-
pandas简介
pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。官网:http://pandas.pydata.org/
参考文档:http://pandas.pydata.org/pandas-docs/stable/ -
pandas数据结构介绍
Series:一种类似于一维数组的对象,它是由一组数据(各种Numpy数据类型)
以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生简单的
Series。DataFrame:一个表格型的数据结构,含有一组有序的列,每列可以是不同的值
类型(数值、字符串、布尔值等),DataFrame既有行索引也有列索引,可以被
看做是由Series组成的字典。 -
Series
- Series类型的创建
- Series切片和索引
- Series应用NumPy数组运算
- Series类型的操作类似Python字典类型
- Series缺失值检测
- Series自动对齐
- Series及其索引的name属性
-
Series类型的创建
• 通过一维数组创建Series
• Python字典,键值对中的“键”是索引,index从字典中进行选择操作
• 标量值,index表达Series类型的尺寸• Python列表,index与列表元素个数一致
• 其他函数,range()函数等1.通过一维数组创建Series
Series对象本质上是由两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values)
In [1]: import numpy as np In [2]: import pandas as pd In [3]: arr=np.array([1,2,3,4]) In [4]: series01=pd.Series(arr) In [5]: series01 Out[5]: 0 1 1 2 2 3 3 4 dtype: int32 #Series的索引 In [6]: series01.index Out[6]: RangeIndex(start=0, stop=4, step=1) #Series的值 In [7]: series01.values Out[7]: array([1, 2, 3, 4]) In [8]: series01.dtype Out[8]: dtype('int32')In [9]: series02=pd.Series([34.5,56.78,45.67]) In [10]: series02 Out[10]: 0 34.50 1 56.78 2 45.67 dtype: float64 In [11]: series02.index=['product1','product2','product3'] In [12]: series02 Out[12]: product1 34.50 product2 56.78 product3 45.67 dtype: float64In [13]: series03=pd.Series([98,56,88,45],index=['语文','数学','英语','体育']) In [14]: series03 Out[14]: 语文 98 数学 56 英语 88 体育 45 dtype: int64 In [15]: series03.index Out[15]: Index(['语文', '数学', '英语', '体育'], dtype='object') In [16]: series03.values Out[16]: array([98, 56, 88, 45], dtype=int64)2.通过字典的方式创建Series
In [20]: a_dict={'20071001':6789.98,'20071002':34556.89,'20071003':3748758.88} In [21]: series04=pd.Series(a_dict) In [22]: series04 Out[22]: 20071001 6789.98 20071002 34556.89 20071003 3748758.88 dtype: float64 In [23]: series04.index Out[23]: Index(['20071001', '20071002', '20071003'], dtype='object')3.标量值,index表达Series类型的尺寸
In [16]: s=pd.Series(25,index=['a','b','c']) In [17]: s Out[17]: a 25 b 25 c 25 dtype: int64 -
Series切片和索引
切片:可以通过自定义索引的列表进行切片;可以通过自动索引进行切片,如果存在自定义索引,则一同被切片。
索引分为自动索引(序号)和自定义索引(index)。
索引:一个的时候直接传入序号或者index,多个的时候传入序号或者index的列表,也可以使用reindex()函数。
In [3]: t=pd.Series(np.arange(10),index=list('ABCDEFGHIJ')) In [4]: t Out[4]: A 0 B 1 C 2 D 3 E 4 F 5 G 6 H 7 I 8 J 9 dtype: int32 In [5]: t[2:8] Out[5]: C 2 D 3 E 4 F 5 G 6 H 7 dtype: int32 #从2到10,步长为2 In [6]: t[2:10:2] Out[6]: C 2 E 4 G 6 I 8 dtype: int32 In [7]: t[[2,3,6]] Out[7]: C 2 D 3 G 6 dtype: int32 In [8]: t[t>7] Out[8]: I 8 J 9 dtype: int32 In [9]: t['F'] Out[9]: 5 In [11]: t[['A','F','g']] # 将来可能报错 d:\python36\lib\site-packages\pandas\core\series.py:851: FutureWarning: Passing list-likes to .loc or [] with any missing label will raise KeyError in the future, you can use .reindex() as an alternative. See the documentation here: https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike return self.loc[key] Out[11]: A 0.0 F 5.0 g NaN dtype: float64 In [12]: t.reindex(['A','F','g']) Out[12]: A 0.0 F 5.0 g NaN dtype: float64 -
Series应用NumPy数组运算
NumPy中运算和操作可用于Series类型。
In [26]: series04 Out[26]: 20071001 6789.98 20071002 34556.89 20071003 3748758.88 In [27]: series04[series04>10000] Out[27]: 20071002 34556.89 20071003 3748758.88 dtype: float64 In [28]: series04/100 Out[28]: 20071001 67.8998 20071002 345.5689 20071003 37487.5888 dtype: float64 In [29]: series01 Out[29]: 0 1 1 2 2 3 3 4 dtype: int32 In [30]: np.exp(series01) Out[30]: 0 2.718282 1 7.389056 2 20.085537 3 54.598150 dtype: float64 -
