摘要
本文是利用Python语言对Kaggle上Give Me Some Credit网贷数据集进行申请评分卡(a卡)的数据清洗,建模,熟悉评分卡构建流程。结合信贷评分卡原理,从数据预处理、建模分析、创建信用评分卡到建立自动评分机制,创立了一个简单的信用准入评分系统。并对建立基于AI 的机器学习评分卡系统的路径进行思考和总结。
工作原理
信用评分卡是一种成熟的预测方法,在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量利用WOE-IV编码离散化之后运用logistic回归模型进行的一种二分类广义线性模型。
评分卡由一系列特征组成,每个特征对应申请表上的一个数据(年龄、银行流水、收入等)。并且一个特征项都会存在一串属性(对于年龄这个问题,答案可能就有30岁以下、30到40岁等)。开发评分卡模型的过程中,必须先确定属性与申请人未来信用表现之间的相关关系,分配适当的权重分值。分值越大,说明该属性蕴含的信用表现越佳。而申请得分就是其分值的简单求和。一旦评分大于等于金融放款机构所设定的阈值,表示该申请人的风险水平是可接受的范围,可以被批准。
数据处理
载入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("bmh")
plt.rc('font', family='SimHei', size=13)
%matplotlib inline
import os
导入数据
data_train = pd.read_csv('cs-training.csv')
data_test = pd.read_csv('cs-test.csv')
探索性数据分析
特征解释:
data_train.info()

有缺失值的特征:MonthlyIncome,NumberOfDependents。
修改列名:
columns = ({'SeriousDlqin2yrs':'Label',
'RevolvingUtilizationOfUnsecuredLines':'Revol',
'NumberOfOpenCreditLinesAndLoans':'NumOpen',
'NumberOfTimes90DaysLate':'Num90late',
'NumberRealEstateLoansOrLines':'NumEstate',
'NumberOfTime60-89DaysPastDueNotWorse':'Num60-89late',
'NumberOfDependents':'NumDependents',
'NumberOfTime30-59DaysPastDueNotWorse':'Num30-59late'}
)
data_train.rename(columns=columns,inplace = True)
data_test.rename(columns=columns,inplace = True)
badrate
bad = data_train.loc[data_train['Label']==1].shape[0]
good = data_train.loc[data_train['Label']==0].shape[0]
print('badrate为:{:.2f}%'.format(round(bad*100/(good+bad),2)))
坏客户只占用户6.68%。
异常值探索
特征 年龄
年龄分布
f,[ax1,ax2]=plt.subplots(1,2,figsize=(20,6))
sns.distplot(data_train['age'],ax=ax1)
sns.boxplot(y='age',data=data_train,ax=ax2)
plt.show()
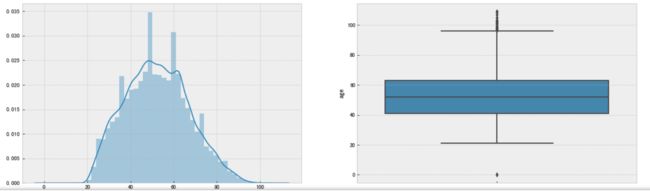
从图可以发现,年龄基本呈正态分布。
异常值处理:
处理数据异常值一般有:3倍标准差区分异常值、分箱四分位距区分异常值或者直接去除首尾各1%的数据这三种方法。
数据现在是处于正态分布,故采用3倍标准差去除异常。
data_train = data_train[data_train['age']!=0]
age_Mean = np.mean(data_train['age'])
age_Std = np.std(data_train['age'])
UpLimit = round((age_Mean + 3*age_Std),2)
DownLimit = round((age_Mean - 3*age_Std),2)
data_train = data_train[(data_train['age']>=DownLimit)&(data_train['age']<=UpLimit)]
观察年龄大小对label值的影响
##
#先做一个等距粗分箱
data_train['ageCat'] = np.nan
data_train.loc[(data_train['age']>18)&(data_train['age']<40),'ageCat'] = 1
