Xutils3.0技术分享
1.这个技术分享的目的
1.首先要让大家了解Xutil3.0是什么
Xtuils3.0的前身是Xutils,是两年前就很火的一个开源框架,包含了很多实用的Android开发工具,支持大文件的上传以及下载,更加全面的Http请求协议支持(Get,Post,Delete等等),并且拥有更加灵活的ORM框架,更多的事件注解能够让你的代码更加简洁高效,目前之前的Xutils已经停止维护 所有的维护工作已经在Xutils3.0中继续 值得注意的是 Xutils3.0最低兼容android4.0
2.Xutils3.0的基本使用方式
在这边技术文档里面 会介绍Xtuils3.0几大模块的基本使用方式:
1.如何发起一个Http请求
2.如何使用DB模块实现数据库的增删改查
3.如何使用BitMapUtils实现网路图片以及本地控件的绑定以及显示
4.如何给控件设置各种事件(这里主要是通过注解的方式)
3.Xutils3.0的几大模块的介绍以及实现原理
大家通过这篇文章会对Xtuils3.0的四大模块有一定的了解 并且会大致了解每个模块的底层实现,这样大家在使用的过程中基本上能够做到心中有数
4.如何在项目中使用Xtuils3.0
当然我们学习框架的主要原因就是要在项目中去使用,通过这篇文档大家就能够了解Xtuils3.0的基本使用规则了,然后就大胆放心的去项目中实践吧,因为理论结合实践才能真正理解这个框架的设计原理以及精髓之处。
2.Xutils3.0的背景介绍
Xtutils的作者是 wyouflf 一个很牛的android开源工作者 ,目前Xutils的六个500人QQ群已经全部爆满 可见这个框架的火热程度以及大家对这个框架的关注 我们感谢作者让我们有了避免重复造轮子的前提 对于进度要求很紧的团队 真的可以直接拿来用 并且该框架的维护还是很及时的。目前由于Android系统的不断更新 Xtuils框架也更新到了3.0版本 之前的版本已经不再维护 所以建议大家使用过的时候尽量使用最新的版本。
该开源框架的下载地址:https://github.com/wyouflf/xUtils3
3.我们选择Xutils3.0的原因
我们为什么选择Xtuis3.0呢?因为它里面包含的四大模块基本上能够解决我们开发中所遇到的问题了,比如我们Android开发中经常涉及到的就是请求网络数据 加载网络图片 缓存本地数据库 以及响应用户事件等等 所有的框架设计的初衷基本上都是一致的 那就是封装一些常见的操作 避免代码的冗余以及程序结构的臃肿。当然也有很多一些其他的框架,比如Afinal ,AndroidOne等 也都很优秀我们选择Xtuils的原因主要是因为下面几个方面:
1.我们之前的程序中使用的是Xtuils1.0版本 通过实践证明这个框架稳定性方面得到了我们的认可
2.Xtuils的入门成本比较低 主要是在于作者封装的比较好,比如我们要请求一条网络数据,一行代码就可以了 这就省去了我们平时写代码的很多事情了,比如我们要设置请求头
、设置请求参数以及请求方式 但是通过该框架我们只需要一句代码 将必要的参数穿进去就OK了
3.Xtuils的更新速度快 基本上问题被抛出来后 作者以及团队成员就会很快跟近并且更新版本。
基于以上几点 我们选择使用Xtuils框架 当然目前我们打算替换为最新的3.0版本
4.Xutils3.0的技术细节分解
4.1 Xutils3.0较之前的版本有了哪些改进
4.1.1 HTTP实现替换HttpClient为UrlConnection, 自动解析回调泛型, 更安全的断点续传策略.
4.1.2 支持标准的Cookie策略, 区分domain, path...
4.1.3 事件注解去除不常用的功能, 提高性能.
4.1.4 数据库api简化提高性能, 达到和greenDao一致的性能.
4.1.5 图片绑定支持gif, webp; 支持圆角, 圆形, 方形等裁剪, 支持自动旋转等等
4.2 Xutils3.0为什么最低兼容4.0
我们通过最新的2016年的Android版本分布状况来看一下:
如果这个数据不够直接的话 我们来看一下Umeng统计关于版本分布的情况吧
通过这两组数据 大家觉得我们还有必要去维护4.0以下的版本吗
这么低的活跃度甚至最新的Umeng统计已经没有4.0一下的统计了, 那些2.X的版本要么是应用后台自启动, 要么都是各个软件公司的测试机.
现在2.3的测试机都买不到了, 没法保证上线的稳定性.
为兼容2.3话费巨大的人力和资源, 几乎没有回报, 不值得.
4.3 Xutils3.0能够提供什么功能
这个其实之前我们已经提前介绍了,其实Xtuils3.0能提供的主要功能就是四大模块对开发的支持 比如对HTTP请求 、图片的处理、数据库的简化、事件处理的注解机制 等四大功能模块
4.4 Xutils3.0几大模块介绍
4.4.1 DbUtils模块
由于个人时间问题,这一模块我就暂时不分析了 有兴趣的同学可以根据其他模块的逻辑进行自行分析 如果我有时间 会将这一块补上去的。其实这一块的大致逻辑 跟之前的Xutils我个人认为也不会改变太大 所以大家可以作为对Xutils3.0的深入认识的一次锻炼 自己分析一下
4.4.2 ViewUtils模块
其实这个模块是基于注解实现的 我们首先来看下这个模块能给我们带来什么好处而吸引这么多人去使用它呢?
