variable(data.cuda()) 会将整个 batch 数据加载到 0 号卡,显然需要修改。但是应该加载到哪呢 ? 上面我们已经把模型加载到 1 号卡并且作为 controller , 如果再把整个batch 的数据加载到 1 号卡,照理讲显存应该不够啊。一张卡不能同时放下模型和大batch的数据,这是在文首说明的进行多卡训练的动机啊。
于是我将数据加载到 3 号卡, 但是在前向传播时报错了:
all tensors should be in device[0]
也就是说我们需要先将数据加载到 1 号卡(起码在代码层是这样的,物理层就不清楚了)。
综上,将代码修改为:
for data in rand_loader:
if torch.cuda.is_available():
input_var = Variable(data.cuda(device[0]))
else:
input_var = Variable(data)
output = model(input_var)
print("Outside: input size", input_var.size(),
"output_size", output.size())
6. 结果
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
#-----------------------------------------------------------------------------------------
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
#-----------------------------------------------------------------------------------------
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
#-----------------------------------------------------------------------------------------
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
#-----------------------------------------------------------------------------------------
- 在 逻辑层
100 个数据被分成 4 批, 每批包含的样本数为 [30, 30, 30, 20], 不妨记为 batch0, batch1, batch2, batch3
- 在 物理层,
batch0 的数据在前向传播时, 被 等分 到显卡 1 和 3上, 不妨记为 batch00, batch01, 包含的样本数均为 30 ÷ 2 = 15
batch1 的数据在前向传播时, 被 等分 到显卡 1 和 3上, 不妨记为 batch10, batch11, 包含的样本数均为 30 ÷ 2 = 15
batch2 的数据在前向传播时, 被 等分 到显卡 1 和 3上, 不妨记为 batch20, batch21, 包含的样本数均为 30 ÷ 2 = 15
batch3 的数据在前向传播时, 被 等分 到显卡 1 和 3上, 不妨记为 batch30, batch31, 包含的样本数均为 20 ÷ 2 = 10.
7. 问题
我发现程序总是会占用0 号卡的固定量的显存(329 M),还没有找到问题的原因所在(估计跟 pytorch 版本有关,我用的是 0.3 版本)。

作 者: 月牙眼的楼下小黑
联 系: zhanglf_tmac (Wechat)
声 明: 欢迎转载本文中的图片或文字,请说明出处