data_train.loc[(data_train['age']>=40)&(data_train['age']<60),'ageCat'] = 2
data_train.loc[(data_train['age']>=60)&(data_train['age']<80),'ageCat'] = 3
data_train.loc[(data_train['age']>=80),'ageCat'] = 4
BadrateList = {}
for m in data_train['ageCat'].value_counts().index:
data = data_train.loc[data_train['ageCat']==m]
Badrate = data.loc[data['Label']==0].shape[0]/data.loc[data['Label']==1].shape[0]
BadrateList[m] = Badrate
BadrateList=dict(sorted(BadrateList.items(),key=lambda x:x[0]))
f,ax = plt.subplots(figsize=(8,5))
sns.countplot('ageCat', hue='Label', data=data_train, ax=ax)
ax2 = ax.twinx()
ax2.plot([x-1 for x in BadrateList.keys()], [round(x,2) for x in BadrateList.values()],'ro--',linewidth=2)

可以看到年龄越大,badrate越大,呈现单调性。为后面的等频分箱求WOE提供参考。
特征 Revol
该特征的意义是:除了房贷车贷之外的信用卡金额(即贷款金额额度)/信用卡总额度。即通常是小于等于1的,一般大于1是属于透支。
print(data_train['Revol'][data_train['Revol']>1].count())
print(data_train['Revol'].max())
print(data_train['Revol'].min())
3321
50708.0
0.0
特征值超过几万显然不太正常,估计很有可能是没有除以分母信用卡总额度,而是分子的纯信用卡账面贷款金额。
现在尝试确定属于透支的最大数字和异常值的范围:
#四分位距法
Percentile = np.percentile(data_train['Revol'],[0,25,50,75,100])
IQR = Percentile[3] - Percentile[1]
UpLimit = Percentile[3]+IQR*1.5
DownLimit = Percentile[1]-IQR*1.5
print('上限为:{0}, 下限为:{1}'.format(UpLimit,DownLimit))
print('上界异常值占比:{0}%'.format(round(data_train[data_train['Revol']>UpLimit].shape[0]*100/data_train.shape[0],2)))
上限为:1.3529709321249999, 下限为:-0.763938468875
上界异常值占比:0.51%
#分段观察Revol分布
f,[[ax1,ax2],[ax3,ax4]]=plt.subplots(2,2,figsize=(20,10))
sns.distplot(data_train['Revol'][data_train['Revol']<1],bins=10,ax=ax1)
sns.distplot(data_train['Revol'][(data_train['Revol']>=1)&(data_train['Revol']<100)],bins=10,ax=ax2)
sns.distplot(data_train['Revol'][(data_train['Revol']>=100)&(data_train['Revol']<10000)],bins=10,ax=ax3)
sns.distplot(data_train['Revol'][(data_train['Revol']>=10000)&(data_train['Revol']<51000)],bins=10,ax=ax4)
ax1.set_title('0==1].shape[0]))
print('大于等于1的数量为:{0}'.format(data_train.loc[data_train['Revol']>=1].shape[0]))
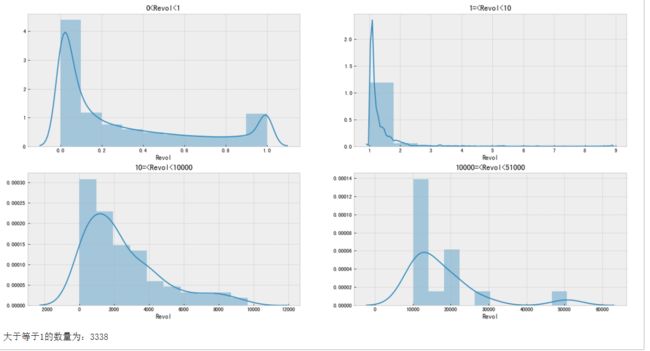
- Revol小于1的分布中,大部分数据都处于(0,0.1)区间,而随着Revol特征值变大,数量递减;
- 在Revol大于1的数值分布中,都明显的呈现了递减趋势,主要集中在100以内的范围内;