我们来做一个对比:
首先是我们传统的写法:
public void initView() {
2.mPager = (CustomViewPager) findViewById(R.id.home_viewPager);
3.paid_tab_ll = (LinearLayout) findViewById(R.id.paid_tab_ll);
4.good_tab_ll = (LinearLayout) findViewById(R.id.good_tab_ll);
5.user_tab_ll = (LinearLayout) findViewById(R.id.user_tab_ll);
6.user_tab_img = (ImageButton) findViewById(R.id.user_tab_img);
7.good_tab_img = (ImageButton) findViewById(R.id.good_tab_img);
8.paid_tab_img = (ImageButton) findViewById(R.id.paid_tab_img);
9.paid_tab_tv = (TextView) findViewById(R.id.paid_tab_tv);
10.good_tab_tv = (TextView) findViewById(R.id.good_tab_tv);
11.user_tab_tv = (TextView) findViewById(R.id.user_tab_tv);
13.}
这段代码相信Android的小伙伴不会陌生其实就是针对我们在布局文件中书写的控件的一些初始化操作来找到对应的组件
接下来我们来看下使用Xutils3.0之后我们的代码的写法:
@ViewInject(R.id.viewPager)
2.private CustomViewPager mPager 这里我们只写一个就OK了 其他的类似
发现没有我们不用再去重复的编写findViewById了这一大长串的功能了 有对比才有有差距 如果让你去选择 ,你肯定也会倾向于使用第二种方式了 是吧 相信大家也猜到了 肯定是这个ViewInject注解里面做了些什么事情 而省去了我们重复编写findviewById方法的麻烦 了解注解的人应该已经有所领悟了
那我们就来揭开这个神秘的面纱吧
1.private static void injectObject(Object handler, Class handlerType, ViewFinder finder) {
if (handlerType == null || IGNORED.contains(handlerType)) {return;}// 从父类到子类递归injectObject(handler, handlerType.getSuperclass(), finder);// inject viewField[] fields = handlerType.getDeclaredFields();if (fields != null && fields.length > 0) {for (Field field : fields) {Class fieldType = field.getType();if (/* 不注入静态字段 */ Modifier.isStatic(field.getModifiers()) ||/* 不注入final字段 */ Modifier.isFinal(field.getModifiers()) ||/* 不注入基本类型字段 */ fieldType.isPrimitive() ||/* 不注入数组类型字段 */ fieldType.isArray()) {continue;}ViewInject viewInject = field.getAnnotation(ViewInject.class);if (viewInject != null) {try {View view = finder.findViewById(viewInject.value(), viewInject.parentId());if (view != null) {field.setAccessible(true);field.set(handler, view);} else {throw new RuntimeException("Invalid @ViewInject for "+ handlerType.getSimpleName() + "." + field.getName());}} catch (Throwable ex) {LogUtil.e(ex.getMessage(), ex);}}}} // end inject view
怎么样是不是看到了上面红色标记的一行27行很熟悉啊 原来前端的简洁 是因为后端已经帮我们处理了麻烦的查找逻辑了
但是我们要想使他生效 的话 必须要执行这一行代码的
x.view().inject(holder, view);
这样系统加载你这个类的时候才会去初始化你所设置的注解的值以及初始化工作
其实这个模块就是要求你对反射以及注解有一个基本的认识和理解并且能够在代码中去使用他们 其实现在很多框架都是基于反射结合注解实现的
4.4.3 HTTP 模块
首先我们来说一下Xutils3.0中关于Http模块优秀于其他框架的原因
1.Xutils3.0支持大文件的上传和下载 当然肯定是支持断点续传以及断点下载的 这是现在上传下载的必备功能了
2.Xutils3.0支持Http缓存和Cookie缓存 我们来看一下源码中的表现吧

从这里看出我们的HttpCache以及Cookie都是通过数据库 来进行缓存的 一般我们使用最多大概就是HttpCache了 这是在DBConfig这个类里面的 并且在构造LRUDiskCache的时候初始化的。
1.首先我们我们知道HTTP支持多种谓词比如GET POST等等,Xutils支持11种谓词 我们从其源码中就可以看出 我们此处来看一下源码中如何表示的:
public enum HttpMethod {
2.GET("GET"),
3.POST("POST"),
4.PUT("PUT"),
5.PATCH("PATCH"),
6.HEAD("HEAD"),
7.MOVE("MOVE"),
8.COPY("COPY"),
9.DELETE("DELETE"),
10.OPTIONS("OPTIONS"),
11.TRACE("TRACE"),
12.CONNECT("CONNECT");
}
我们可以看到 这11种谓词是通过一个枚举变量HttpMethod来进行表示的 说明Xutils支持这么多的请求方式。这里面我们就不一一介绍了,需要了解的朋友自行百度一下。
2.接下来我们就通过一个简单的GET请求来看看通过Xtuils我们如何发送一个请求来请求服务器的某种资源
- Callback.Cancelable cancelable
= x.http().get(params,new Callback.CommonCallback
4.@Override
5.public void onSuccess(List
6.Toast.makeText(x.app(), result.get(0).toString(), Toast.LENGTH_LONG).show();
7.}
9.@Override
10.public void onError(Throwable ex, boolean isOnCallback) {
11.Toast.makeText(x.app(), ex.getMessage(), Toast.LENGTH_LONG).show();
12.if (ex instanceof HttpException) { // 网络错误
13.HttpException httpEx = (HttpException) ex;
14.int responseCode = httpEx.getCode();
15.String responseMsg = httpEx.getMessage();
16.String errorResult = httpEx.getResult();
17.// ...
18.} else { // 其他错误
19.// ...
