测试集,训练集和验证集
吴恩达深度学习课程
课程2第一周学习笔记
课程地址:https://mooc.study.163.com/learn/2001281003#/learn/announce
深度学习的应用是一个高度迭代的过程,在这个迭代过程中,创建高质量的数据集(即训练集,测试集和验证集)有助于提高迭代效率。传统的机器学习算法,用到的数据集不是很大,比如有1000条数据,10000条数据,传统的机器学习算法中,将整个数据集按照6:2:2的比例划分为训练集,测试集和验证集,或者按照7:3的比例划分为验证集和测试集。但是在大数据时代,比如百万级别的数据,按照以上划分,显然是不合适的,实际上,百万级别的数据,使用一万条数据进行评估和验证已经足够,验证集和测试集所占的比例会逐渐下降,通常情况下,训练集所占比例约为98%,验证集和测试集所占比例可能会达到1%和1%,或者训练集所占比例达到99.5,验证集和测试集所占比例为0.25%和0.25。
因为要利用验证集和测试集评估不同的模型,所以尽可能使验证集和测试机的数据来自同一分布。为了获取大量的训练数据,可以使训练集和测试集来自不同的分布。遵循这个经验法则,可以使得机器学习的算法的性能更好。
如果要对神经网络做出无偏估计,可以不用测试集。没有测试集,我们要做的就是在训练集上训练,在验证集上评估这些模型。
偏差和方差
构建的模型并不能很好的拟合模型,具有高偏差,我们称这种情况为欠拟合,相反,如果一个模型能够在训练集上很好的拟合数据,而在验证集或者测试集上误差较大,这种情况被称之为高方差,数据过拟合。关于数据集,方差和偏差的关系可以用如下表格表示:
| 训练集误差 | 验证集误差 | 结果分析 |
|---|---|---|
| 1% | 11% | 高方差,过拟合 |
| 15% | 16% | 高偏差,欠拟合 |
| 15% | 30% | 高方差,高偏差 |
| 0.5% | 1% | 低偏差,低方差 |
正则化
深度学习过拟合的消除,通常有两种办法,一种是正则化,另一种是准备更多数据。正则化的消除过拟合的原理如下。
以逻辑回归为例,最小化成本函数,和是逻辑回归的两个参数,是一个多维度矢量参数,是一个实数,在正则化的实现过程中,只关心参数。
正则化损失函数的实现公式如下所示:
公式(2)中的正则化实现方式被称之为正则化,用到了欧几里德法线,被称为向量参数的范数。
正则化是最常用的正则化实现方式,与之对应的正则化的实现方式如下所示,:
是一个正则化参数,通常使用交叉验证集来配置这个参数,一般将这个参数设置为最小值,用来避免过拟合。参数也是我们需要调整的一个超参数。
在神经网络中,带正则项的损失函数,公式如下所示:
在神经网络中,表示的是一个的参数矩阵,该范数被定义为矩阵中所有元素的平方求和,该范数被称之为弗罗贝尼乌斯范数,用下标标注。
利用反向传播函数计算的值并更新权重参数,其损失函数多了一项正则项,则其对参数的求导,也多了正则项,对正则项求导,其结果为,则参数的更新可以用如下表达式所示:
其中表示反向传播给出的值,可以看出,在计算过程中,有:
该公式表示,系数总是小于1,所以表示参数矩阵的值在不断变小,范数正则化也被称之为权重衰减。
正则化能够消除过拟合的原因
由公式(7)可知,当正则化参数设置的足够大时,权重参数参数会接近于0,等价与基本上消除了神经网络中隐藏层的影响,多层神经网络就会变成一个浅层神经网络,整个神经网络的就会呈现出高偏差的状态。即也就是通过调整参数的值,正好能够消除高方差,也能避免高偏差,网络性能达到最好。
