TDW(Hive)中发现有些单表的小文件数量达到了恐怖的百万级/天,严重影响了集群的性能,经常导致任务得不到调度,任务运行中被Kill掉,甚至导致集群Server重启。本文主要介绍了小文件过多的危害,小文件产生的原因,以及在实战中如何处理小文件过多的问题。
一.小文件过多的危害
- 小文件增加会导致Namenode节点的内存暴增,严重影响了集群的整体性能。严重情况下会导致集群无法对外服务。
- 小文件的增加增加了文件读写时间,因为客户端需要从NameNode获取元信息,再从DataNode读取对应数据。
- 小文件增加还会增加下游任务的map数量,因为 map数量和源数据的文件个数,文件大小等因素相关
二.小文件过多的原因
我们小文件过多的表主要是入库表和一些中间表,单个中间表每小时产生的小文件达到了20万,一天产生接近500万个小文件。
中间表任务逻辑抽象后主要入下代码所示:
insert table dst_db::dst_table
select key,columnB
from src_db::src_table
where columnC = 'C'-- key 为分区字段
用文件扫描工具后扫描后发现这些表在同一个分区下面都有很多大小为1M的小文件
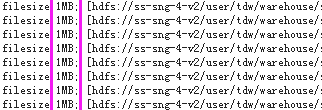
有些分区下面的小文件个数和mapper数量一致,说明每个分区下的小文件个数和map数有关
如果map数量很大,并且分区数也很大的情况下,就会产生大量的小文件,小文件个数 和 Map数 * 分区数正相关,具体原因如下:
Map-only 任务:
小文件数量和 任务的map 数 ,输出表的分区数有关,因为每个map在往目标表中的某个分区输出数据时,都会输出一个单独的文件。如下图所示:
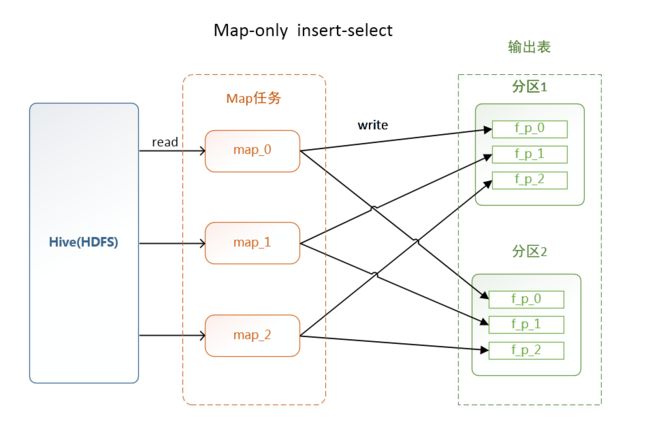
小文件个数 <= Map数 * 分区数,当某些map 没有对应分区字段的数据时,并不会向目标分区输出文件。
Map-Reduce 任务:
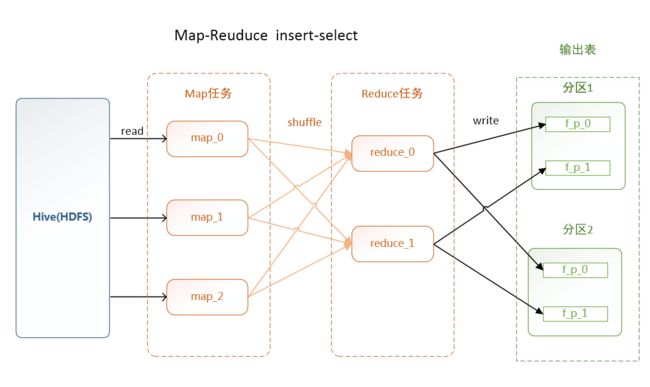
** 小文件个数 <= Reduce数 * 分区数**,当某些reduce 没有对应分区字段的数据时,并不会向目标分区输出文件。
三.如何处理小文件过多?