20.}
21.}
23.@Override
24.public void onCancelled(CancelledException cex) {
25.Toast.makeText(x.app(), "cancelled", Toast.LENGTH_LONG).show();
26.}
28.@Override
29.public void onFinished() {
31.}
32.});
看上面的代码 这就是一个发起一个GET请求所需要的代码 是不是一句话就解决了 而且还带有请求成功或者失败的回调 是不是很强大呢 ,其实我们在代码中当发起一个GET请求的时候 我们只需要这么做:
1.封装一个请求参数Params
2.自定义回调函数的处理就OK了。
使用起来就是这么简单 ,但是它底层的实现还是很复杂的 接下来我们就从源码角度去分析作者的设计思路。 其实这里教大家一个分析源码的方法 ,其实我们就将源码导进AndroidStdio中 然后我们请求的入口开始 一步一步的去跟并且做下标记,这样不至于层次太深之后头脑混乱。
接下来我就带大家去从x.http.get()这个入口函数中开始整个请求过程的分析:
首先:我们得知道get()方法是在哪个类里面定义的 通过源码我们看到 x.http()返回的是一个HttpManagerImpl类实现的 是通过单例实现的,这个单例设计模式在Android源码中也有用到过 这里就不对其做详细解释了 其实单例的写法很多 目前我们经常见到的并且使用频率很高的是静态内部类写法和双重检查加锁机制来实现的加上关键字voliate修饰单例变量 由于JDK的不断升级 目前这两种写法都算是比较安全并且稳定的写法了。这里只贴下源码即可:
- public static void registerInstance() {
if (instance == null) {synchronized (lock) {if (instance == null) {instance = new HttpManagerImpl();}}}x.Ext.setHttpManager(instance);- }
作者就是通过双重检查加锁来实现单例的 ,我们来看下标准的双重加锁实现单例的标准写法
双重检查锁定看起来似乎很完美,但这是一个错误的优化!在线程执行到第4行代码读取到instance不为null时,instance引用的对象有可能还没有完成初始化。
问题的根源
前面的双重检查锁定示例代码的第7行(instance = new Singleton();)创建一个对象。这一行代码可以分解为如下的三行伪代码:
memory = allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance = memory; //3:设置instance指向刚分配的内存地址
上面三行伪代码中的2和3之间,可能会被重排序(在一些JIT编译器上,这种重排序是真实发生的,详情见参考文献1的“Out-of-order writes”部分)。2和3之间重排序之后的执行时序如下:
memory = allocate(); //1:分配对象的内存空间
instance = memory; //3:设置instance指向刚分配的内存地址
//注意,此时对象还没有被初始化!
ctorInstance(memory); //2:初始化对象
如果发生这种情况的话 ,那么就会出现一个线程引用了还没有初始化的instance 这就是双重加锁问题的根源
那么其实上面的问题也很好解决 :我们只需要将instance声明为voliate类型的就能避免重排序造成的隐患
这里我推荐一种更加优秀的解决方法
基于类初始化的解决方案
JVM在类的初始化阶段(即在Class被加载后,且被线程使用之前),会执行类的初始化。在执行类的初始化期间,JVM会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化。
基于这个特性,可以实现另一种线程安全的延迟初始化方案(这个方案被称之为Initialization On Demand Holder idiom):
public class InstanceFactory {
private static class InstanceHolder {
public static Instance instance = new Instance();
}
public static Instance getInstance() {
return InstanceHolder.instance ; //这里将导致InstanceHolder类被初始化
}
}
假设两个线程并发执行getInstance(),下面是执行的示意图:
好了 这里只是作为一个小插曲 给大家卖弄一下最简单的设计模式 这并不是我们这次分享的主要目的 我们接下来继续往下分析:
这里我们知道了x.http()返回的对象是HttpManagerImpl 那么我就去看看get方法的实现
@Override
public
//设置请求方法为GET
entity.setMethod(method);
Callback.Cancelable cancelable = null;
if (callback instanceof Callback.Cancelable) {
cancelable = (Callback.Cancelable) callback;
}
// 构建一个HttpTask对象 然后后调用x.task().start()方法开启请求
HttpTask
return x.task().start(task);
}
1.其实HttpTask的构造函数里面只是初始化了请求参数以及回调函数的设置 并且对线程池执行器进行初始化。我们看到 对于我们上面的请求 此时我们的执行器是// init executor
2.if (params.getExecutor() != null) {
3.this.executor = params.getExecutor();
4.} else {
5.if (cacheCallback != null) {
6.this.executor = CACHE_EXECUTOR;
7.} else {
8.this.executor = HTTP_EXECUTOR;
9.}
10.}
这个HTTP_EXECUTOR是个什么玩意呢 这里告诉大家 他的类型是PriorityExecutor
是一个支持优先级的一个线程执行器。
这样将这个任务扔进TaskControllerImpl中进行执行。
我们将整个的请求框架流程图画一下:
这个只是整个主要的流程 当然内部还有很多的细节 ,这个我们就通过阅读源码去了解就可以了。
接下来我们通过大致的时序图来带领大家去熟悉一下整个的请求过程:

主要步骤分为5步:
1.调用x.http().get()发起请求 然后会得到HttpManagerImpl的一个实例 然后调用该类的request方法
2.在request方法中创建一个HttpTask对象并且内部确定了HttpTask的内部线程执行器默认是PriorityExecutor
3.调用TaskController的实现类的start将我们刚才创建的HttpTask传递过去 然后构建一个TaskProxy对象
4.调用TaskProxy对象的doBackGround方法
5.然后该方法内部调用HttpTask的doBackGround方法
6 最后将得到的结果更新到UI线程
其实这里面主要的逻辑就在第5步 我们如何调用HTTPTask对象的doBackground方法得到请求的结果 接下来我们就详细分析每一步:

这里面从发起请求到请求返回结果 一共经历了10步操作
接下来我们一步步来进行讲解:
1.这个方法实现如下
// 解析loadType
private void resolveLoadType() {
Class callBackType = callback.getClass();
if (callback instanceof Callback.TypedCallback) {
loadType = ((Callback.TypedCallback) callback).getLoadType();
} else if (callback instanceof Callback.PrepareCallback) {
loadType = ParameterizedTypeUtil.getParameterizedType(callBackType, Callback.PrepareCallback.class, 0);
} else {
loadType = ParameterizedTypeUtil.getParameterizedType(callBackType, Callback.CommonCallback.class, 0);
}
}
其实这个方法的作用就是得到我们之前传进来的CommonCallBack泛型中填写的参数 其实就BaiduResponse 这样当从服务器得到返回结果之后 我们就知道要将结果解析成什么类型的对象了
2.这一步主要是创建一个HttpRequest请求
1.private UriRequest createNewRequest() throws Throwable {
2.// init request
3.params.init();
4.UriRequest result = UriRequestFactory.getUriRequest(params, loadType);
5.result.setCallingClassLoader(callback.getClass().getClassLoader());
6.result.setProgressHandler(this);
7.this.loadingUpdateMaxTimeSpan = params.getLoadingUpdateMaxTimeSpan();
8.this.update(FLAG_REQUEST_CREATED, result);
9.return result;
10.}
11.这一步其实主要是通过UriRequestFactory.getUriRequest来获得一个UriRequest对象我们来看下这个对象的实际类型是什么?