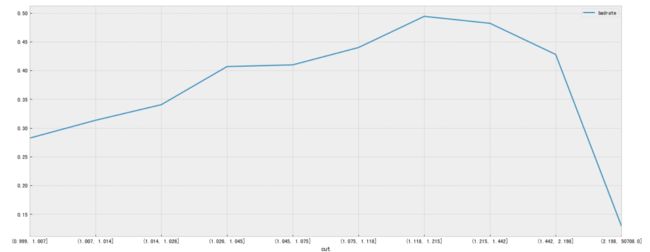
将1~50000等频分箱,计算相应的badrate进行观察
#qcut等频分箱
data2 = data_train[(data_train['Revol']>1)&(data_train['Revol']<51000)]
data2['Revol_100'] = pd.qcut(data2['Revol'],10)
badrate ={}
revol_100_list = list(set(data2['Revol_100']))
for x in revol_100_list:
a = data2[data2['Revol_100'] == x]
bad = a['Label'][a['Label']==1].count()
good = a['Label'][a['Label']==0].count()
badrate[x]=bad/(good+bad)
f = zip(badrate.keys(),badrate.values())
badrate = pd.DataFrame(f)
badrate.columns = ['cut','badrate']
badrate = badrate.sort_values('cut')
print(badrate)
badrate.plot('cut','badrate')
cut badrate
7 (0.999, 1.007] 0.282282
3 (1.007, 1.014] 0.313253
6 (1.014, 1.026] 0.340361
5 (1.026, 1.045] 0.406627
0 (1.045, 1.075] 0.409639
1 (1.075, 1.118] 0.439759
4 (1.118, 1.215] 0.493976
2 (1.215, 1.442] 0.481928
8 (1.442, 2.198] 0.427711
9 (2.198, 50708.0] 0.129518
data_train['Revol'].loc[data_train['Revol']>=2].count()
371
从业务角度出发,随着信用卡贷款比例增高,客户风险越高,badrate就会越大。Revol大于1,客户就已经处于“透支”状态,但是"透支"比例总是有上限的。当Revol大于2时,badrate显著下降至12.95%,接近总体badrate的6.68%,那么可以将Revol大于2的371个客户的Revol值看作属于0~1之间。
特征 DebtRatio
该特征情况经过探索,情况和Revol类似:也是疑似存在比率分母缺失。那么用相似的方法处理。
print(data_train['DebtRatio'][data_train['DebtRatio']>1].count())
print(data_train['DebtRatio'].max())
print(data_train['DebtRatio'].min())
35122
329664.0
0.0
data3['D_100'] = pd.qcut(data3['DebtRatio'],10)
badrate ={}
D100_list = list(set(data3['D_100']))
for x in D100_list:
a = data3[data3['D_100'] == x]
bad = a['Label'][a['Label']==1].count()
good = a['Label'][a['Label']==0].count()
badrate[x]=bad/(good+bad)
f = zip(badrate.keys(),badrate.values())
badrate = pd.DataFrame(f)
badrate.columns = ['cut','badrate']
badrate = badrate.sort_values('cut')
print(badrate)
badrate.plot('cut','badrate',figsize=(20,8))
data_train['DebtRatio'].loc[data_train['DebtRatio']>=2].count()
31200

经过比对,当DebtRatio>2时,badrate就下降至与总体一致,故后面将DebtRatio>2与DebtRatio<1分成一箱。
缺失值探索
特征 NumDependents
NumDependents中缺失值占比
print(data_train[data_train['NumDependents'].isnull()].shape[0])
print(round(data_train[data_train['NumDependents'].isnull()].shape[0]/data_train.shape[0],4))
3911
0.0261
计算缺失值和未缺失值的badrate
