
Principal component analysis (PCA) 是一个统计学方法,用一组较少的不相关的变量代替大量相关变量,同时尽可能保留初始变量的信息,这些推导所得的变量成为主成分。
——《R语言实战》
介绍
主成分分析用来从多变量数据里面提取最重要的信息,一组数据的信息对应着其总方差,所以PCA的目的就是使用一组较少不相关的变量代替大量相关变量,用principal components(下面用主成分来代指)来表示,这些新变量对应原数据的线性结合,新变量的数目少于或等于原变量数目,其中第一主成分对初始变量集的方差解释性最大,随后的每一个主成分都最大化它对方差的解释程度,同时与之前所有的主成分都正交。
注意:原理上理解PCA需要线性代数知识,我只是学习使用R来处理数据(况且我也不懂),所以想要打破砂锅问到底的读者可以查看WIKI: PCA,说的很清楚。
图示理解
二维数据理解
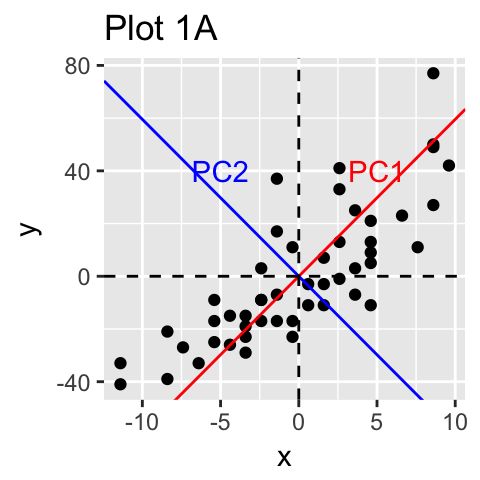
上图Plot A,我们可以看到这是一个简单的X-Y 坐标系展示了一个二维数据,降维的方式在这里被展示为红绿两个主成分,当然PCA是假设对数据总方差解释最大的成分是最重要的,也就是所谓的第一主成分。
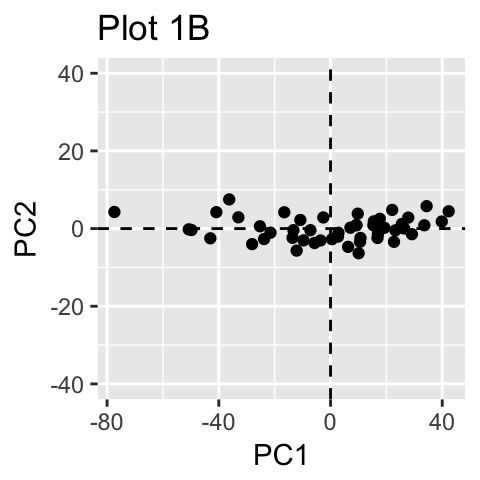
图中PC坐标轴的PC1 就是所谓的第一主成分,解释了示例数据集最大的方差,PC2则是对方差解释性排第二的成分,同时与PC1正交。这里就完成了对目标数据的降维(等于是咱们就需要PC1就可以了,PC2对数据的解释性不是占很大比例)。
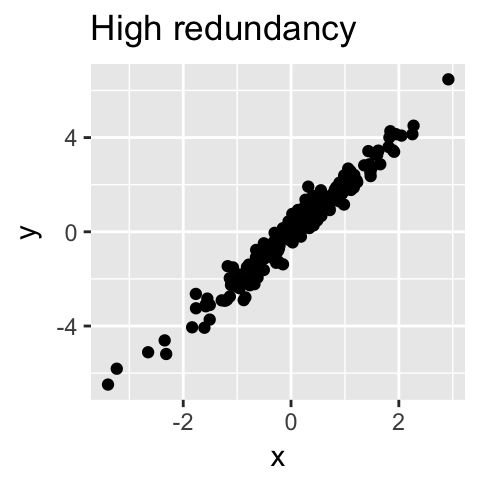
从技术上来讲,每个成分保留的变量比例是通过一个的叫做特征值(Eigenvalue)来计算的。因为很多时候PCA很适合用在拥有多组相关变量的数据里面,因为相关就意味着这些变量的信息有时候是冗余的,同时PCA就可以用很少的不相关的成分来对整个数据进行解释:

综上,PCA的目的是:
- 确定数据里面的隐藏的信息
- 降维的同时去除数据噪音
- 确定相关变量
前期准备
相关的R包:
- prcomp() and princomp() [built-in R stats package]
- PCA() [FactoMineR package]
- dudi.pca() [ade4 package]
- epPCA() [ExPosition package]
- principal())[psych package]
不管你选用哪些包,你都需要做两件事:
- 数据预处理然后提取主成分
- 可视化
本篇文章使用FactoMineR(负责分析)和factoextra(负责可视化),首先是安装和载入包:
> install.packages(c("FactoMineR", "factoextra"))
> library("FactoMineR")
Warning message:
程辑包‘FactoMineR’是用R版本3.5.1 来建造的
> library("factoextra")
Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBa
示例数据理解
这里使用来自factoextra包的decathlon2数据集:
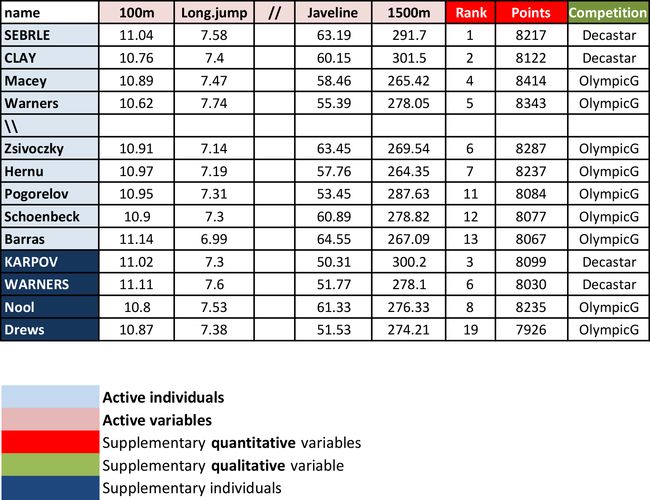
> head(decathlon2)
X100m Long.jump Shot.put High.jump X400m X110m.hurdle Discus Pole.vault Javeline