1.if (scheme.startsWith("http")) {
2.return new HttpRequest(params, loadType);
这就是这个方法内部最后返回给我们的一个HttpRequest对象 然后返回给调用者
3.主要是检查下载文件是否冲突的 这个就请读者们自行阅读源码了 这个不是很重要 除非你要下载一个文件时候需要关注这一块
4.其实就是创建一个重试的对象 然后设置最大的重试次数 这个也不多说
5.这一步主要是检查缓存中是否包含我们这次的请求 如果包含就将缓存结果取出来然后返回给客户端 如果没有 就继续往下走
6.走到这里就会进行while循环 直到重试次数大于最大重试次数 然后循环体内主要是创建了RequestWorker对象 这是一个线程 创建完成之后会调用他的start方法 然后加入到HttpTask的所在线程中 我们只需关注这个线程的run方法中的一句代码
1.try {
2.this.result = request.loadResult();
3.} catch (Throwable ex) {
4.this.ex = ex;
5.}
这个request对象我们已经知道 他的类型是HttpRequest 我们来看下这个类里的实现
1.public Object loadResult() throws Throwable {
2.return this.loader.load(this);
3.}
我们发现其实调用了loader对象的load方法 这个loader又是个什么东西呢?
1.public static Loader getLoader(Type type, RequestParams params) {
2.Loader result = converterHashMap.get(type);
3.if (result == null) {
4.result = new ObjectLoader(type);
5.} else {
6.result = result.newInstance();
7.}
8.result.setParams(params);
9.return result;
10.}
我们发现如果我们没有自定义Loader的话 这里返回给我们的就是ObjectLoader的实体对象
我们来看这个类的load方法
1.@Override
2.public Object load(final UriRequest request) throws Throwable {
3.try {
4.request.sendRequest();
5.} finally {
6.parser.checkResponse(request);
7.}
8.return this.load(request.getInputStream());
9.}
然后此时调用了request的sendRequest其实进去这个方法就知道 这个方法主要的作用就是设置请求参数的 比如添加请求头 设置请求体(如果是Post请求的话) 设置完成之后 我们将isLoading==true 说明已经处于Loading状态了
接下来就会调用第9步 然后利用IOUtils将请求的结果封装成我们想要的类型返回给调用者
最后我们看下返回给调用者之后做了什么?
我们还记得我们之前是怎么一步一步走到现在的吗? 是在调用HttpTask的setResult的方法中开始的 而这个方法的调用是在TaskProxy类的DoBackGroud方法中调用的
然后接下来返回结果之后呢
- TaskProxy.this.setResult(task.getResult());
// 未在doBackground过程中取消成功if (TaskProxy.this.isCancelled()) {throw new Callback.CancelledException("");}// 执行成功TaskProxy.this.onSuccess(task.getResult());
设置结果 并且调用onSucecess方法将结果传给UI线程 我们来看下这个方法
1.@Override
2.protected void onSuccess(ResultType result) {
3.this.setState(State.SUCCESS);
4.sHandler.obtainMessage(MSG_WHAT_ON_SUCCESS, this).sendToTarget();
5.}
我们看到了熟悉的Handler机制 见到这个Handler 我们首先能够想到的就是肯定在Activity类里面有一个HanderMessage方法来处理这个消息
那么我们来验证一下
1.final static class InternalHandler extends Handler {
3.private InternalHandler() {
4.super(Looper.getMainLooper());
5.}
7.@Override
8.@SuppressWarnings("unchecked")
9.public void handleMessage(Message msg) {
10.if (msg.obj == null) {
是吧 我们看到了handleMessage方法
1.switch (msg.what) {
case MSG_WHAT_ON_WAITING: {taskProxy.task.onWaiting();break;}case MSG_WHAT_ON_START: {taskProxy.task.onStarted();break;}case MSG_WHAT_ON_SUCCESS: {taskProxy.task.onSuccess(taskProxy.getResult());break;}case MSG_WHAT_ON_ERROR: {assert args != null;Throwable throwable = (Throwable) args[0];LogUtil.d(throwable.getMessage(), throwable);taskProxy.task.onError(throwable, false);break;}case MSG_WHAT_ON_UPDATE: {taskProxy.task.onUpdate(msg.arg1, args);break;}case MSG_WHAT_ON_CANCEL: {if (taskProxy.callOnCanceled) return;taskProxy.callOnCanceled = true;assert args != null;taskProxy.task.onCancelled((org.xutils.common.Callback.CancelledException) args[0]);break;}case MSG_WHAT_ON_FINISHED: {if (taskProxy.callOnFinished) return;taskProxy.callOnFinished = true;taskProxy.task.onFinished();break;}default: {break;}
然后我们就知道这是如何调用到我们之前第一步x.http().get()里的第二个参数CommonCallBack的一系列方法的 这样 整个请求的过程我们就分析完了 相信大家都有一定的了解了 所以就大胆的尝试去使用Http请求吧
