
先看一下 官方GUI 的初步使用
campass 的 增删改查 操作
-
campass 插入数据
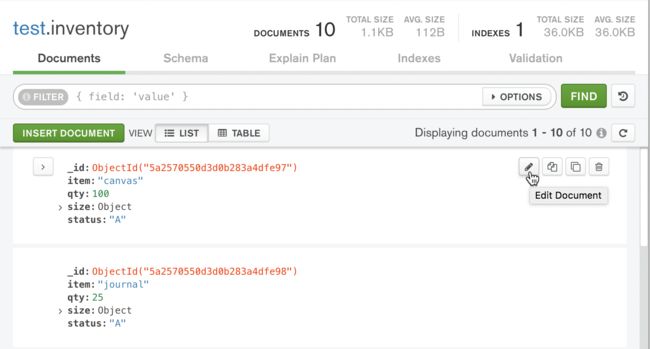
点击 insert document
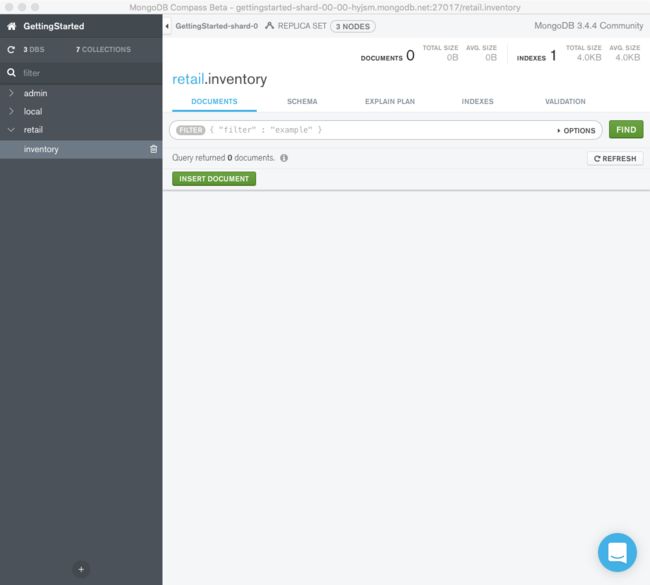
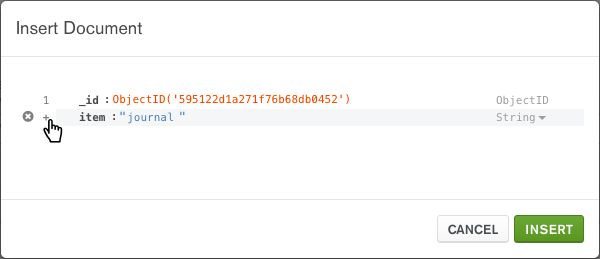
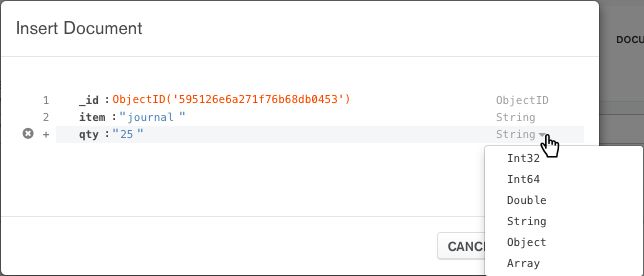
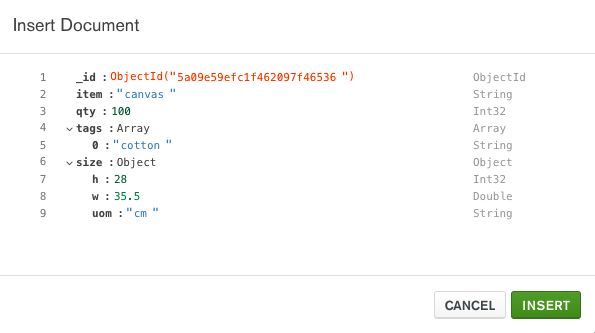
点击insert 就可以插入了
MongoDB Compass _id自动生成字段及其值。生成的 ObjectId由唯一的随机生成的十六进制值组成。
您可以在插入文档之前更改此值,只要它保持唯一且有效ObjectId。
目前campass 不支持一次插入多条数据
-
查询 campass
对象
查询所有
{ }
条件查询
{ status : "D" }
查询 对象下的字段
完整匹配 (包括字段顺序)
{ size : { h : 14 , w : 21 , uom : “cm” } }
部分字段匹配
{ “size.uom” : "in" }
数组
元素包含
{ tags : "red" }
完全匹配数组(包括顺序)
{ tags : [ "red" , "blank"] }
-
更新数据(这个比较简单)
-
mongo 语句操作
还是参考菜鸟的吧 官方文档感觉乱乱的
MongoDB 创建数据库
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
创建了数据库 runoob:(惰性创建,只有插入数据到数据表后才会创建)
use runoob
switched to db runoob
> db
runoob
>
> db.runoob.insert({"name":"菜鸟教程"})
WriteResult({ "nInserted" : 1 })
查看所有数据库
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
>
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
MongoDB 删除数据库 (先use 要删除的数据库)
db.dropDatabase()
> use runoob
db.dropDatabase()
删除集合
db.collection.drop()
删除了 runoob 数据库中的集合 runoob
> use runoob
switched to db runoob
> db.createCollection("runoob") # 先创建集合,类似数据库中的表
> show tables
runoob
> db.runoob.drop()
true
> show tables
>
MongoDB 创建集合
db.createCollection(name, options)
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
test 数据库中创建 runoob 集合
> use test
switched to db test
> db.createCollection("runoob")
{ "ok" : 1 }
>
查看已有集合,可以使用
show collections 或 show tables 命令
当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name" : "菜鸟教程"})
> show collections
mycol2
MongoDB 删除集合
db.collection.drop()
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。 这个在程序中会很有帮助
MongoDB 数据操作(这是基于shell 的原始语句)

参考 mongo 中文文档
1、MongoDB 插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
例子:
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'MongoDB中文网',
url: 'http://www.mongodb.org.cn',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
col 是我们的集合名 ,如果不存在会自动创建,并写入数据
插入文档你也可以使用 db.col.save(document)命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
2、MongoDB 更新文档
MongoDB 使用 update() 和save()方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
update() 方法:
用于更新已存在的文档。语法格式如下:
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern:
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
例子:
插入一条数据
>db.col.insert({
title: 'Mongodb 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Mongodb中文网',
url: 'http://www.mongodb.org.cn',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
更新这条数据
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息
> db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Mongodb中文网",
"url" : "http://www.mongodb.org.cn",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
save() 方法:
