图片.png

图片.png
Q
- 解码器抽象解码过程?
- netty提供哪些拆箱即用的解码器?解码器基类与常见解码器解析
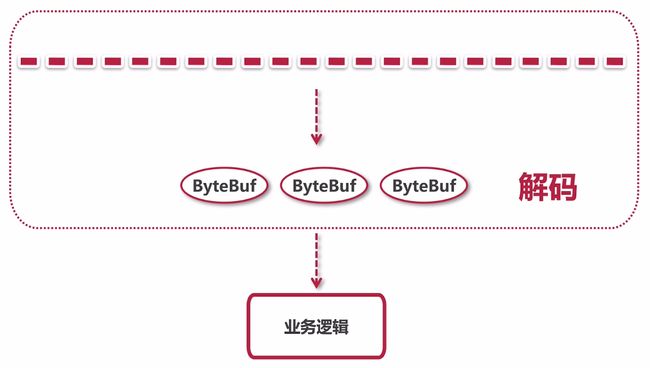
一、ByteToMessageDecoder解码步骤
- **累加字节流
设置first为cumulation是否为空,累加器为空表赋值为读进来的ByteBuf对象,累加器非空调用cumulator的cumulate()方法通过ByteBuffer的writeBytes()方法把当前累加器里面的数据和读进来的数据进行累加 - 调用子类的decode方法进行解析
调用callDecode()方法将累加器数据解析到的对象放到CodecOutputList向下进行传播,循环判断累加器里面是否有数据,通过调用fireChannelRead()方法向下进行事件传播,调用decode()方法ByteBuf解码根据不同协议子类的解码器把当前读到的所有数据即累加器里面的数据取出二进制数据流解析放进CodecOutputList - 将解析到的ByteBuf向下传播
调用fireChannelRead()方法循环遍历CodecOutputList通过事件传播机制ctx.fireChannelRead()调用CodecOutputList的getUnsafe()方法获取ByteBuf把解析到的ByteBuf对象向下进行传播
ByteToMessageDecoder.channelRead
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {//基于ByteBuf解码
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;//初始化cumulation
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);//累加
}
callDecode(ctx, cumulation, out);//解析cumulation中ByteBuf到OutputList
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
fireChannelRead(ctx, out, size);//解析出的数据outlist,向后传播
out.recycle();//outlist回收
}
} else {
ctx.fireChannelRead(msg);
}
}
cumulator.cumulate
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
final ByteBuf buffer;
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());//cumulation扩容
} else {
buffer = cumulation;
}
buffer.writeBytes(in);
in.release();
return buffer;
}
};
callDecode
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List二、基于固定长度解码器分析FixedLengthFrameDecoder
基于固定长度解码器FixedLengthFrameDecoder成员变量frameLength表示固定长度,解码器以多少长度分割解析,构造方法传参frameLength赋值给frameLength保存。
调用decode()方法解析累加器数据添加到CodecOutputList,判断累加器可读字节是否小于frameLength,小于返回空表示没有从累加器里面读取数据,反之调用readRetainedSlice()方法从当前累加器里面截取frameLength长度ByteBuf,返回从当前readerIndex开始增加frameLength长度的Buffer子区域新保留切片。
FixedLengthFrameDecoder
/**
* A decoder that splits the received {@link ByteBuf}s by the fixed number
* of bytes. For example, if you received the following four fragmented packets:
*
* +---+----+------+----+
* | A | BC | DEFG | HI |
* +---+----+------+----+
*
* A {@link FixedLengthFrameDecoder}{@code (3)} will decode them into the
* following three packets with the fixed length:
* 如果固定长度为3,上面数据包会被解析成如下:
*
* +-----+-----+-----+
* | ABC | DEF | GHI |
* +-----+-----+-----+
*
*/
public class FixedLengthFrameDecoder extends ByteToMessageDecoder {
private final int frameLength;
public FixedLengthFrameDecoder(int frameLength) {
if (frameLength <= 0) {
throw new IllegalArgumentException(