SEBRLE 11.04 7.58 14.83 2.07 49.81 14.69 43.75 5.02 63.19
CLAY 10.76 7.40 14.26 1.86 49.37 14.05 50.72 4.92 60.15
BERNARD 11.02 7.23 14.25 1.92 48.93 14.99 40.87 5.32 62.77
YURKOV 11.34 7.09 15.19 2.10 50.42 15.31 46.26 4.72 63.44
ZSIVOCZKY 11.13 7.30 13.48 2.01 48.62 14.17 45.67 4.42 55.37
McMULLEN 10.83 7.31 13.76 2.13 49.91 14.38 44.41 4.42 56.37
X1500m Rank Points Competition
SEBRLE 291.7 1 8217 Decastar
CLAY 301.5 2 8122 Decastar
BERNARD 280.1 4 8067 Decastar
YURKOV 276.4 5 8036 Decastar
ZSIVOCZKY 268.0 7 8004 Decastar
McMULLEN 285.1 8 7995 Decastar
这些是用来描述运动员的表现的数据,我们可以看到有27行和13列:
- 淡蓝色(Active individuals)是可用分析样本
- 淡粉色(Active variables)是可用分析变量
- 深蓝色(Supplementary individuals)是测试数据
- 最后三列则是检验变量(说白了就是测试你PCA分析做的准不准的)
提取分析数据集
decathlon2.active <- decathlon2[1:23, 1:10]
数据标准化
在我们接触到的数据里面,变量拥有着不同的测量尺度的(例如单位是千米/千克/厘米等),所以我们需要对数据进行标准化,不然做出来的PCA分析是很不准确的。
最常用的就是Z-score的标准化方法了,适用于大多数数据(原理请自行了解),它将数据转化为拥有方法为1,平均值为0的标准化数据。
R语言的基础函数
sacle()可以完成这件事。而R包
FactoMineR的PCA()函数是自动会帮你的标准化的,当然你也可以选择自己标准化。
PCA分析
res.pca <- PCA(X = decathlon2.active, scale.unit = TRUE, ncp = 5, graph = FALSE)
解释一下PCA()函数的可选参数:
-
X: a data frame. Rows are individuals and columns are numeric variables -
scale.unit: a logical value. If TRUE, the data are scaled to unit variance before the analysis. This standardization to the same scale avoids some variables to become dominant just because of their large measurement units. It makes variable comparable. -
ncp: number of dimensions kept in the final results. -
graph: a logical value. If TRUE a graph is displayed.