4.4.4 ImageRequest模块
在这里我们不得不提一点 Xutils3.0的作者的代码的精细程度以及对各种场景的准确把握 ,这或许就是为什么Xutils3.0能够在这么多的框架当中得到这么多用户的原因 下面我们就列出几个场景 你在其他框架看不到但是在xutils3.0中却能看到很精妙的解决方案
并且Xutils3.0中对图片的请求下载也是支持断点的 这跟你下载文件是一个逻辑
场景1: 我们打开一个页面 展示很多图片 比如一个LIstview然后呢 我们点击item之后跳到另一个页面之后 也是一个图片的列表 此时呢 第一个页面并没有被销毁 那么imageview所持有的图片也没有被销毁 然后第二个页面加载图片的时候 我们是往同一个MemearyCache中添加缓存的 如果超过我们设定的缓存的大小呢 就会将第一个页面中缓存的页面给清除掉 当我们回到第一个页面中 可能就会因为缓存中已经被清楚 而从磁盘加载图片此时效率可能就会受影响 从而导致图片的闪烁 而这段代码的目的就是 如果我们第一个页面的view所持有的图片资源还没有被销毁 那就直接将它添加到缓存中去 然后接下来我们请求就是从内存缓存中读取而不是磁盘缓存了 这样就能够避免这种场景下导致的加载延迟或者页面闪烁现象了
场景2:
当前屏幕能够显示 3个item 那么就会调用三次bind方法
前三次imageview都为null 然后会进行加载将imageview设置AsyncDrawable
此时进入第四个Item 此时复用第一个item的布局 但是imageview的对象没有变 但是关联的数据已经变了 那么之前进入屏幕外的第一个item的图片的加载过程可能还没完成 也可能已经完成了
假如没有完成 此时呢 这段代码就能起到 去取消那个请求 但是如果此时用户又很快滑动到第一个item此时判断key相同 那么就什么都不做了 因为之前跟imageview关联的Imageloade就会继续之前的操作。
那么作者是如何巧妙的解决上述两种背景引起的BUG呢 其实就是很简单的一段代码以及自定义Drawable就解决了
那我们先睹为快 然后再一步一步带领你去分析实现的原理
// stop the old loader
MemCacheKey key = new MemCacheKey(url, localOptions);
Drawable oldDrawable = view.getDrawable();
if (oldDrawable instanceof AsyncDrawable) {
ImageLoader loader = ((AsyncDrawable) oldDrawable).getImageLoader();
if (loader != null && !loader.stopped) {
if (key.equals(loader.key)) {
// repetitive url and options binding to the same View.
// not need callback to ui.
// key相同不做处理, url没有变换.
// key不同, 取消之前的, 开始新的加载
return null;
} else {
loader.cancel();
}
}
} else if (oldDrawable instanceof ReusableDrawable) {
MemCacheKey oldKey = ((ReusableDrawable) oldDrawable).getMemCacheKey();
if (oldKey != null && oldKey.equals(key)) {
MEM_CACHE.put(key, oldDrawable);
}
}
就是上述代码就解决了我们场景1和2中可能遇到的比如说图片闪烁或者超出屏幕之外的不必要的请求等问题。
下面我们就通过整个流程来分析一下作者的实现思路。
首先我们来看下Bitmap这个模块设置图片的流程图

其实如果你看了比较流行的UIL以及Volley等框架的网络图片的加载的话 你会发现其实他们的流程基本是一致的 也就是说我们加载图片的整个过程基本是类似的 不同只是一些代码的实现细节方面 比如缓存机制啊 网络加载机制啊 等等。
所以我们就根据这个流程图来看一下这个模块的设计
Xutils3.0中对于图片的加载遵循其实也遵循上面的那个流程图 虽然这个流程图是Xutils第一个版本的 但是对于Xutils3.0来说照样适用 我们来从源码中来分析一下
-
x.image().bind(holder.imgItem,
imgSrcList.get(position),
imageOptions,
new CustomBitmapLoadCallBack(holder));
首先绑定Imageview 并且设置配置参数 以及回调函数
2.static Cancelable doBind(final ImageView view,
final String url,
final ImageOptions options,
final Callback.CommonCallbackcallback) {
这个是调用ImageLoader类的doBind方法实现ImageView和ImageLoader的绑定 然后我们来看一下这个方法里面的核心代码逻辑:第一步: // check params
ImageOptions localOptions = options;
{
if (view == null) {
postArgsException(null, localOptions, "view is null", callback);
return null;
}if (TextUtils.isEmpty(url)) { postArgsException(view, localOptions, "url is null", callback); return null; } if (localOptions == null) { localOptions = ImageOptions.DEFAULT; } localOptions.optimizeMaxSize(view); }
这个就是首先对我们配置的图片的Options进行检查 这个没什么好说的
第二步:
// stop the old loader
MemCacheKey key = new MemCacheKey(url, localOptions);
Drawable oldDrawable = view.getDrawable();
//每一个View都会绑定一个Drawable
//如果加载出来的类型都是ReusableDrawable 没有加载出来之前都是AsyncDrawable
if (oldDrawable instanceof AsyncDrawable) {
ImageLoader loader = ((AsyncDrawable) oldDrawable).getImageLoader();
if (loader != null && !loader.stopped) {
if (key.equals(loader.key)) {
// repetitive url and options binding to the same View.