通过上述小文件产生的原因,可以通过以下方法进行小文件合并:
- 减小目标表分区数
- 减小任务map/reduce 数
- 在任务输出端进行合并
- 使用sort by, distrubute by 合并小文件
1.减小目标表分区数:
分区表通常存在是为了读操作更加快速,而分区数一般由业务字段决定,所以可以根据业务,以及数据分布,特殊处理,合并表小的的分区。
2.减小map/reduce 数
2.1. 减小map数
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
-- 设置hive输入端端进行小文件合并
set mapred.max.split.size=536870912 --512M
-- 每个Map最大输入大小,调大可以减小mapper数,tdw默认 256M
**mapred.max.split.size是最核心的一个参数**:
官方文档参数解释如下:(https://cwiki.apache.org/confluence/display/Hive/AdminManual+Configuration):
For splittable data this changes the portion of the data that each mapper is assigned. By default, each mapper is assigned based on the block sizes of the source files. Entering a value larger than the *block size* will decrease the number of splits which creates fewer mappers. Entering a value smaller than the *block size* will increase the number of splits which creates more mappers
dfs.blocksize = 134217728 (tdw默认是128M)
下面参数也可以相应调大:
set mapred.min.split.size.per.node =536870912
-- 一个节点上split的至少的大小 ,如果小于这个数会进行合并
set mapred.min.split.size.per.rack =536870912
-- 一个交换机下split的至少的大小,如果小于这个参数,则进行合并
set mapreduce.job.split.metainfo.maxsize = 10000000;
-- The maximum permissible size of the split metainfo file. The JobTracker won't attempt to read split metainfo files bigger than the configured value. No limits if set to -1.
网上的一些资料与上面的参数不一致,因为Hadoop v2.x 后,对比Hadoop v1.x参数命名方式发生了变化
mapred.min.split.size => mapreduce.input.fileinputformat.split.minsize。
mapred.max.split.size => mapreduce.input.fileinputformat.split.maxsize。
mapred.min.split.size.per.rack => mapreduce.input.fileinputformat.split.minsize.per.rack。
mapred.min.split.size.per.node => mapreduce.input.fileinputformat.split.minsize.per.node。
dfs.block.size => dfs.blocksize
mapred.map.tasks => mapreduce.job.maps
(https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/DeprecatedProperties.html)
将mapred.max.split.size``扩大4后,小文件由20万降到6万左右,
那能不能再大点?但是参数设置太大,会导致Java Heap Space 出现oom,导致失败
2.2 减小ruduce 数量:
set mapred.reduce.tasks=10;
-- 除非知道数据量的分布,一般不直接设置
set hive.exec.reducers.bytes.per.reducer=1073741824
-- 每个reduce处理的数据量,实际上可能每个reduce 处理的数据量会超过它,默认1G 增加该参数,可以减小reduce数量
3.输出端进行小文件合并:
set hive.merge.mapfiles = true;
-- map-only任务开启合并,默认是true
set hive.merge.mapredfiles = true;
-- map-reduce任务开启合并,默认false
set hive.merge.smallfiles.avgsize=160000000;
-- 如果不是partitioned table的话,输出table文件的平均大小小于这个值,启动merge job,如果是partitioned table,则分别计算每个partition下文件平均大小,只merge平均大小小于这个值的partition。
set hive.merge.size.per.task = 256000000
-- merge job后每个文件的目标大小
理论上设置了输出端小文件合并,会减少小文件的数量,可惜实际中即使设置了这些参数,对tdw分区表并不起作用
4.使用sort by,distrubute by :
使用sort by :
insert table dst_db::dst_table
select key,columnB
from src_db::src_table
where columnC = 'C'
sort by key
sort by 实际上将Map-only 任务变为了Map-reduce 任务,主要由reduce任务数决定,且sort 会对shuffle-read的数据进行排序合并(reducer 内部排序合并) ,使用sort by 小文件降到了1万左右
使用distrubute by :
insert table dst_db::dst_table
select key,columnB
from src_db::src_table
where columnC = 'C'
distribute by key
distribute by key会将同一个key的数据shuffle到同一个reducer(sort by 不会),然后在reducer 内部进行聚合合并,最终写到对应key的分区。最终目标表的小文件从20万降到了1千左右,数量级和分区数数量级一致(小文件数<=分区数)
使用distribute后在数据倾斜的情况,会导致任务运行时间变长(用时间换空间),这时候可以采取数据划分策略 ,将数量特别大的那些key建一个任务执行Map-only insert ,并调整好 map的数量,对于剩下的数据采用 insert...select... distrubute by key 的方法减小小文件。这样能保持整个表的小文件不会太大。
参考:
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
http://blog.csdn.net/dxl342/article/details/77886551
http://blog.csdn.net/lalaguozhe/article/details/9053645
http://blog.csdn.net/yfkiss/article/details/8590486
http://blog.csdn.net/zhong_han_jun/article/details/50814246