我们来看一下最后的分析结果:
> print(res.pca)
**Results for the Principal Component Analysis (PCA)**
The analysis was performed on 23 individuals, described by 10 variables
*The results are available in the following objects:
name description
1 "$eig" "eigenvalues"
2 "$var" "results for the variables"
3 "$var$coord" "coord. for the variables"
4 "$var$cor" "correlations variables - dimensions"
5 "$var$cos2" "cos2 for the variables"
6 "$var$contrib" "contributions of the variables"
7 "$ind" "results for the individuals"
8 "$ind$coord" "coord. for the individuals"
9 "$ind$cos2" "cos2 for the individuals"
10 "$ind$contrib" "contributions of the individuals"
11 "$call" "summary statistics"
12 "$call$centre" "mean of the variables"
13 "$call$ecart.type" "standard error of the variables"
14 "$call$row.w" "weights for the individuals"
15 "$call$col.w" "weights for the variables"
可视化和解读
这里需要用到factoextra包来做这件事,无论你用的是上面哪个包做的PCA分析,都可以简单快捷的对数据进行提取并可视化,参数解释如下:
-
get_eigenvalue(res.pca): Extract the eigenvalues/variances of principal components -
fviz_eig(res.pca): Visualize the eigenvalues -
get_pca_ind(res.pca),get_pca_var(res.pca): Extract the results for individuals and variables, respectively. -
fviz_pca_ind(res.pca),fviz_pca_var(res.pca): Visualize the results individuals and variables, respectively. -
fviz_pca_biplot(res.pca): Make a biplot of individuals and variables.
特征值/方差解释性 Eigenvalues / Variances
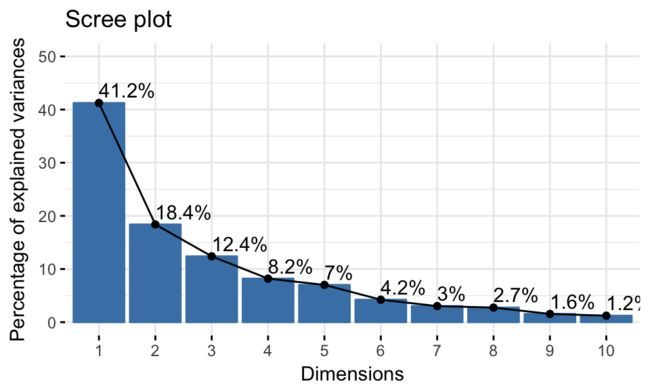
就像上面说的那样,特征值可以衡量各个成分保留的数据方差的多少,从第一主成分开始依次降低,我们通过观察特征值来决定我们需要考虑保留几个成分。
> library("factoextra")
> eig.val <- get_eigenvalue(res.pca)