d_Null = data_train.loc[data_train['NumDependents'].isnull()]
d_notNull = data_train.loc[data_train['NumDependents'].notnull()]
print('缺失值为{0}%'.format(round(d_Null[d_Null['Label']==1].shape[0]*100/d_Null.shape[0],2)))
print('未缺失值为{0}%'.format(round(d_notNull[d_notNull['Label']==1].shape[0]*100/d_notNull.shape[0],2)))
缺失值为4.55%
未缺失值为6.74%
说明badrate在NumDependents的缺失值下并没有区别,不能将缺失值看作一种特殊的状态对待,那么可以填充缺失值
print(data_train.loc[data_train['MonthlyIncome'].isnull()].shape[0])
print(data_train.loc[(data_train['NumDependents'].isnull())&(data_train['MonthlyIncome'].isnull())].shape[0])
29708
3911
从上面得知MonthlyIncome为空的客户,NumDependents也为空。
下面观察MonthlyIncome为空时,NumDependents不为空的情况。并期望用相似的情况解决NumDependents的空值
D_Null = data_train.loc[(data_train['MonthlyIncome'].isnull())&(data_train['NumDependents'].notnull()),'NumDependents']
D_Null.value_counts().plot(kind='bar', figsize=(10,5))

该情况下,数据绝大部分集中于0处,这也和NumDependents总体分布相似,那么填充为0值。
data_train['NumDependents'] = data_train['NumDependents'].fillna(0)
特征 MonthlyIncome
缺失情况
print(data_train[data_train['MonthlyIncome'].isnull()].shape[0])
print(round(data_train[data_train['MonthlyIncome'].isnull()].shape[0]/data_train.shape[0],4))
29708
0.1981
缺失比例接近20%,考虑使用随机森林算法填充:
data_train.drop(['Unnamed: 0'],axis=1)
from sklearn.ensemble import RandomForestRegressor
process_miss = data_train.iloc[:,[5,0,1,2,3,4,6,7,8,9]]
known = process_miss[process_miss.MonthlyIncome.notnull()].values
unknown = process_miss[process_miss.MonthlyIncome.isnull()].values
x = known[:,1:]
y = known[:,0]
rf = RandomForestRegressor(random_state=0,n_estimators=100,max_depth=3,max_features=3,n_jobs=-1)
rf.fit(x,y)
pre = rf.predict(unknown[:,1:]).round(0)
data_train.loc[data_train['MonthlyIncome'].isnull(),'MonthlyIncome'] = pre
特征 Num30-59、 60-89 、90 late
f,[ax,ax1,ax2]=plt.subplots(1,3,figsize=(20,5))
ax.boxplot(x=data_train['Num30-59late'])
ax1.boxplot(x=data_train['Num60-89late'])
ax2.boxplot(x=data_train['Num90late'])
ax.set_xlabel('Num30-59late')
ax1.set_xlabel('Num60-89late')
ax2.set_xlabel('Num90late')
plt.show()

for i in ['Num30-59late','Num60-89late','Num90late']:
print(data_train[i][data_train[i]>20].count())
269
269
269
