源数据中没有你想要的数据?源数据中的列不能满足分析所需要的格式?这些问题,在KAP v2.4版本中都得到了修复!你可以用KAP生成新的可计算列,并把它应用在Cube中,利用Cube预计算而获得性能优势。今天,我们将详细介绍可计算列的使用方法。
Kyligence Analytics Platform (KAP) 大数据智能分析平台是基于Apache Kylin的,在超大数据集上提供亚秒级分析能力的企业级数据仓库产品,为业务用户、分析师及工程师提供简便、快捷的大数据分析服务。在继承Apache Kylin的高性能查询、易用建模,多协议支持、非侵入式架构等突出优点的同时,KAP在企业用户所关注的实施效率、安全可控、性能优化、自助式敏捷BI、系统监控等方面进行了全方位的创新,被誉为目前最为成熟的OLAP on Hadoop产品。
概念介绍
如果你的源数据中没有你想要的数据,或者源数据中的列不能满足分析所需要的格式,现在你可以用KAP生成新的可计算列,并把它应用在Cube中,以利用Cube预计算而获得性能优势。举个例子,你可以使用销量减去成本计算出利润,或者你可以把数字文字混合的字段拆分成两个可计算列,你也可以使用函数对数据的类型进行转换。
你可以利用源数据中的字段搭配运算符或函数定义可计算列,如A= B*C 或A= Year (B)。可计算列是定义在KAP(Kylin)数据模型层上的,可计算列定义后在Cube构建阶段和一般源数据列无异,也会被一起进行预计算,这样一方面方便分析师灵活自主的创建所需的可计算列,另一方面也使可计算列利用预计算技术,充分发挥Cube的性能优势。
可计算列是KAP 2.4新推出的一个功能,下面我们就将详细介绍可计算列的使用方法。
使用引导