> eig.val
eigenvalue variance.percent cumulative.variance.percent
Dim.1 4.1242133 41.242133 41.24213
Dim.2 1.8385309 18.385309 59.62744
Dim.3 1.2391403 12.391403 72.01885
Dim.4 0.8194402 8.194402 80.21325
Dim.5 0.7015528 7.015528 87.22878
Dim.6 0.4228828 4.228828 91.45760
Dim.7 0.3025817 3.025817 94.48342
Dim.8 0.2744700 2.744700 97.22812
Dim.9 0.1552169 1.552169 98.78029
Dim.10 0.1219710 1.219710 100.00000
eigenvalue的值cumulative之后是10,对反差的解释程度在第二列,例如此处的第一主成分解释了数据41%的方差,最后一列表明了前几个主成分解释了多少的方差,那我们可以看到一二主成分就解释了大约60%的差异,而在eigenvalue的选择上:
- >1的eigenvalue说明了这个主成分不止解释了一个原始变量。
- 同时你还可以限制解释比例来获取主成分,例如cumulative以后超过70%的。
目前还没有一个统一的标准来定义如何去选去主成分数目,所以这很大程度上依赖于你对数据分析的目的和你对数据的认知程度。
在这个示例数据里面,前三个主成分解释了72%的方差差异性,这就是一个可以接受的比例了。
在R语言实战里面,
psych包可以画一个碎石图,根据碎石检验拿到我们需要保留地数据,也不失为以一个可取的方法。
当然factoextra包也是可以做这个事情的fviz_eig(res.pca, addlabels = TRUE, ylim = c(0, 50)):
对变量作图
factoextra包自带了提取变量的分析结果→get_pca_var
> var <- get_pca_var(res.pca)
> var
Principal Component Analysis Results for variables
===================================================
Name Description
1 "$coord" "Coordinates for the variables"
2 "$cor" "Correlations between variables and dimensions"
3 "$cos2" "Cos2 for the variables"
4 "$contrib" "contributions of the variables"
可以看到相关的描述,其中var.cos2 = var.coord * var.coord,而根据这些数据我们就可以进行作图:
> # Coordinates
> head(var$coord)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
X100m -0.8506257 -0.17939806 0.3015564 0.03357320 -0.1944440
Long.jump 0.7941806 0.28085695 -0.1905465 -0.11538956 0.2331567
Shot.put 0.7339127 0.08540412 0.5175978 0.12846837 -0.2488129