假设,神经网络隐藏层的激活函数是函数(),如该函数图像所示,只要足够小,激活函数的取值范围接近于线性状态,如果隐藏层的激活函数都是线性的,那么等价于整个网络的隐藏层都是线性的,一个深层的神经网络就可以等价为浅层的网络,可能会造成高偏差,并且导致欠拟合,不能用来用来实现较为复杂的分类。

dropout 正则化
在深度学习中,除了常用到的正则化之外,常常用到另外一种正则化,称之为dropout 正则化(随机失活正则化)。
假设有一个如下图所示的神经网络,存在过拟合,利用dropout正则化消除过拟合的过程可以简单的描述为;
- 遍历神经网络的每一层节点
- 随机设置需要消除节点和保留节点的概率值
- 根据概率消除一些节点,删掉这些节点的数据(包括权重参数等),得到一个更小的神经网络,利用反向传播算法训练这个更为精简的神经网络。
实施dropout正则化的方法有好多种,最常用到的方法是反向随机失活(inverted dropout),以一个3层的神经网络为例,实现反向随机失活的步骤可以如下所示:
- 定义一个随机向量,表示一个三层的dropout向量
用代码表示如下所示:
d3 = np.random.rand(a3.shape[0],a3.shape[1])
- 判断是否小于
keep_prob,keep_porb是一个具体数字,表示保留某个隐藏层单元的概率。 - 从第三层获取激活函数,计算方式如下所示:
a3 = np.multiply(a3,d3)
以上表达式表示将中等于0的元素输出,各个元素等于0的概率为1-keep_prob,即使得中的0与中相对应的元素归零。
- 最后,继续扩展,即有:
a3 /= keep_prod
注意: 实现以上步骤的原因是:假设第3层的单元数量是50,keep_prob的值为0.8,意味着在这一层删除或者归零的单元数为50×(1-0.8)=10个,对于神经网络第四层有:,在dropout的实现过程中,a^{[3]}中有20%的元素被归零了,为了不影响的期望值,将会弥补或者修正被dropout的20%.
dropout正则化的理解
对于dropout正则化作用的理解有:
不依赖于任何一个特征,因为该单元的输入可能会被随时清除,通过这种方式的传播,dropout会产生收缩权重的平方范数的效果,与正则化的效果类似。
神经网络中每个单元的工作就是输入并生成一系列有意义的输出,通过dropout,该单元的输入可能会被清除,因为某个单元的输入可能会被随时清除,所以,不愿给每个节点的输入加入太多权重,通过这种的方式的传播,dropout产生手摧权重平方范数的效果,压缩权重,并完成一些预防过拟合的外层正则化。
应用dropout正则化的技巧
如下图所示,该网络第二层和第三层隐藏层的单元数目较多,而后面几层单元数目较小,对于这一情况,通常会选择将单元数较多的隐藏层的keep_prob设置较小,单元数较少的隐藏层设置较大。即也就是根据不同层产生不同过拟合的效果来调整keep_prob的值。

其他正则化方法
除了以上两种正则化方法之外,常用来避免网络过拟合的方法还有以下几种:
数据扩增
可以通过扩充数据来避免过拟合,计算机视觉中,扩充数据花费可能太高,可以将原有图像翻转,或者将原图旋转或者随意放大并裁剪。在字符识别中,可以将已有字符随意扭曲或者旋转来扩充训练数据。
early stopping
另一种避免正则化的方法是early stopping术语称之为提前停止训练神经网络。在训练过程中,刚开始迭代时,训练集误差和验证集误差一直在下降,但是随着迭代过程的不断进行,经过某一点之后,验证·集误差可能会开始上升,通常会选择该点的参数作为神经网络的参数。