// not need callback to ui.
// key相同不做处理, url没有变换.
// key不同, 取消之前的, 开始新的加载
return null;
} else {
loader.cancel();
}
}
} else if (oldDrawable instanceof ReusableDrawable) {
MemCacheKey oldKey = ((ReusableDrawable) oldDrawable).getMemCacheKey();
if (oldKey != null && oldKey.equals(key)) {
MEM_CACHE.put(key, oldDrawable);
}
}
关键难点:
这一步就是我们在这个模块开头处提到的处理逻辑了 其实实现原理就是 当我们Imageview绑定一个drawable的时候但是并没有被销毁的时候 我们是可以获取imageview绑定的drawable对象 后面当初次加载的时候都会将imageview设置为asyncDrawable表示正在加载也就是正在请求网络下载图片 然后当用户不同滑动ListView或者不同页面之间的跳转 重新执行到这里的时候 我们就可以根据Imageview绑定的drawable对象 从而获取跟这个drawable对象关联的ImageLoader对象 然后根据加载的key来决定我们是否正在在一个相同的iamgeview加载同一个图片 还是该Imageview已经被复用但是关联的图片资源key却改变的情况 这种情况 我们就取消之前的加载 因为他已经在屏幕外了 对用户来说已经没有加载的必要了就调用loader.cancle方法了
假如 图片加载很快 用户往下拉之后 很快又往上滑动listview 此时呢 我们的imageview关联的drawable已经加载完毕 此时类型就是reusableDrawable了 此时我们就判断key是否相同 ,如果相同 那么就将该drawable 放进内存缓存中 我们就没必要进行网络请求了 这也解决了因为内存不够 不断滑动屏幕或者切换页面 导致内存缓存不足 之前的缓存被清理掉 然后因为要从 磁盘或者网络重新加载导致的屏幕闪烁问题了。
第三步:
// load from Memory Cache
Drawable memDrawable = null;
if (localOptions.isUseMemCache()) {
memDrawable = MEM_CACHE.get(key);
if (memDrawable instanceof BitmapDrawable) {
Bitmap bitmap = ((BitmapDrawable) memDrawable).getBitmap();
if (bitmap == null || bitmap.isRecycled()) {
memDrawable = null;
}
}
}
if (memDrawable != null) { // has mem cache
boolean trustMemCache = false;
try {
if (callback instanceof ProgressCallback) {
((ProgressCallback) callback).onWaiting();
}
// hit mem cache
view.setScaleType(localOptions.getImageScaleType());
view.setImageDrawable(memDrawable);
trustMemCache = true;
if (callback instanceof CacheCallback) {
trustMemCache = ((CacheCallback
if (!trustMemCache) {
// not trust the cache
// load from Network or DiskCache
return new ImageLoader().doLoad(view, url, localOptions, callback);
}
} else if (callback != null) {
callback.onSuccess(memDrawable);
}
} catch (Throwable ex) {
LogUtil.e(ex.getMessage(), ex);
// try load from Network or DiskCache
trustMemCache = false;
return new ImageLoader().doLoad(view, url, localOptions, callback);
} finally {
if (trustMemCache && callback != null) {
try {
callback.onFinished();
} catch (Throwable ignored) {
LogUtil.e(ignored.getMessage(), ignored);
}
}
}
} else {
// load from Network or DiskCache
return new ImageLoader().doLoad(view, url, localOptions, callback);
}
从英文注释 我们就可以明白 这个其实就判断是否内存缓存中存在我们想要的结果 如果存在就取出来然后调用回调方法 展示出来
但是这里面要注意的是 如果我们的回调函数的类型是CacheCallBack类型的话 那么是否从缓存中取就取决于 CacheCallBack的oncache方法的返回值了 如果为false 那就从网络或者DISK中获取了。
第四步 其实就是 if (memDrawable != null) { // has mem cache
当if判断走else逻辑的时候 我们会请求网络加载数据并放进内存缓存和磁盘缓存
return new ImageLoader().doLoad(view, url, localOptions, callback);
也就是会走这里面的逻辑。
大致步骤基本就是这样 ,但是我在研究源码的时候曾经阻塞在一个地方,就是我调用请求要求返回结果 我传进去的泛型参数是Drawable类型的 但是为什么最后变化成了AsyncDrawable 或者ReusableDrawable 这个其实就是第二步当中我们判断逻辑的实现的重要的一部分,我经过多次阅读这部分的源码 终于明白了作者的设计意图和实现方法
接下来 我就带大家回顾一下我是如何找到这个答案的。
我们接着上面的第四步继续往下分析:
在 return new ImageLoader().doLoad(view, url, localOptions, callback);
这个方法的最后调用了 cancelable = x.http().get(params, this); 看到这里大家应该很熟悉了 这其实就是我们之前分析过的Http请求的逻辑了 这个如果不明白的就往回自己看下 这里对于这一块的 如果一致的我就不重复啰嗦 我只列出来不一样的地方
经过前面Http模块的分析 我们都知道 x.http().get(params, this)这个会调用HttpManangerImpl的request方法 这里要注意一点 我们传进去的this的类型是ImageLoader类型 这个类实现了四个接口
/*此时callback类型是ImageLoader类型这个类实现了
Callback.PrepareCallback
Callback.CacheCallback
Callback.ProgressCallback
Callback.TypedCallback
Callback.Cancelable 这几个接口 然后构造HttpTask的时候将imageloader作为成员变量传进去 */
所以这里跟之前分析得不同的地方就是 当我们构造HttpTask对象的时候
//这里如果传递过来的是IamgeLoader类型的话 那么cacheCallback prepareCallback progressCallback 都会被赋值
if (callback instanceof Callback.CacheCallback) {
this.cacheCallback = (Callback.CacheCallback