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(
,
{
writeConcern:
}
)
参数说明:
document : 文档数据。
writeConcern :可选,抛出异常的级别。
例子
>db.col.save({
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "MongoDB中文网",
"url" : "http://www.mongodb.org.cn",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
}
)
更多实例
只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
全部添加加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
3、MongoDB 删除文档
remove() 方法的基本语法格式如下所示:
db.collection.remove(
,
)
MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(
,
{
justOne: ,
writeConcern:
}
)
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
# 默认删除了两条数据
>db.col.remove({'title':'MongoDB 教程'})
WriteResult({ "nRemoved" : 2 })
>db.col.find() …… # 没有数据
如果你只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
删除所有数据
>db.col.remove({})
4、MongoDB 查询文档

MongoDB 查询数据的语法格式如下:
>db.COLLECTION_NAME.find() # 可以输出所有符合条件的数据
>db.COLLECTION_NAME.findOne() # 可以输出一条符合条件的数据
>db.col.find().pretty()
这个可以格式化 输出数据
例子:
> db.col.find().pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "MongoDB中文网",
"url" : "http://www.mongodb.org.cn",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
条件查询
1.比较运算符
等于
{:} db.col.find({"by":"菜鸟教程"})
小于
{:{$lt:}} db.col.find({"likes":{$lt:50}})
小于或等于
{:{$lte:}} db.col.find({"likes":{$lte:50}})
大于
{:{$gt:}} db.col.find({"likes":{$gt:50}})
大于或等于
{:{$gte:}} db.col.find({"likes":{$gte:50}})
不等于
{:{$ne:}} db.col.find({"likes":{$ne:50}})
总结一下 ,除了 直接等于的直接写值,其他的都是要写一个{$xx:xx}
lt < gt > ne !=
(<>)= 多加 个 e
逻辑查询
AND (实际查询dict 直接写多个key:value 就是and)
>db.col.find({key1:value1, key2:value2})
以上实例中类似于 WHERE 语句:WHERE by='菜鸟教程' AND title='MongoDB 教程'
OR
>db.col.find( { $or: [ {key1: value1}, {key2:value2} ] } )
or 例子:
>db.col.find({$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "mongodb中文网",
"url" : "http://www.mongodb.org.cn",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
总结来说,$or 就是key ,他的value 是一个[ { },{ } ] 里面的对象就是或的条件
and 和 or 的混用
(常规 SQL 语句为: 'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')')
>db.col.find({"likes": {$gt:50}, $or: [{"by": "Mongodb中文网"},{"title":xx}])
MongoDB type 操作符
(这个感觉用的不多,就简单说一下吧)
$type 就是按类型查询
Double : 1
String : 2
Object : 3
Array : 4
Boolean :8
例子:
查询title 字段类型是Array 的值
db.col.find({"title" : {$type : 2}})
MongoDB Limit与Skip方法
limit() 用来控制返回的数量
基本用法:
>db.COLLECTION_NAME.find().limit(NUMBER)
skip 用来跳过的数据量
基本用法
>db.COLLECTION_NAME.find().skip(NUMBER)
skip(2) 表示从第三条数据开始返回
MongoDB 排序
sort()方法
>db.COLLECTION_NAME.find().sort({KEY:1 or -1})
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
5、MongoDB 索引优化
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
mongo 数据索引 ensureIndex()
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
数据库索引优化原理
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
常见的查询算法:
顺序查找、二分叉树、哈希散列(哈希表)、B Tree、B+Tree