从图中看出,三个特征均有大于20的异常值。一般来说逾期不会存在这么多次数,并且异常个数很少,可以考虑删去。
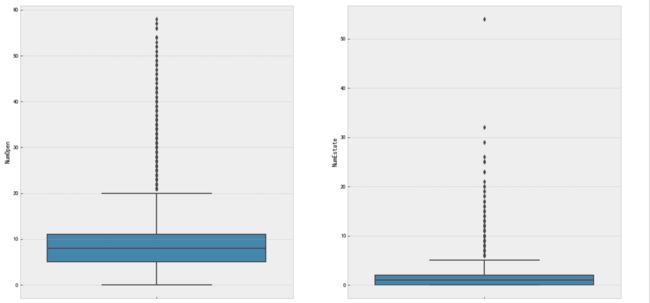
特征 NumOpen和NumEstate
分布和上个特征类似,都是存在少量上界异常值:大于50和大于30
f,[ax1,ax2]=plt.subplots(1,2,figsize=(20,10))
sns.boxplot(y='NumOpen',data=data_train,ax = ax1)
sns.boxplot(y='NumEstate',data=data_train,ax =ax2)
建模部分
导入库及数据
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("bmh")
plt.rc('font', family='SimHei', size=13)
%matplotlib inline
import math
import os
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_predict
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.preprocessing import StandardScaler
# 导入数据
data_train = pd.read_csv('cs-training.csv')
data_test = pd.read_csv('cs-test.csv')
columns = ({'SeriousDlqin2yrs':'Label',
'RevolvingUtilizationOfUnsecuredLines':'Revol',
'NumberOfOpenCreditLinesAndLoans':'NumOpen',
'NumberOfTimes90DaysLate':'Num90late',
'NumberRealEstateLoansOrLines':'NumEstate',
'NumberOfTime60-89DaysPastDueNotWorse':'Num60-89late',
'NumberOfDependents':'NumDependents',
'NumberOfTime30-59DaysPastDueNotWorse':'Num30-59late'}
)
data_train.rename(columns=columns,inplace = True)
data_test.rename(columns=columns,inplace = True)
处理测试集异常值
data_train = data_train[data_train['age']!=0]
data_train = data_train[data_train['Num30-59late']<20]
data_train = data_train[data_train['Num60-89late']<20]
data_train = data_train[data_train['Num90late']<20]
data_train= data_train[data_train['NumOpen']<50]
data_train= data_train[data_train['NumEstate']<30]
data_train = data_train.drop(['Unnamed: 0'],axis=1)
data_test = data_test.drop(['Unnamed: 0'],axis=1)
补全测试集和验证集缺失值
#随机森林补全income
def missfill(df):
process_miss = df.iloc[:,[5,1,2,3,4,6,7,8,9]]
known = process_miss[process_miss.MonthlyIncome.notnull()].as_matrix()
unknown = process_miss[process_miss.MonthlyIncome.isnull()].as_matrix()
X = known[:,1:]
y = known[:,0]
rfr = RandomForestRegressor(random_state=0,n_estimators=100,max_depth=3,n_jobs=-1,max_features = 3)
rfr.fit(X,y)
pre= rfr.predict( unknown[:,1:]).round(0)
return pre
# 预处理
def processing(data):
data["NumDependents"] = np.abs(data["NumDependents"])
data["NumDependents"] = data["NumDependents"].fillna(0)
data["NumDependents"] = data["NumDependents"].astype('int64')