}
if (callback instanceof Callback.PrepareCallback) {
this.prepareCallback = (Callback.PrepareCallback) callback;
}
if (callback instanceof Callback.ProgressCallback) {
this.progressCallback = (Callback.ProgressCallback
}
这些回调变量都会被赋值
然后在调用HttpTask的DoBackGroud方法的时候 所解析出来的请求类型是这样的
// 解析loadType
private void resolveLoadType() {
Class callBackType = callback.getClass();
if (callback instanceof Callback.TypedCallback) {
loadType = ((Callback.TypedCallback) callback).getLoadType();
} else if (callback instanceof Callback.PrepareCallback) {
loadType = ParameterizedTypeUtil.getParameterizedType(callBackType, Callback.PrepareCallback.class, 0);
} else {
loadType = ParameterizedTypeUtil.getParameterizedType(callBackType, Callback.CommonCallback.class, 0);
}
}
这个loadType的返回值就是File类型了 ((Callback.TypedCallback) callback).getLoadType();的实现
其实就是ImageLoader的实现
@Override
public Type getLoadType() {
return loadType;
}
而这个返回值是ImageLoader的成员变量
private static final Type loadType = File.class;
那么我们调用HttpTask的DoBackGroud方法中的try {
this.result = request.loadResult();
} catch (Throwable ex) {
this.ex = ex;
}的loadResult方法
public Object loadResult() throws Throwable {
return this.loader.load(this);
}
这里的loader类型其实就FileLoader了
public File load(final UriRequest request) throws Throwable 最后调用这个函数 去下载图片资源 然后将下载下来的图片对象返回给调用者
在这个方法里面我们涉及到了DiskCacheFile这个变量 其实这个就是我们之前所说的缓存机制中的磁盘缓存了 在这个方法里面会 initDiskCacheFile(request); 初始化这个变量 然后当请求数据完成之后 会对这个变量进行赋值
if (diskCacheFile != null) {
DiskCacheEntity entity = diskCacheFile.getCacheEntity();
entity.setLastAccess(System.currentTimeMillis());
entity.setEtag(request.getETag());
entity.setExpires(request.getExpiration());
entity.setLastModify(new Date(request.getLastModified()));
}
这里涉及到了Http协议中关于缓存这一块的东西 这边不了解的可以网上自行百度 这里不详细讨论 我们只说这几个变量的含义是什么意思
Request 请求头
Cache-Control: max-age=0 以秒为单位
If-Modified-Since: Mon, 19 Nov 2012 08:38:01 GMT 缓存文件的最后修改时间。
If-None-Match: "0693f67a67cc1:0" 缓存文件的Etag值
Cache-Control: no-cache 不使用缓存
Pragma: no-cache 不使用缓存
Response header
Cache-Control: public 响应被缓存,并且在多用户间共享, (公有缓存和私有缓存的区别,请看另一节)
Cache-Control: private 响应只能作为私有缓存,不能在用户之间共享
Cache-Control:no-cache 提醒浏览器要从服务器提取文档进行验证
Cache-Control:no-store 绝对禁止缓存(用于机密,敏感文件)
Cache-Control: max-age=60 60秒之后缓存过期(相对时间)
Date: Mon, 19 Nov 2012 08:39:00 GMT 当前response发送的时间
Expires: Mon, 19 Nov 2012 08:40:01 GMT 缓存过期的时间(绝对时间)
Last-Modified: Mon, 19 Nov 2012 08:38:01 GMT 服务器端文件的最后修改时间
ETag: "20b1add7ec1cd1:0" 服务器端文件的Etag值
如果想详细了解的朋友 请进入这里 作者很相信的讲解了关于Http协议中关于缓存这一块的知识
这里我就简单说一下客户端与服务器端关于缓存机制的配合 我们来看一个图:
通过最后修改时间, 来判断缓存新鲜度
- 浏览器客户端想请求一个文档, 首先检查本地缓存,发现存在这个文档的缓存, 获取缓存中文档的最后修改时间,通过: If-Modified-Since, 发送Request给Web服务器。
- Web服务器收到Request,将服务器的文档修改时间(Last-Modified): 跟request header 中的,If-Modified-Since相比较, 如果时间是一样的, 说明缓存还是最新的, Web服务器将发送304 Not Modified给浏览器客户端, 告诉客户端直接使用缓存里的版本。如下图。

- 假如该文档已经被更新了。Web服务器将发送该文档的最新版本给浏览器客户端, 如下图。

ETag是实体标签(Entity Tag)的缩写, 根据实体内容生成的一段hash字符串(类似于MD5或者SHA1之后的结果),可以标识资源的状态。 当资源发送改变时,ETag也随之发生变化。
ETag是Web服务端产生的,然后发给浏览器客户端。浏览器客户端是不用关心Etag是如何产生的。
为什么使用ETag呢? 主要是为了解决Last-Modified 无法解决的一些问题。
- 某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了。
- 某些文件的修改非常频繁,在秒以下的时间内进行修改. Last-Modified只能精确到秒。
- 一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了。
http://www.cnblogs.com/TankXiao/archive/2012/11/28/2793365.html
最后将下载下来的图片保存在本地磁盘缓存中 大家可能还是不明白是如何将Dradble转换为Async和Resueable类型的 这里我们就要进入HttpTask的DoBackGroud方法中的检查缓存那一块了
因为之前我们分析的Httpget 模块因为没有使用缓存 直接略过了 但是我们调用ImageLoader加载图片时候 就要使用缓存了 我们来看一下:
// 检查缓存
Object cacheResult = null;
if (cacheCallback != null && HttpMethod.permitsCache(params.getMethod())) {
// 尝试从缓存获取结果, 并为请求头加入缓存控制参数.