我们以Learn_kylin这个KAP自带的样例数据集为例子,介绍如何使用可计算列。关于样例数据集的具体介绍可以参考KAP用户手册中的介绍,这里不再做详细介绍。
在KAP中打开learn_kylin自带的数据模型,点击下图箭头所示的计算器按钮,就可以创建可计算列。
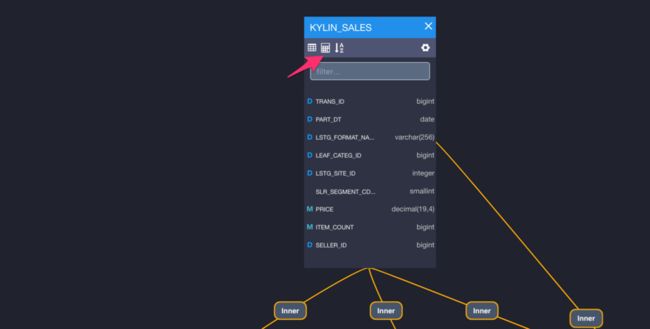
首先我们建立几个可计算列:
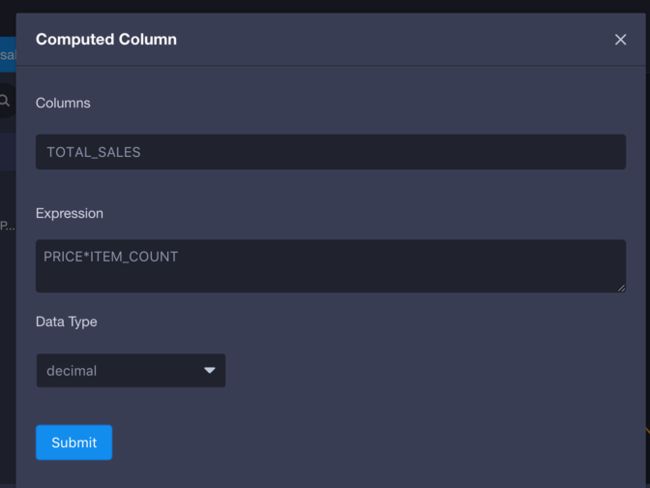
total_sales=price*item_count
part_year= year (part_dt)
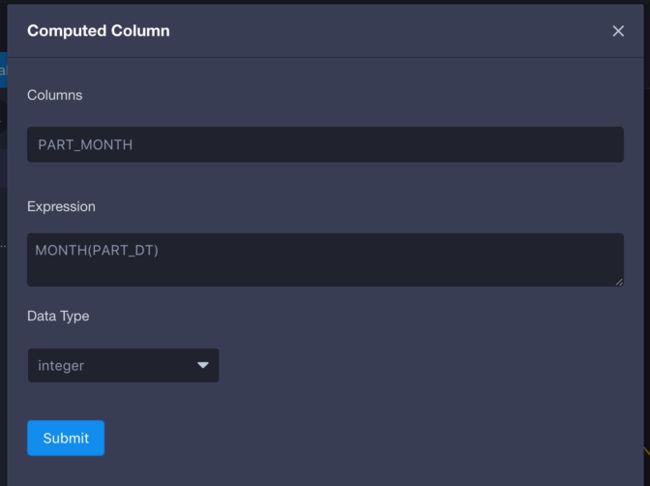
part_month =month (part_dt)
其中需要填写:
· 列:定义可计算列的名称
· 表达式:可计算列的表达式定义。注意:允许使用当前表上的列进行计算,暂不支持跨表的表达式
· 数据类型:定义可计算列的返回结果类型
参考下图我们可以创建这三个可计算列。

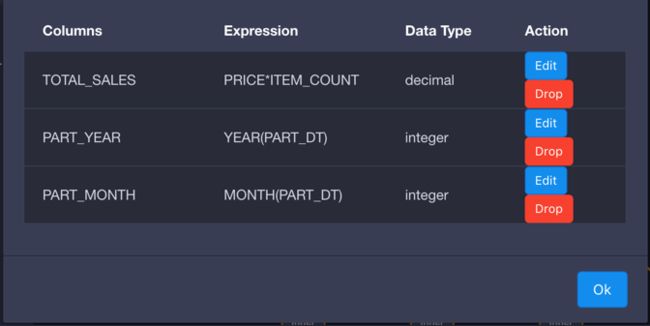
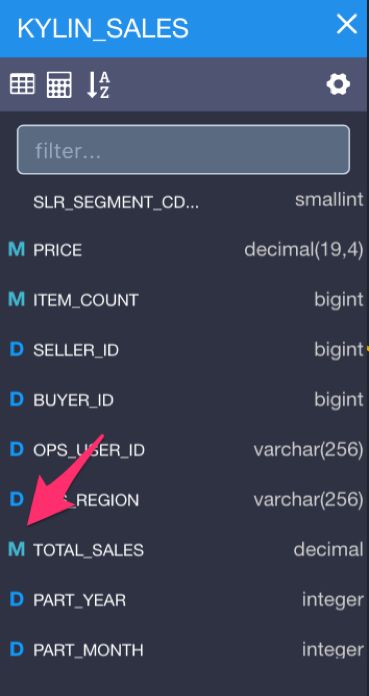
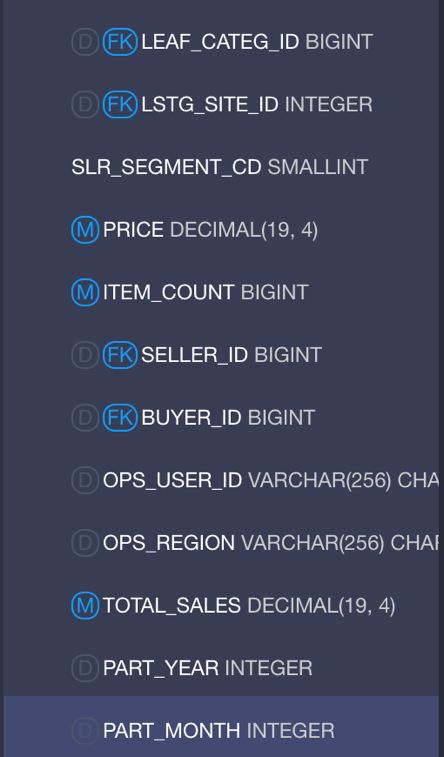
这样我们就在数据模型中生成了几个可计算列,下面不要忘记给可计算列定义数据类型,在Kylin_Sales表中下拉到列表最下方可以看到刚才定义的可计算列,在列名左侧点击切换列为度量或者维度。
其中Total_sales为度量(Measure)设置为字母M,Part_Year和Part_Month为维度,设置为D。
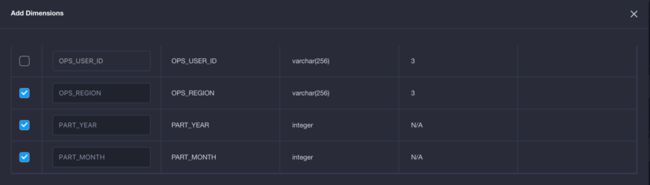