data.loc[(data['NumDependents']>=7), 'NumDependents'] = 7
pre = missfill(data)
data.loc[data['MonthlyIncome'].isnull(),'MonthlyIncome'] = pre
#构造新的特征
data["Defaulted"] = data["Num90late"] + data["Num60-89late"] + data["Num30-59late"]
data["Loans"] = data["NumOpen"] + data["NumEstate"]
data["DebtPay"] =np.absolute( data["DebtRatio"] * data["MonthlyIncome"])
data["DebtPay"] = data["DebtPay"].astype('int64')
data["age"] = data["age"].astype('int64')
data["MonthlyIncome"] = data["MonthlyIncome"].astype('int64')
data["age_map"] = data["age"]
data["WithDependents"] = data["NumDependents"]
return data
def hand_bin(data):
# 手动分箱
# Revol特征分箱
data.loc[(data['Revol']>=0)&(data['Revol']<1), 'Revol'] = 0
data.loc[(data['Revol']>1)&(data['Revol']<=30), 'Revol'] = 1
data.loc[(data['Revol']>30), 'Revol'] = 0
# DebtRatio特征分箱
data.loc[(data['DebtRatio']>=0)&(data['DebtRatio']<1), 'DebtRatio'] = 0
data.loc[(data['DebtRatio']>=1)&(data['DebtRatio']<2), 'DebtRatio'] = 1
data.loc[(data['DebtRatio']>=2), 'DebtRatio'] = 0
# Num30-59late, Num60-89late, Num90late,NumOpen
data.loc[(data['Num30-59late']>=8), 'Num30-59late'] = 8
data.loc[(data['Num60-89late']>=7), 'Num60-89late'] = 7
data.loc[(data['Num90late']>=10), 'Num90late'] = 10
data.loc[(data['NumEstate']>=8), 'NumEstate'] = 8
# 衍生变量分箱
data.loc[(data["Defaulted"] >= 1), "Defaulted"] = 1
data.loc[(data["Loans"] <= 5), "Loans"] = 0
data.loc[(data["Loans"] > 5), "Loans"] = 1
data.loc[(data["WithDependents"] >= 1), "WithDependents"] = 1
data.loc[(data["age"] >= 18) & (data["age"] < 60), "age_map"] = 1
data.loc[(data["age"] >= 60), "age_map"] = 0
data["age_map"] = data["age_map"].replace(0, "older")
data["age_map"] = data["age_map"].replace(1, "senior")
data = pd.concat([data, pd.get_dummies(data.age_map,prefix='is')], axis=1)
return data
Ytest = data_test['Label']
Xtest = data_test.drop(['Label'], axis=1)
Ytrain = data_train['Label']
Xtrain = data_train.drop(['Label'], axis=1)
data_train = processing(data_train)
data_test = processing(data_test)
data_train = hand_bin(data_train)
data_test = hand_bin(data_test)
data_train.drop('age_map',axis=1,inplace=True)
data_test.drop('age_map',axis=1,inplace=True)