High.jump 0.6100840 -0.46521415 0.3300852 0.14455012 0.4027002
X400m -0.7016034 0.29017826 0.2835329 0.43082552 0.1039085
X110m.hurdle -0.7641252 -0.02474081 0.4488873 -0.01689589 0.2242200
> # Cos2: quality on the factore map
> head(var$cos2)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
X100m 0.7235641 0.0321836641 0.09093628 0.0011271597 0.03780845
Long.jump 0.6307229 0.0788806285 0.03630798 0.0133147506 0.05436203
Shot.put 0.5386279 0.0072938636 0.26790749 0.0165041211 0.06190783
High.jump 0.3722025 0.2164242070 0.10895622 0.0208947375 0.16216747
X400m 0.4922473 0.0842034209 0.08039091 0.1856106269 0.01079698
X110m.hurdle 0.5838873 0.0006121077 0.20149984 0.0002854712 0.05027463
> # Contributions to the principal components
> head(var$contrib)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
X100m 17.544293 1.7505098 7.338659 0.13755240 5.389252
Long.jump 15.293168 4.2904162 2.930094 1.62485936 7.748815
Shot.put 13.060137 0.3967224 21.620432 2.01407269 8.824401
High.jump 9.024811 11.7715838 8.792888 2.54987951 23.115504
X400m 11.935544 4.5799296 6.487636 22.65090599 1.539012
X110m.hurdle 14.157544 0.0332933 16.261261 0.03483735 7.166193
相关曲线作图 Correlation circle
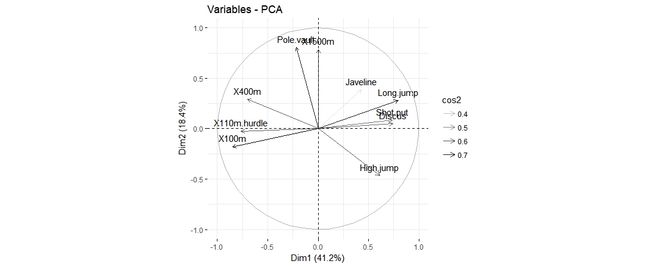
一个变量和一个主成分之间的关系的代表着在PC坐标系里面该变量的坐标,对变量作图我们可以用fviz_pca_var函数:
fviz_pca_var(res.pca, col.var = "black")
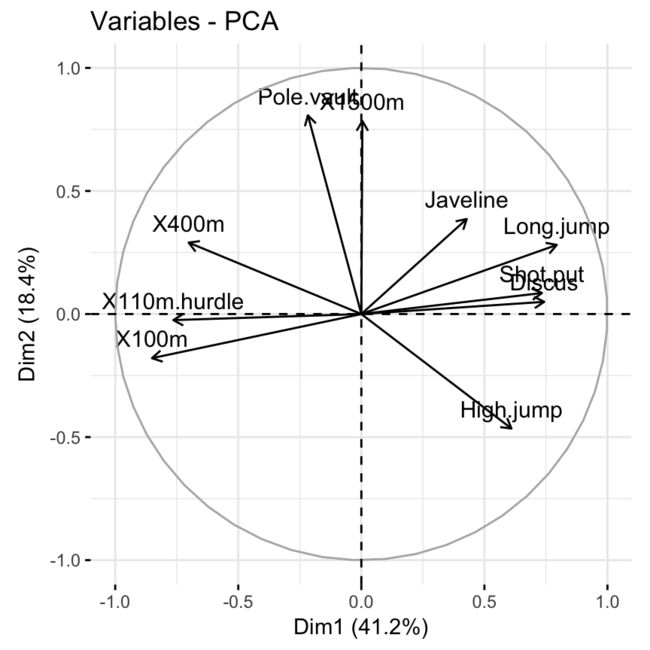
这张图也可以称为变量相关图,它展示了变量组内包括和主成分之间的关系,正相关的变量是彼此靠近的,负相关的变量师南辕北辙的,而从中心点到变量的长度则代表着变量在这个维度所占的比例(也可以理解为质量,quality)。
代表质量作图 Quality of representation