在模型中定义完可计算列后,需要在创建Cube添加维度/度量的时候选入可计算列,可计算列被放在Cube中预计算后,才能利用上Cube的性能优势。
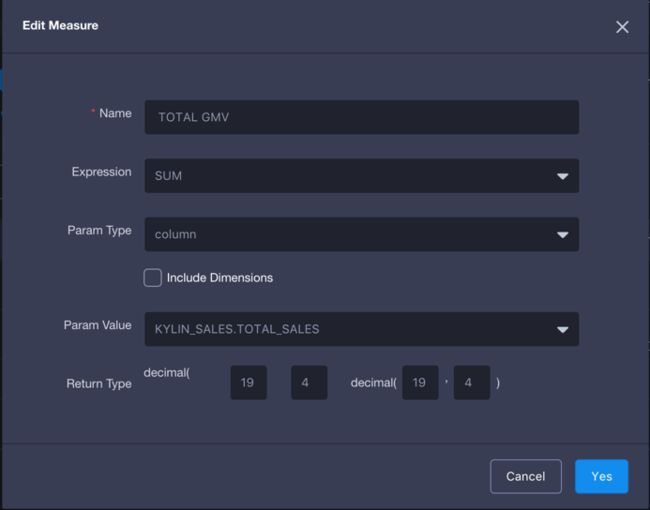
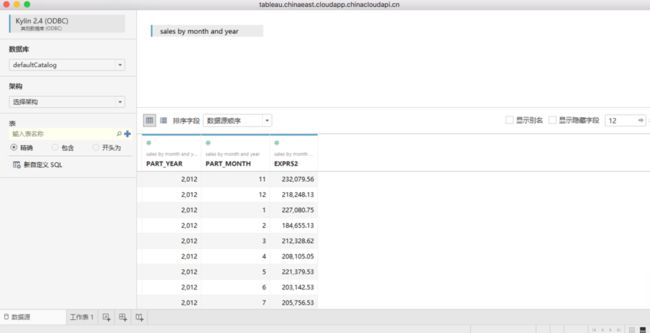
Cube构建好后就可以使用可计算列了,可以在KAP的分析页面中测试一下,在可查询的列表中,可以看到之前定义的可计算列PART_YEAR, PART_MONTH和 TOTAL_SALES
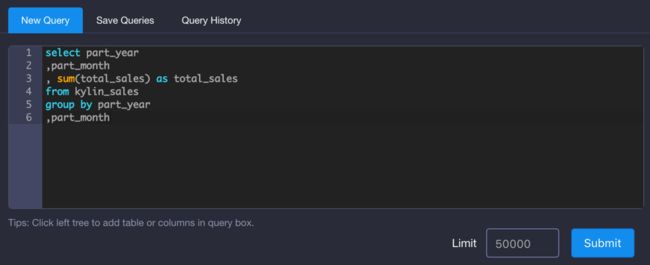
接下来我们在KAP的分析页面中运行一段SQL测试一下:
select part_year
,part_month
, sum(total_sales) as total_sales
from kylin_sales
group by part_year
,part_month
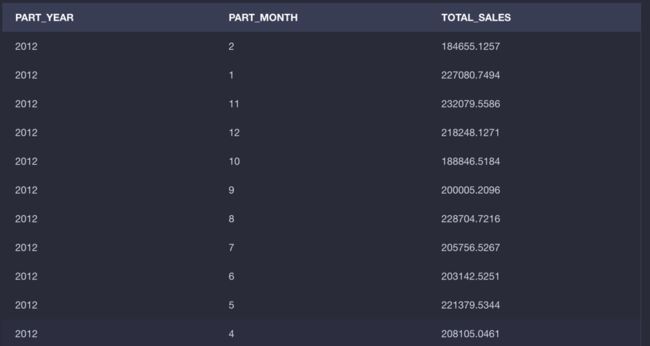
如下图所示,可以看到在模型中定义的可计算列PART_YEAR, PART_MONTH和 TOTAL_SALES可以正常返回结果了。
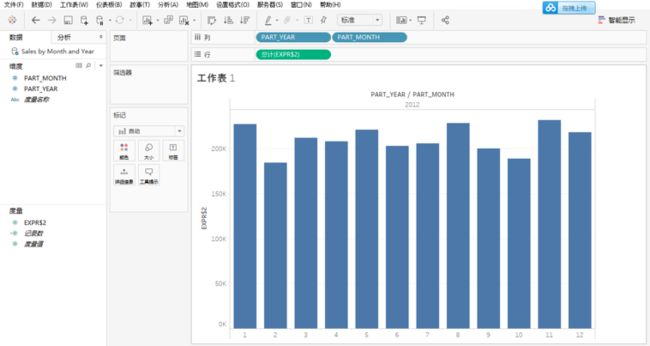
使用Tableau连接KAP,运行同一查询也可返回结果,这样就可以把可计算列中计算出来的额外字段应用在分析中了。
可计算列使用的一些规则
· KAP 2.4中,仅支持在事实表上定义可计算列(暂不支持跨表定义或在维度表上定义)。
· 用户可以在多个模型上定义不同的可计算列。
· 同一张表中,可计算列的名字和表达式(计算逻辑)是一一对应的。
利用隐式查询使用可计算列