"frameLength must be a positive integer: " + frameLength);
}
this.frameLength = frameLength;
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List三、行解码器分析LineBasedFrameDecoder
基于行解码器LineBasedFrameDecoder
- 成员变量
maxLength[行解码器解析数据包最大长度],failFast[超越最大长度是否立即抛异常],
stripDelimiter[解析数据包是否带换行符,换行符支持\n和\r],
discarding[解码过程是否处于丢弃模式],
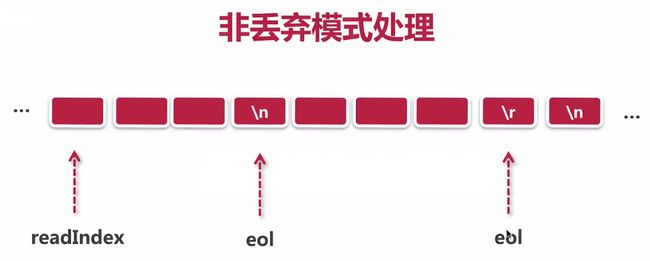
discardedBytes[解码过程丢弃字节], - 调用decode()方法解析累加器cumulation数据把数据包添加到CodecOutputList,通过findEndOfLine()方法从累加器ByteBuf里面查找获取行的结尾eol即\n或者\r\n,
- 非丢弃模式查找到行的结尾eol计算从换行符到可读字节的长度length和分隔符的长度判断length是否大于解析数据包最大长度maxLength,大于maxLength则readerIndex指向行的结尾eol后面的可读字节丢弃数据通过fail()方法传播异常,判断分隔符是否算在完整数据包范畴从buffer分割length长度获取新保留切片并且buffer跳过分隔符readerIndex指向分隔符后面的可读字节,
- 未查找到行的结尾eol获取可读字节长度length超过解析数据包最大长度maxLength赋值discardedBytes为length读指针readerIndex指向写指针writerIndex赋值discarding为true进入丢弃模式并且根据failFast调用fail()方法立即传播fail异常,
- 丢弃模式查找到行的结尾eol按照丢弃字节+从换行符到可读字节的长度计算length和换行符长度将readerIndex指向丢弃字节换行符后面的可读字节赋值discardedBytes为0并且discarding为false表示当前属于非丢弃模式,根据failFast调用fail()方法立即传播fail异常,
未查找到行的结尾eol则discardedBytes增加buffer的可读字节并且读指针readerIndex指向写指针writerIndex
图片.png
public class LineBasedFrameDecoder extends ByteToMessageDecoder {
/** Maximum length of a frame we're willing to decode. */
private final int maxLength;// 最大长度
/** Whether or not to throw an exception as soon as we exceed maxLength. */
private final boolean failFast;//是否快速失败
private final boolean stripDelimiter;//解析的数据包时候带换行符,false带,true不带
/** True if we're discarding input because we're already over maxLength. */
private boolean discarding;//超过最大长度时候抛弃
private int discardedBytes;//抛弃的字节数
/**
* Creates a new decoder.
* @param maxLength the maximum length of the decoded frame.
* A {@link TooLongFrameException} is thrown if
* the length of the frame exceeds this value.
*/
public LineBasedFrameDecoder(final int maxLength) {
this(maxLength, true, false);
}
/**
* Creates a new decoder.
* @param maxLength the maximum length of the decoded frame.
* A {@link TooLongFrameException} is thrown if
* the length of the frame exceeds this value.
* @param stripDelimiter whether the decoded frame should strip out the
* delimiter or not
* @param failFast If true, a {@link TooLongFrameException} is
* thrown as soon as the decoder notices the length of the
* frame will exceed maxFrameLength regardless of
* whether the entire frame has been read.
* If false, a {@link TooLongFrameException} is
* thrown after the entire frame that exceeds
* maxFrameLength has been read.