特征相关性热力图
corr = data_train.corr()
plt.figure(figsize=(14,12))
sns.heatmap(corr, annot=True)

将变量分成离散变量和连续变量分别进行进行woe,iv值计算:
dvar = ['Revol','DebtRatio','Num30-59late', 'Num60-89late','Num90late','Defaulted','WithDependents',
'NumEstate','NumDependents','Loans','is_senior','is_older']
svar = ['MonthlyIncome','age','NumOpen','DebtPay']
def bin_woe(tar, var, n=None, cat=None):
total_bad = tar.sum()
total_good =tar.count()-total_bad
totalRate = total_good/total_bad
if cat == 's':
msheet = pd.DataFrame({tar.name:tar,var.name:var,'bins':pd.qcut(var, n, duplicates='drop')})
grouped = msheet.groupby(['bins'])
elif (cat == 'd') and (n is None):
msheet = pd.DataFrame({tar.name:tar,var.name:var})
grouped = msheet.groupby([var.name])
groupBad = grouped.sum()[tar.name]
groupTotal = grouped.count()[tar.name]
groupGood = groupTotal - groupBad
groupRate = groupGood/groupBad
groupBadRate = groupBad/groupTotal
groupGoodRate = groupGood/groupTotal
woe = np.log(groupRate/totalRate)
iv = np.sum((groupGood/total_good-groupBad/total_bad)*woe)
if cat == 's':
new_var, cut = pd.qcut(var, n, duplicates='drop',retbins=True, labels=woe.tolist())
elif cat == 'd':
dictmap = {}
for x in woe.index:
dictmap[x] = woe[x]
new_var, cut = var.map(dictmap), woe.index
return woe.tolist(), iv, cut, new_var
def woe_vs(data):
cutdict = {}
ivdict = {}
woe_dict = {}
woe_var = pd.DataFrame()
for var in data.columns:
if var in dvar:
woe, iv, cut, new = bin_woe(data['Label'], data[var], cat='d')
woe_dict[var] = woe
woe_var[var] = new
ivdict[var] = iv
cutdict[var] = cut
elif var in svar:
woe, iv, cut, new = bin_woe(data['Label'], data[var], n=5, cat='s')
woe_dict[var] = woe
woe_var[var] = new
ivdict[var] = iv
cutdict[var] = cut
ivdict = sorted(ivdict.items(), key=lambda x:x[1], reverse=False)
iv_vs = pd.DataFrame([x[1] for x in ivdict],index=[x[0] for x in ivdict],columns=['IV'])
ax = iv_vs.plot(kind='bar',
figsize=(12,12),
title='Feature Importance',
fontsize=10,
width=0.8)
ax.set_ylabel('Features')
ax.set_xlabel('IV of Features')
return ivdict, woe_var, woe_dict, cutdict
iv_info, woe_data, woe_dict, cut_dict = woe_vs(data_train)
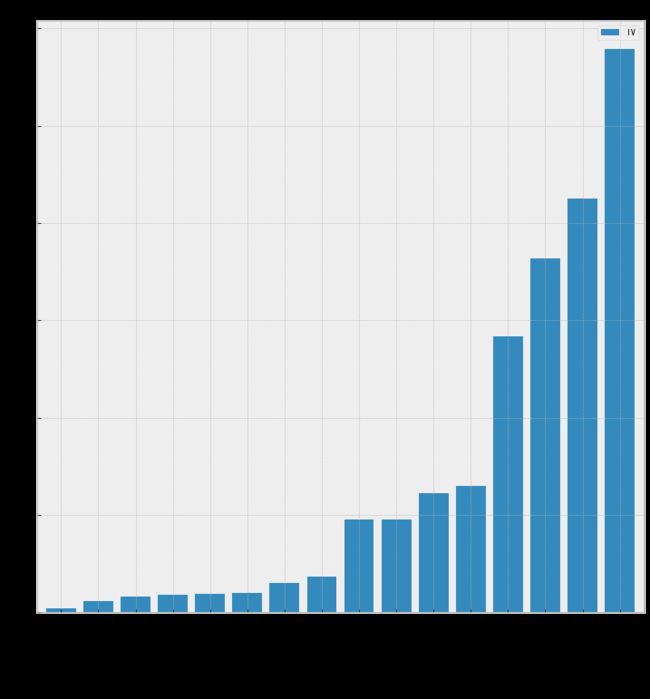
由此可以开始选择选择变量