在一个表上创建了可计算列后,逻辑上这个可计算列就被加入到了这个表的列集合中。用户可以像查询普通的列一样查询这个列。在上面的kylin_sales例子中,如果用户创建并构建了一个包含sum(total_sales)度量的cube,用户可以直接查询select sum(total_sales) from kylin_sales。我们将这种查询方式成为可计算列的显式查询。
另一方面,由于不少查询语句是BI工具自动生成的,并不能直接显式使用可计算列。这种情况下,KAP支持直接使用可计算列背后的表达式进行查询。接着上面的例子,用户可以查询select sum(price*item_count) from kylin_sales。KAP会分析到price*item_count可以由可计算列total_sales替代,且sum(total_sales)已经在某个cube中被预计算完毕,为了更好的性能,KAP会将用户原始查询重写为select sum(total_sales) from kylin_sales,以求更佳的性能。我们将这种查询方式称为可计算列的隐式查询。
隐式查询默认没有被开启,为了开启它,用户需要在KYLIN_HOME/conf/kylin.properties中添加kylin.query.transformers=org.apache.kylin.query.util.ConvertToComputedColumn
如下图所示我们在SQL中同时使用显式查询和隐式查询,可以得到同样的结果,而且这两个查询都击中了Cube中的可计算列。
select part_year
,part_month
, sum(total_sales) as total_sales
,sum(price*item_count) as total_sales_2
from kylin_sales