变量在PCA结果里面的质量(quality)称为cos2 (square cosine, squared coordinates) ,可以用corrplot包进行可视化:
library("corrplot")
corrplot(var$cos2, is.corr=FALSE)

或者使用factoextra里面的fviz_cos()函数也可以搞定,只不过没有上图好看而已:
# Total cos2 of variables on Dim.1 and Dim.2
fviz_cos2(res.pca, choice = "var", axes = 1:2)
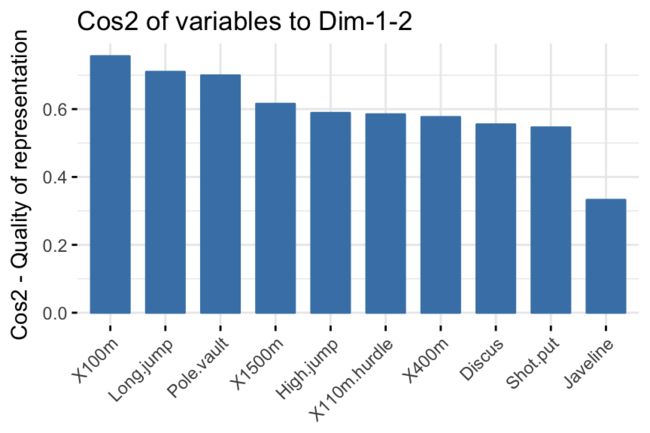
需要注意的是:
- 一个较高的cos2值代表着这个变量对该主成分有较大的贡献值,在这个示例数据里面就表现在相关曲线作图里面的约靠近圆的边缘。
- 一个较低的cos2值代表着这个变量并没有很好的被主成分所代表,在相关曲线作图里面就约靠近圆心。
- cos2值就是为了衡量一个变量的有用程度。
- 越高就代表着这个变量在主成分分析里面约重要。
- 第一张图每一行加在一起等于1。
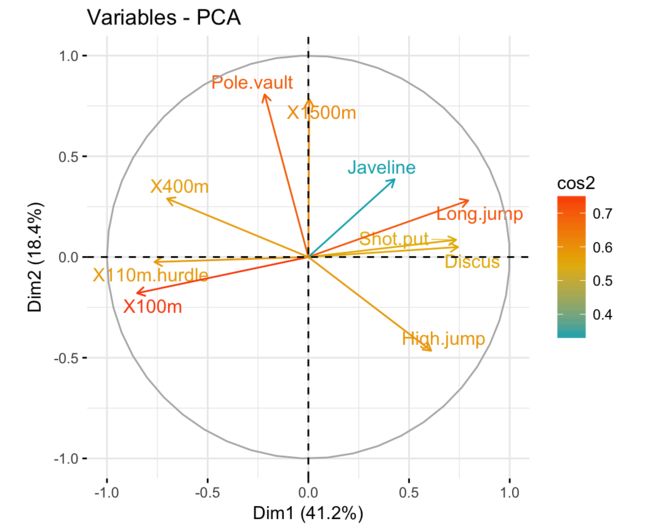
由于该包的作图是基于ggplot2的,所以在作图的时候也可以选择的color = 'cos2'来进行上色:
# Color by cos2 values: quality on the factor map
fviz_pca_var(res.pca, col.var = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Avoid text overlapping
)
当然,我们也可以通过改变变量的透明度来说明其重要性:
# Change the transparency by cos2 values
fviz_pca_var(res.pca, alpha.var = "cos2")
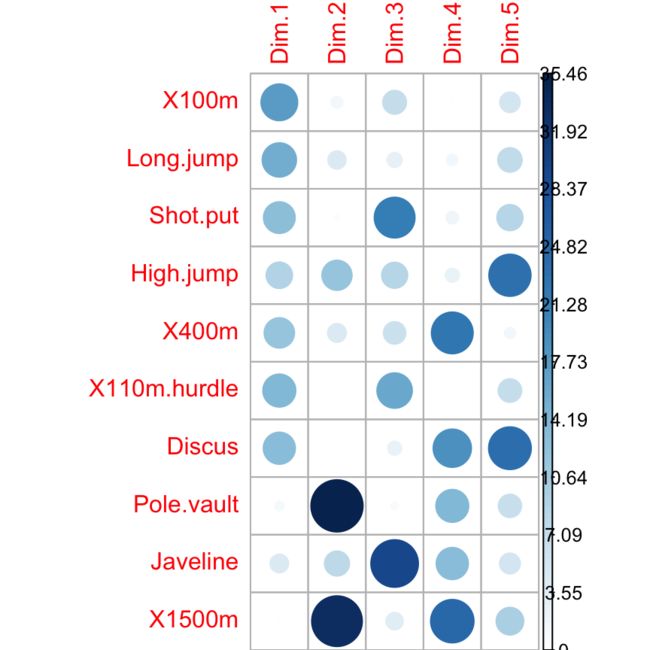
对主成分的贡献作图 Contributions of variables to PCs
每个变量对主成分的贡献比例是不一样的,而对第一二主成分贡献最大的变量是最重要的,而对主成分贡献很低的变量甚至可以移出数据的简化分析,可以通过类似质量作图的模式来进行可视化:
library("corrplot")
corrplot(var$contrib, is.corr=FALSE)
factorextra包里面的fviz_contrib函数也可以用于可视化:
# Contributions of variables to PC1
fviz_contrib(res.pca, choice = "var", axes = 1, top = 10)
# Contributions of variables to PC2
fviz_contrib(res.pca, choice = "var", axes = 2, top = 10)
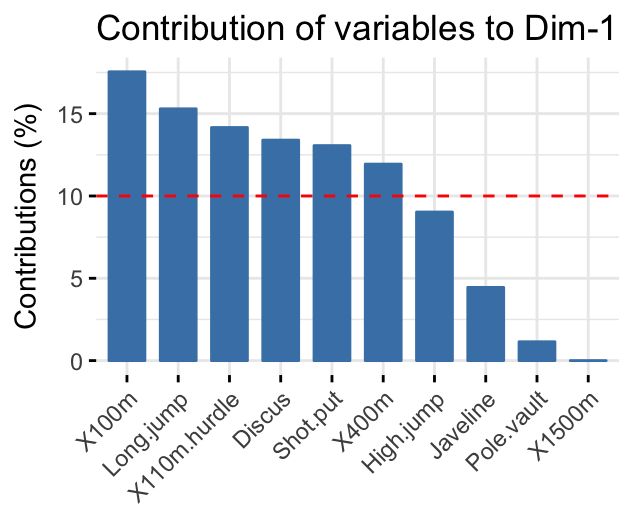
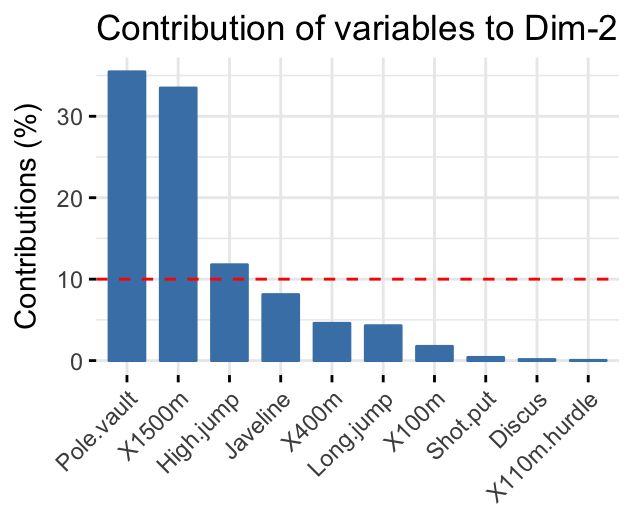
其中axes指示坐标,top指示画前多少个变量,当然也可以画在一张图上:
fviz_contrib(res.pca, choice = "var", axes = 1:2, top = 10)
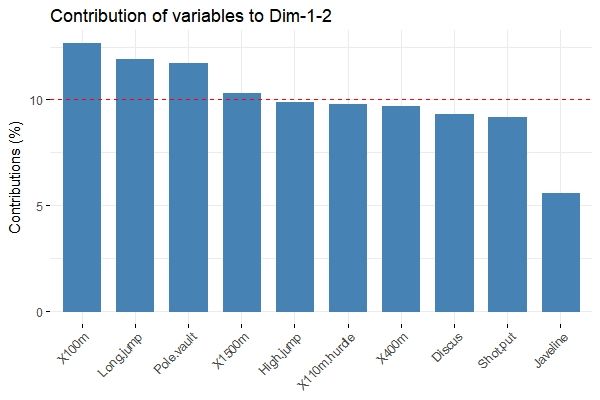
红色虚线代表着平均贡献,高于平均值的可以被认为算是重要变量。
更新截至日期,2018-10-27.
待续。