选择变量
选择变量的基本规则是根据热力图和上面的IV图和在特征相关性高的变量中,选择IV值高的规则,可以选择如下变量:
is_senior | is_older | age:选age
WithDependents | NumDependents:选NumDependents
Defaulted | Num30-59late:选Defaulted
NumOpen |Loans:选NumOpen
最后保留的变量
ivinfo_keep = ['Revol', 'age', 'DebtRatio', 'MonthlyIncome',
'NumOpen', 'Num90late', 'NumEstate', 'Num60-89late',
'NumDependents','Defaulted','DebtPay']
再次计算相关系数:
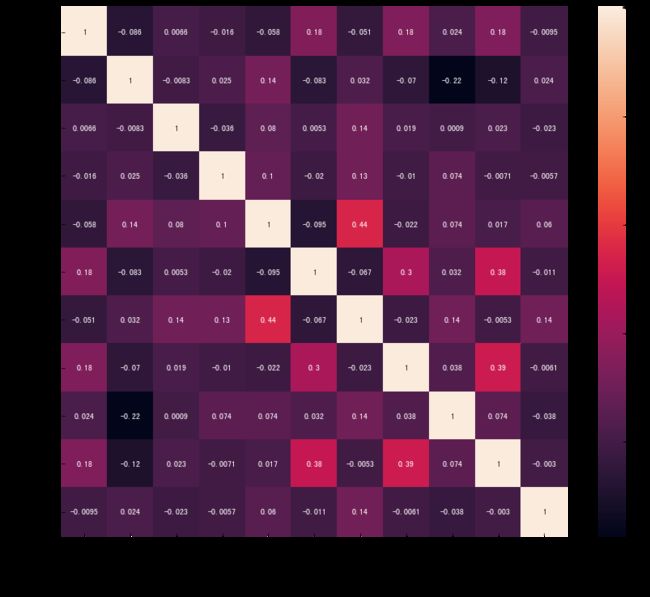
可以判断各变量之间不存在明显的相关性
逻辑回归建模
X = woe_data[ivinfo_keep]
y = Ytrain
X_train, X_val, y_train, y_val = train_test_split(X,y,random_state=42)
logit = LogisticRegression(random_state=0,
solver="sag",
penalty="l2",
class_weight="balanced",
C=1.0,
max_iter=500)
logit.fit(X_train, y_train)
logit_scores_proba = logit.predict_proba(X_train)
logit_scores = logit_scores_proba[:,1]
利用ROC曲线判断效果:
def plot_roc_curve(fpr, tpr, auc_score, label=None):
plt.figure(figsize=(10,8))
plt.plot(fpr, tpr, linewidth=2, label='AUC = %0.2f'%auc_score)
plt.plot([0,1],[0,1], "k--")
plt.axis([0,1,0,1])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive rate")
plt.legend()
fpr_logit, tpr_logit, thresh_logit = roc_curve(y_train, logit_scores)
auc_score = roc_auc_score(y_train, logit_scores)
print("AUC: {}".format(auc_score))
plot_roc_curve(fpr_logit,tpr_logit, auc_score)

AUC: 0.8290290455012129
从上面图形和auc值可以看出拟合效果较好,接下来开始计算评分卡:
coe = logit.coef_
intercept = logit.intercept_
B = 20 / math.log(2)
A = 600 + B / math.log(20)
# 基础分
base = round(A-B * intercept[0], 0)
featurelist = []
woelist = []
coelist = []
cutlist = []
for k,v in woe_dict.items():
if k in ivinfo_keep:
for n in range(0,len(v)):
featurelist.append(k)
woelist.append(v[n])
coelist.append(coe[0][n])
cutlist.append(cut_dict[k][n])
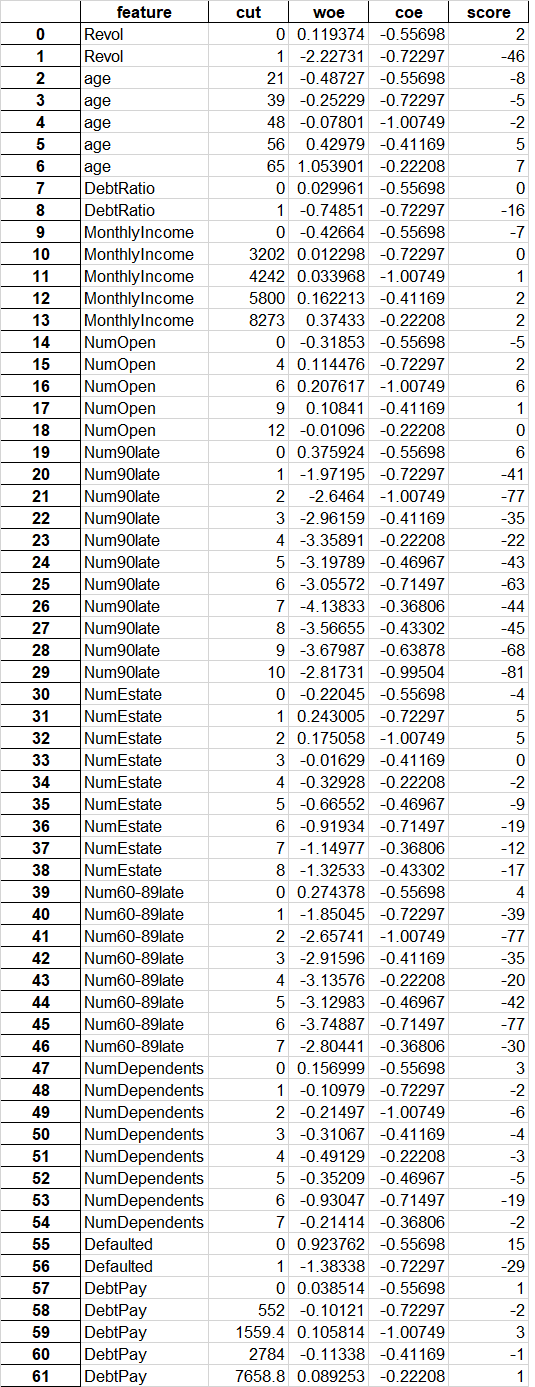
scoreboard = pd.DataFrame({'feature':featurelist, 'woe':woelist, 'coe':coelist, 'cut':cutlist},
columns=['feature','cut','woe','coe'])
scoreboard['score'] = round(-scoreboard['woe']*scoreboard['coe']*B,0).astype('int64')
scoreboard
结果如下:
总结:
1.用户的属性有千千万万个维度,而评分卡模型所选用的特征很有限,这时候就需要一定的原则对变量筛选:预测能力、变量相关性等。
- 评分卡模型采用的是对每个字段的分段进行评分,对于特征的分段处理就是采用变量分箱。
- 对字段的每个分段进行评分的方式是采用WOE-IV编码,将预测概率值转化为评分,利用变量相关性分析确保其合理性。
4.本质上是采用逻辑回归进行二分类,但重点在于特征筛选和处理方面。