哈希表的解释:
其原理是首先根据key值和哈希函数创建一个哈希表(散列表),燃耗根据键值,通过散列函数,定位数据元素位置。
数据结构:哈希表
时间复杂度:几乎是O(1),取决于产生冲突的多少。
mongo 创建索引和没有索引的速度比较
设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
只需要在经常搜索的列、外键、经常排序的列建立索引
对于取值可能性很少的(例如性别 )、图像、大段文字等数据量超大的尽量不要建立索引
ensureIndex() 方法 创建索引
基本用法:
>db.COLLECTION_NAME.ensureIndex({KEY:1})
前台建立索引,可能会阻塞数据表的使用(库级索(可能类似多线程的互斥锁))
可以使用 background 参数,在后台建立索引,这样就不影响使用了
db.values.ensureIndex({open: 1, close: 1}, {background: true})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
6、MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。

aggregate() 方法
基本语法:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
聚合函数:
表达式 描述 实例
$sum 计算总和。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
$avg 计算平均值 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
$min 获取集合中所有文档对应值得最小值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
$max 获取集合中所有文档对应值得最大值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
$push 在结果文档中插入值到一个数组中。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])
$addToSet 在结果文档中插入值到一个数组中,但不创建副本。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
$first 根据资源文档的排序获取第一个文档数据。 db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
$last 根据资源文档的排序获取最后一个文档数据 db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
分组 里面是 [ ] 用 ( 引用数据里面的字段名), 还可以添加以上聚合函数 } very useful
聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
管道操作符实例
后面几个暂时用不到,先简单写一下吧
[图片上传失败...(image-4c843c-1568776783304)]
6、MongoDB 复制(副本集)
这块不是太懂
MongoDB复制是将数据同步在多个服务器的过程。
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
mongod --port "PORT"
--dbpath "YOUR_DB_DATA_PATH"
--replSet "REPLICA_SET_INSTANCE_NAME"
rs.add() 命令基本语法格式如下:
副本集添加成员
>rs.add(HOST_NAME:PORT)
7、MongoDB 分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片
复制所有的写入操作到主节点
延迟的敏感数据会在主节点查询
单个副本集限制在12个节点
当请求量巨大时会出现内存不足。
本地磁盘不足
垂直扩展价格昂贵
8、MongoDB 备份(mongodump)与恢复(mongorerstore)
在Mongodb中我们使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。
mongodump命令可以通过参数指定导出的数据量级转存的服务器。
备份
mongodump命令脚本语法如下:
>mongodump -h dbhost -d dbname -o dbdirectory
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:
需要备份的数据库实例,例如:test
-o:
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
恢复
mongodb使用 mongorerstore 命令来恢复备份的数据。
>mongorestore -h dbhost -d dbname --directoryperdb dbdirectory
-h:
MongoDB所在服务器地址
-d:
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
--directoryperdb:
备份数据所在位置,例如:c:\data\dump\test,这里为什么要多加一个test,而不是备份时候的dump,读者自己查看提示吧!
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
9、MongoDB 监控
在你已经安装部署并允许MongoDB服务后,你必须要了解MongoDB的运行情况,并查看MongoDB的性能。这样在大流量得情况下可以很好的应对并保证MongoDB正常运作。
MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况
D:\set up\mongodb\bin>mongostat
D:\set up\mongodb\bin>mongotop
由于篇幅有限,本篇主要介绍了,mongodb 的本身的知识。关于python 操作 MongoDB 参考我的另一篇文章
Python 操作 mongodb 数据库
这个比较重要,有时间在写