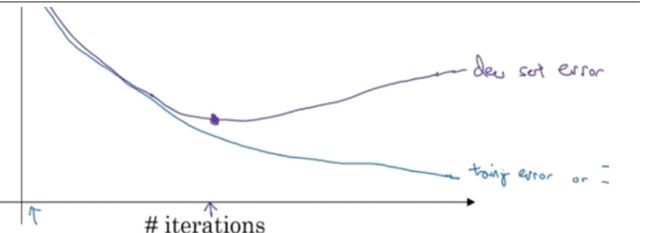
early stopping提前停止了训练,也就意味着提前停止了优化了优化损失函数,损失函数可能不会取得最小值。其优点就是只通过一次梯度下降,就可以得到的较小值,而不用像正则化一样,通过多次尝试超参数的值。
归一化输入
归一化的步骤
神经网络中,能够加速神经网络训练速度的一个有效方法就是归一化输入(标准化),可以分为两个步骤
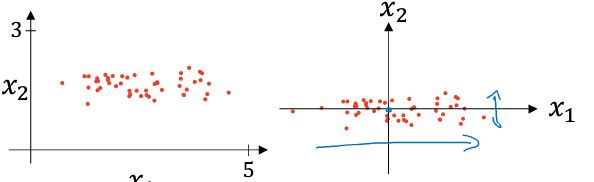
- 零均值
零均值化用数学表达式表示即也就是:
等于每个训练数据减去均值,完成这一步之后,以二维数据为例,训练数据的变化如下图所示:
- 归一化方差
训练数据的方差的计算公式如下所示:
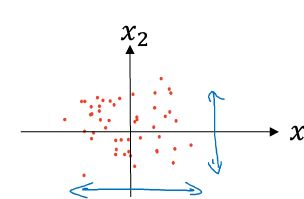
有了以上步骤之后,对于归一化的过程可以直接用如下公式表示:
完成以上步骤之后,整个数据均为的分布在以原点为中心的平面上,如下图所示:
使用归一化的原因
利用归一化能够使得代价函数的分布更加均匀,并且能够训练速度更快。特征范围在比优化起来更加简单快速。

梯度消失与梯度爆炸
假设训练一个深层的神经网络,这个神经网络包含多个隐藏层,每一个隐藏层的神经的权重参数用表示,并且每一层的激活函数都是线性激活函数,则输出可以简化为如下表达式:

假设设定权重参数为
根据公式(10)可知,网络输出会是,随着神经网络层数的增加,其输出会呈现指数级别的增长,这种情况下,梯度下降的过程会变得非常缓慢。
与之相对应的另一种情况是,假定参数矩阵是如下矩阵
这种情况会导致神经网络的输出为,随着神经网络层数的增加,输出会变得越来越小,会导致,梯度下降的过程中,每一步的梯度的下降非常小,梯度下降会花费非常多的时间。这种情况可以称之为梯度消失。
神经网络的权重初始化
对于多层神经网络,其输入,权重参数和特征之间的关系可以用如下公式表示,表示神经元输入特征数量:
对于层神经网络,为了保证输入的值较小,或者保持不变,随着的增加,势必要令变小,一般情况下,最合理的设置方法就是使得。
所以,综上,神经网络某一层权重的初始化过程,可以用如下代码实现:
注意: 表示生成符合高斯分布的随机变量。
参数设置两个技巧:
如果激活函数是, 一般而言选择
如果激活函数是,可以选择
梯度检验
梯度检验能够有效减少神经网络传播过程中的bug,执行梯度检验的过程可以如下步骤所示:
将参数转换成一个向量,此时对于损失函数会变成:
将 转换成向量
众所周知,对于函数而言,点导数的数学定义就是:
是一个极小值。
根据导数或者梯度的数学原理,导数或者梯度表示一种数值逼近,如公式(12)所示,表示双边误差,比单边误差具有更高的精确度。
- 利用循环,计算向量中每个元素 的双边误差,如下公式所示:
- 依次计算,并比较其值是否接近,根据欧几里德范数比较,如公式(14)所示。
比较两者是否接近的公式可以如下所示:
注意:欧几里德范数表示求取两者误差平方之和,再求平方根,公式(14)中的分母能够有效预防这些向量太小或者太大。
一般而言,通过计算得到的,表示算法运行正常。
梯度检验的注意事项
实施梯度检验的过程中,有以下几点注意事项:
不要在训练过程中使用梯度检验,因为梯度检验需要利用反向传播算法计算每一个,会消耗大量的时间和资源。
如果梯度检验失败,要检查所有项,查找不同的值,查明具体是哪一项与的差值较大,从而更加精确的定位bug
实施梯度检验的过程中,不要忘掉正则项,因为正则项也包括了参数和
不要同时使用梯度检验和
dropout,因为dropout可能会随时消除隐藏层单元的一些子集,很难计算损失函数.