try {
clearRawResult();
LogUtil.d("load cache: " + this.request.getRequestUri());
rawResult = this.request.loadResultFromCache();
} catch (Throwable ex) {
LogUtil.w("load disk cache error", ex);
}
if (this.isCancelled()) {
clearRawResult();
throw new Callback.CancelledException("cancelled before request");
}
if (rawResult != null) {
if (prepareCallback != null) {
try {
cacheResult = prepareCallback.prepare(rawResult);
} catch (Throwable ex) {
cacheResult = null;
LogUtil.w("prepare disk cache error", ex);
} finally {
clearRawResult();
}
} else {
cacheResult = rawResult;
}
因为这里callback实现了cachecallback 并且我们使用的是get方法 所以if为true进入代码块里面执行
因为这里prepareCallback 也不为空 所以就调用了prepare 方法 这里进入了Imageloader的prepare 方法 我们来看一下 :
@Override
public Drawable prepare(File rawData) {
if (!validView4Callback(true)) return null;
try {
Drawable result = null;
if (prepareCallback != null) {
result = prepareCallback.prepare(rawData);
}
if (result == null) {
result = ImageDecoder.decodeFileWithLock(rawData, options, this);
}
if (result != null) {
if (result instanceof ReusableDrawable) {
((ReusableDrawable) result).setMemCacheKey(key);
MEM_CACHE.put(key, result);
}
}
return result;
} catch (IOException ex) {
IOUtil.deleteFileOrDir(rawData);
LogUtil.w(ex.getMessage(), ex);
}
return null;
}
看到这里 我们找到了ImageDecoder.decodeFileWithLock 这里其实就是真正进行转换的地方 我们进去看下源码就立马清楚了
f (bitmap != null) {
result = new ReusableBitmapDrawable(x.app().getResources(), bitmap);
}
这个方法最后对bitmap进行了封装 然后将封装后的结果返回给调用者 看到了吧 类型是
ReusableBitmapDrawable
然后在ImageLoder的prepare方法中将ImageDecoder.decodeFileWithLock 返回的结果 if (result != null) {
if (result instanceof ReusableDrawable) {
((ReusableDrawable) result).setMemCacheKey(key);
MEM_CACHE.put(key, result);
}
}放进内存缓存中 这就是整个的缓存的流程
相信大家可能还是有点云里雾里 但是我觉得大致思路知道了之后i 自己再去看一遍源码 我觉得就应该能够清楚了吧
这段逻辑比较复杂 所以这里我们使用一个时序图帮大家屡一下思路

上面这个时序图就是整个请求网络图片的过程 ,其中有一段是关于图片缓存的这一块比较复杂 所以我会单独再画一个时序图 来专门讲解图片缓存的时序图
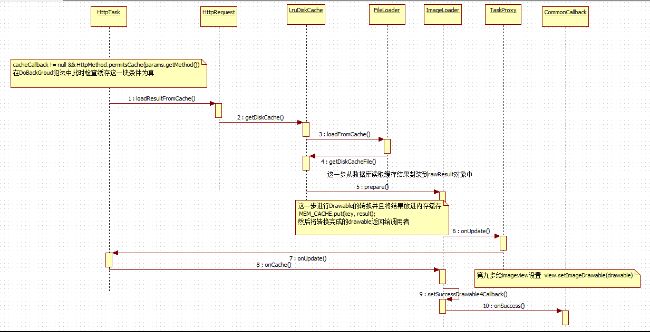
这里面有一个关键的地方就是在HttpTask的doBackgroud方法中 有一段这样的代码:
if (cacheResult != null) {
// 同步等待是否信任缓存
this.update(FLAG_CACHE, cacheResult);
while (trustCache == null) {
synchronized (cacheLock) {
try {
cacheLock.wait();
} catch (Throwable ignored) {
}
}
}
// 处理完成
if (trustCache) {
return null;
}
}
这段代码的作用就是给你一个机会让你去调用你实现的OncacheCallback中的oncache方法 然后根据返回结果 来决定是否进行下一步的网络请求 如果你oncache方法返回true说明你信任缓存 此时直接return null 就不再往下进行 直接使用缓存的值
如果不信任缓存的话 那么就进行网络请求
好了 IamgeFragment这一模块也基本分析完成了 几个需要注意的点就是:
1.缓存机制是如何使用的?包括内存缓存和磁盘缓存
2.我们自己设置的CacheCallback在什么时候调用的 起到了什么作用
3.关于Http协议的缓存部分的理解
我相信 只要上面三点弄明白了 我觉得这一块也就没什么问题了
5.Xutils3.0总结
整个Xutils3.0的源码基本分析完成了 ,整个框架还是很不错的 整体的设计也比较简洁,我相信读者看完我的分析之后 对于日常当中的使用应该不会有太大问题,出问题了 就深入去看源码 你就会找到根源 基本能够彻底的解决开发过程中出现的BUG了
下面简单总结一下吧:
1.学会使用Xutils3.0请求服务器数据以及请求参数的设置
2.掌握Xutils3.0中关于缓存机制的应用
3.了解Xutils3.0中对Google官方推荐内存缓存LRU的使用方法
4.能够在自己的项目当中使用Xutils3.0进行网络 、数据库、图片的处理
我相信 学以致用才是最好的理解一个框架的方法 只有在使用过程当中 发现问题解决问题 才能够真正理解作者的设计思想以及提高自身代码质量。
初次分享 ,可能有很多地方表达不是很流畅,希望大家指正 也帮我弥补自己的不足 。