group by part_year
,part_month
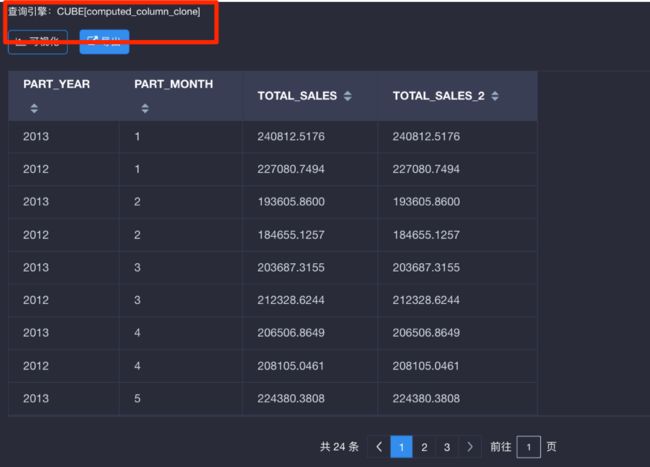
请注意使用隐式查询击中Cube在KAP 2.4版中暂不支持加法或乘法的交换律,如在上例中可计算列Total_sales 被定义为price*item_count,那么在查询中只能使用sum(price*item_count)才能击中Cube中的可计算列,而使用sum(item_count* price)则无法击中。
高级函数的使用
当前KAP 2.4可计算列的计算是直接下沉到数据源进行处理的,而当前Hive是KAP的默认数据源,因此可计算列的表达式定义默认需要以hive SQL的语法为准。
下面我们示范三个高级函数在可计算列中的使用,欲在可计算列中使用更多的函数,请在下面链接中参考Hive SQL函数的使用规范。
使用条件函数CASE WHEN
在Hive SQL的语法为:
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
使用CASE语句可以方便的对字段进行分组,是分析中最常用的条件函数。
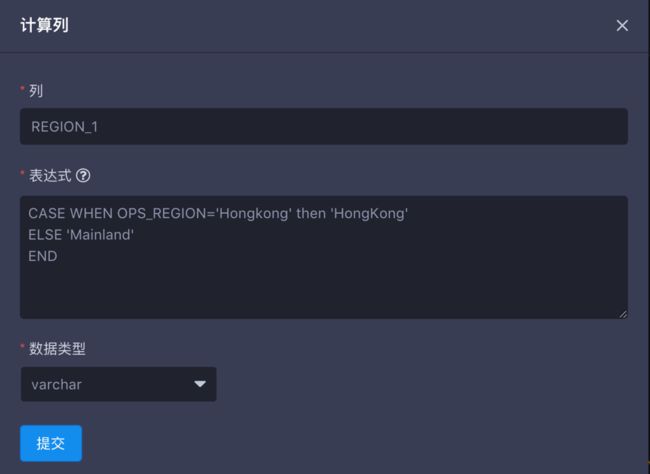
仍以Learn_kylin样例数据集为例,我们将样例数据集中的OPS_REGION进行进一步分组,分为大陆和香港,可计算列定义如下:
CASE WHEN OPS_REGION='Hongkong' then 'HongKong'
ELSE 'Mainland'
END
使用字符串函数Concat
使用concat可以快速的将两个或多个字符串进行连接。
在Hive SQL的语法为concat(string|binary A, string|binary B...)