*/
public LineBasedFrameDecoder(final int maxLength, final boolean stripDelimiter, final boolean failFast) {
this.maxLength = maxLength;
this.failFast = failFast;
this.stripDelimiter = stripDelimiter;
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List四、分隔符解码器DelimiterBasedFrameDecoder
图片.png
public class DelimiterBasedFrameDecoder extends ByteToMessageDecoder {
private final ByteBuf[] delimiters;
private final int maxFrameLength;
private final boolean stripDelimiter;
private final boolean failFast;
private boolean discardingTooLongFrame;
private int tooLongFrameLength;
/** Set only when decoding with "\n" and "\r\n" as the delimiter. */
private final LineBasedFrameDecoder lineBasedDecoder;
public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf delimiter) {
this(maxFrameLength, true, delimiter);
}
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, ByteBuf delimiter) {
this(maxFrameLength, stripDelimiter, true, delimiter);
}
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, boolean failFast,
ByteBuf delimiter) {
this(maxFrameLength, stripDelimiter, failFast, new ByteBuf[] {
delimiter.slice(delimiter.readerIndex(), delimiter.readableBytes())});
}
public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf... delimiters) {
this(maxFrameLength, true, delimiters);
}
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, ByteBuf... delimiters) {
this(maxFrameLength, stripDelimiter, true, delimiters);
}
//构造方法
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf... delimiters) {
validateMaxFrameLength(maxFrameLength);
if (delimiters == null) {
throw new NullPointerException("delimiters");
}
if (delimiters.length == 0) {
throw new IllegalArgumentException("empty delimiters");
}
if (isLineBased(delimiters) && !isSubclass()) {//初始化行解码器
lineBasedDecoder = new LineBasedFrameDecoder(maxFrameLength, stripDelimiter, failFast);
this.delimiters = null;
} else {
this.delimiters = new ByteBuf[delimiters.length];
for (int i = 0; i < delimiters.length; i ++) {
ByteBuf d = delimiters[i];
validateDelimiter(d);
this.delimiters[i] = d.slice(d.readerIndex(), d.readableBytes());
}
lineBasedDecoder = null;
}
this.maxFrameLength = maxFrameLength;
this.stripDelimiter = stripDelimiter;
this.failFast = failFast;
}
/**判断分隔符是否是 "\n" and "\r\n",是则为行解码器 */
private static boolean isLineBased(final ByteBuf[] delimiters) {
if (delimiters.length != 2) {
return false;
}
ByteBuf a = delimiters[0];
ByteBuf b = delimiters[1];
if (a.capacity() < b.capacity()) {
a = delimiters[1];
b = delimiters[0];
}
return a.capacity() == 2 && b.capacity() == 1
&& a.getByte(0) == '\r' && a.getByte(1) == '\n'
&& b.getByte(0) == '\n';
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List五、基于长度域解码器LengthFieldBasedFrameDecoder
1、成员变量解析
- lengthFieldOffset:长度域偏移量即长度域在二进制数据流里面偏移量
- lengthFieldLength:长度域长度即从长度域开始往后几个字节组合起来表示长度
- lengthAdjustment:长度域表示长度+额外调整长度=数据包长度,即长度域计算完整数据包长度,长度额外调整
- initialBytesToStrip:decode出完整数据包之后向下传播的时候是否需要砍掉几个字节即解析数据包前面跳过字节
构造函数
public LengthFieldBasedFrameDecoder(
ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
if (byteOrder == null) {
throw new NullPointerException("byteOrder");
}
if (maxFrameLength <= 0) {
throw new IllegalArgumentException(
"maxFrameLength must be a positive integer: " +
maxFrameLength);
}
if (lengthFieldOffset < 0) {
throw new IllegalArgumentException(
"lengthFieldOffset must be a non-negative integer: " +
lengthFieldOffset);
}
if (initialBytesToStrip < 0) {
throw new IllegalArgumentException(
"initialBytesToStrip must be a non-negative integer: " +
initialBytesToStrip);
}
if (lengthFieldOffset > maxFrameLength - lengthFieldLength) {
throw new IllegalArgumentException(
"maxFrameLength (" + maxFrameLength + ") " +
"must be equal to or greater than " +
"lengthFieldOffset (" + lengthFieldOffset + ") + " +
"lengthFieldLength (" + lengthFieldLength + ").");
}
this.byteOrder = byteOrder;
this.maxFrameLength = maxFrameLength;
this.lengthFieldOffset = lengthFieldOffset;
this.lengthFieldLength = lengthFieldLength;
this.lengthAdjustment = lengthAdjustment;
lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength;
this.initialBytesToStrip = initialBytesToStrip;
this.failFast = failFast;
}
示例1
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 0 (= do not strip header)
* BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 2);
1.第一个参数是 maxFrameLength 表示的是包的最大长度,超出包的最大长度netty将会做一些特殊处理,后面会讲到
2.第二个参数指的是长度域的偏移量lengthFieldOffset,在这里是0,表示无偏移
3.第三个参数指的是长度域长度lengthFieldLength,这里是2,表示长度域的长度为2
示例2
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 2 (= the length of the Length field)
* BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
* +--------+----------------+ +----------------+
* | Length | Actual Content |----->| Actual Content |
* | 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
* +--------+----------------+ +----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 2, 0, 2);
前面三个参数的含义和上文相同
第四个参数lengthAdjustment,后面再讲
第五个参数就是initialBytesToStrip,这里为2,表示获取完一个完整的数据包之后,忽略前面的2个字节(长度)
示例3
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = -2 (= the length of the Length field)
* initialBytesToStrip = 0
*
* BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 2,-2,0);
lengthFieldLength 是2,lengthAdjustment为-2,表示数据包长度0x000E-2,即为0x000C
示例4
* lengthFieldOffset = 2 (= the length of Header 1)
* lengthFieldLength = 3
* lengthAdjustment = 0
* initialBytesToStrip = 0
*
* BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
* | 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 2, 3, 0, 0);
长度域偏移为2,长度域大小为3,即0x00000C
示例5
* lengthFieldOffset = 0
* lengthFieldLength = 3
* lengthAdjustment = 2 (= the length of Header 1)
* initialBytesToStrip = 0
*
* BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
* | 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 3, 2, 0);
长度域中0x00000C ,Header 占用2字节,所以数据包长度为0x00000C +2(lengthAdjustment)
示例6
* lengthFieldOffset = 1 (= the length of HDR1)
* lengthFieldLength = 2
* lengthAdjustment = 1 (= the length of HDR2)
* initialBytesToStrip = 3 (= the length of HDR1 + LEN)
*
* BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
* | 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+
new LengthFieldBasedFrameDecoder(Integer.MAX, 1, 2, 1, 3);
数据包长度为0x000C +1(lengthAdjustment),截取前面3(initialBytesToStrip)个字节
示例7
* lengthFieldOffset = 1
* lengthFieldLength = 2
* lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
* initialBytesToStrip = 3
*
* BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
* | 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+
2、decode方法分析
- 计算需要抽取的数据包长度。
- 跳过字节逻辑处理。
- 丢弃模式下的处理。
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (discardingTooLongFrame) {//先判断是否丢弃模式,进行丢弃处理
long bytesToDiscard = this.bytesToDiscard;//待丢弃的字节数
int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes());//
in.skipBytes(localBytesToDiscard);
bytesToDiscard -= localBytesToDiscard;//待丢弃的字节数减去本次已丢弃,即下次需丢弃的字节数
this.bytesToDiscard = bytesToDiscard;
failIfNecessary(false);
}
//如果当前可读字节数还未到达长度域结尾,则不足以解析数据包
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;//长度域绝对位置
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);//抽取的数据包长度
if (frameLength < 0) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"negative pre-adjustment length field: " + frameLength);
}
frameLength += lengthAdjustment + lengthFieldEndOffset;//实际抽取的数据包长度
if (frameLength < lengthFieldEndOffset) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than lengthFieldEndOffset: " + lengthFieldEndOffset);
}
if (frameLength > maxFrameLength) {//数据包长度大于maxFrameLength,进去丢弃模式
long discard = frameLength - in.readableBytes();
tooLongFrameLength = frameLength;
if (discard < 0) {
// buffer contains more bytes then the frameLength so we can discard all now
in.skipBytes((int) frameLength);//直接丢弃frameLength长度的数据包
} else {
// Enter the discard mode and discard everything received so far.
discardingTooLongFrame = true;//丢弃模式
bytesToDiscard = discard;//还需要丢弃字节数
in.skipBytes(in.readableBytes());
}
failIfNecessary(true);//
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
if (in.readableBytes() < frameLengthInt) {//可读数据小于实际抽取的数据包长度,即不完整数据包
return null;
}
if (initialBytesToStrip > frameLengthInt) {
in.skipBytes(frameLengthInt);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than initialBytesToStrip: " + initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);//跳过字节数
// extract frame
int readerIndex = in.readerIndex();//读指针
int actualFrameLength = frameLengthInt - initialBytesToStrip;//实际数据包
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
//支持1、2、3、4、8的length
protected long getUnadjustedFrameLength(ByteBuf buf, int offset, int length, ByteOrder order) {
buf = buf.order(order);
long frameLength;
switch (length) {
case 1:
frameLength = buf.getUnsignedByte(offset);
break;
case 2:
frameLength = buf.getUnsignedShort(offset);
break;
case 3:
frameLength = buf.getUnsignedMedium(offset);
break;
case 4:
frameLength = buf.getUnsignedInt(offset);
break;
case 8:
frameLength = buf.getLong(offset);
break;
default:
throw new DecoderException(
"unsupported lengthFieldLength: " + lengthFieldLength + " (expected: 1, 2, 3, 4, or 8)");
}
return frameLength;
}
protected ByteBuf extractFrame(ChannelHandlerContext ctx, ByteBuf buffer, int index, int length) {
return buffer.retainedSlice(index, length);
}