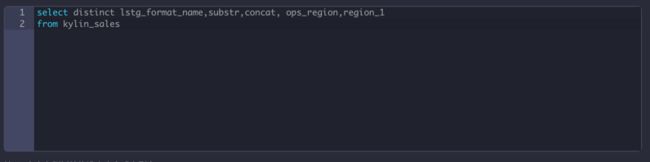
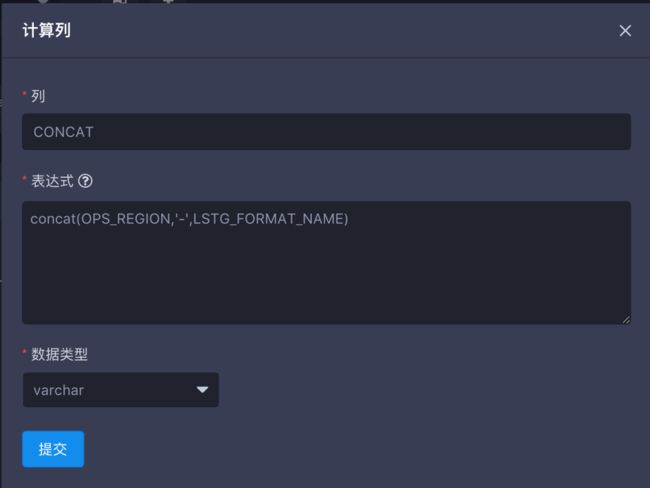
注意这里仅能关联两个字符串函数,如果类型不是字符串的需要先对类型进行转换。示例中,我们把两个字符串进行连接,如下图:
concat(OPS_REGION,'-',LSTG_FORMAT_NAME)
使用字符串函数Substr
Substr可以用来截取字符串中的一部分,函数中三个变量分别可以指定截取的字符串,字符串截取的开始位置和截取长度。
在Hive SQL的语法为substr(string|binary A, int start, int len)
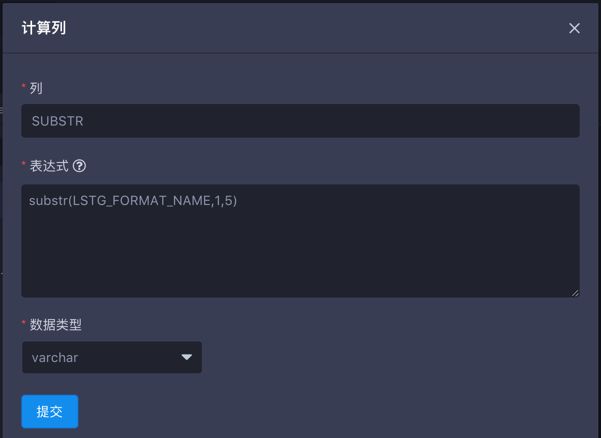
我们定义示例可计算列如下:
substr(LSTG_FORMAT_NAME,1,5)
分析场景中,经常会需要对一个字符串针对一个特定的连接符进行截取,而连接符的位置不固定,这种情况下可以配合使用函数locate(string substr, string str[, int pos])找到连接符的位置,再使用substr进行截取。
使用模型监测检查函数语法
增加了新的可计算列后建议对新修改的模型进行健康监测,由于可计算列中的函数是由用户手写输入的,有可能会有语法错误,如出现语法错误或函数不支持的情况,使用模型检测可以提前发现,以避免构建Cube长时间后出现运行失败的情况。
模型检测在保存模型的窗口处就可以勾选。
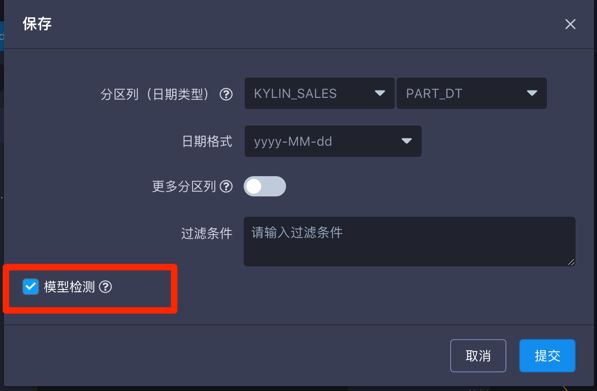
模型检测成功后,模型名称右侧会出现绿色打勾符号。
接下来把新定义的可计算列放入Cube中,并进行Cube构建,过程与前文一致,在此不做赘述。Cube构建成功后,在KAP中的页面运行SQL即可调用到这些已定义好的可计算列了。