Series类型的操作类似Python字典类型
• 通过自定义索引访问
• 保留字in操作
• 使用.get()方法In [18]: b=pd.Series([9,8,7,6],index=list('abcd')) In [19]: b['b'] Out[19]: 8 In [20]: 'c' in b Out[20]: True In [23]: b.get('f',100) Out[23]: 100 In [25]: b.get('c',100) Out[25]: 7 -
Series缺失值检测
pandas中的isnull和notnull函数
In [31]: score=pd.Series({'Tom':89,'John':88,'Merry':96,'Max':65}) In [32]: score Out[32]: Tom 89 John 88 Merry 96 Max 65 dtype: int64 In [33]: new_index=['Tom','Max','Joe','John','Merry'] In [34]: scores = pd.Series(score,index=new_index) In [35]: scores Out[35]: Tom 89.0 Max 65.0 Joe NaN John 88.0 Merry 96.0 dtype: float64pandas中的isnull和notnull函数可用于Series缺失值检测。
isnull和notnull都返回一个布尔类型的Series。In [37]: pd.isnull(scores) Out[37]: Tom False Max False Joe True John False Merry False dtype: bool In [38]: pd.notnull(scores) Out[38]: Tom True Max True Joe False John True Merry True dtype: bool In [39]: scores[pd.isnull(scores)] Out[39]: Joe NaN dtype: float64 In [40]: scores[pd.notnull(scores)] Out[40]: Tom 89.0 Max 65.0 John 88.0 Merry 96.0 dtype: float64 -
Series自动对齐
不同Series之间进行算术运算,会自动对齐不同索引的数据。
In [41]: product_num=pd.Series([23,45,67,89],index=['p3','p1','p2','p5']) In [42]: product_num Out[42]: p3 23 p1 45 p2 67 p5 89 dtype: int64 In [43]: product_price_table=pd.Series([9.98,2.34,4.56,5.67,8.78],index=['p1','p2','p3','p4','p5']) In [44]: product_price_table Out[44]: p1 9.98 p2 2.34 p3 4.56 p4 5.67 p5 8.78 dtype: float64 In [45]: product_sum=product_num*product_price_table In [46]: product_sum Out[46]: p1 449.10 p2 156.78 p3 104.88 p4 NaN p5 781.42 dtype: float64 -
Series及其索引的name属性
Series对象本身及其索引都有一个name属性,可赋值设置。
In [47]: product_num.name='ProductNums' In [48]: product_num.index.name='ProductType' In [49]: product_num Out[49]: ProductType p3 23 p1 45 p2 67 p5 89 Name: ProductNums, dtype: int64 -
DataFrame
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
- DataFrame类型的创建
- DataFrame的基本属性和整体情况查询
- DataFrame索引
-
DataFrame类型的创建
• 二维ndarray对象
• 由一维ndarray、列表、字典、元组或Series构成的字典
• Series类型
• 其他的DataFrame类型1.二维ndarray对象
In [26]: d=pd.DataFrame(np.arange(10).reshape(2,5)) In [27]: d Out[27]: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 92.通过列表的方式创建DataFrame
In [50]: df01=pd.DataFrame([['Tom','Merry','John'],[76,98,100]]) In [51]: df01 Out[51]: 0 1 2 0 Tom Merry John 1 76 98 100 In [53]: df02=pd.DataFrame([['Tom',76],['Merry',98],['Merry',100]]) In [54]: df02 Out[54]: 0 1 0 Tom 76 1 Merry 98 2 Merry 100 In [57]: arr=[['Tom',76],['Merry',98],['Merry',100]] In [58]: df03=pd.DataFrame(arr,index=['one','two','three'],columns=['name','score']) In [59]: df03 Out[59]: name score one Tom 76 two Merry 98 three John 1003.通过字典的方式创建DataFrame
In [60]: data={'apart':['1001','1002','1003','1001'],'profits':[567.87,987.87,873,498.87],'year':[2001,2001,2001,2000]} ...: In [61]: df=pd.DataFrame(data) In [62]: df Out[62]: apart profits year 0 1001 567.87 2001 1 1002 987.87 2001 2 1003 873.00 2001 3 1001 498.87 2000 In [63]: df.index Out[63]: RangeIndex(start=0, stop=4, step=1) In [64]: df.columns Out[64]: Index(['apart', 'profits', 'year'], dtype='object') In [65]: df.values Out[65]: array([['1001', 567.87, 2001], ['1002', 987.87, 2001], ['1003', 873.0, 2001], ['1001', 498.87, 2000]], dtype=object) In [66]: df1=pd.DataFrame(data,index=['one','two','three','four']) In [67]: df1 Out[67]: apart profits year one 1001 567.87 2001 two 1002 987.87 2001 three 1003 873.00 2001 four 1001 498.87 2000 In [68]: df1.index Out[68]: Index(['one', 'two', 'three', 'four'], dtype='object') -
DataFrame的基本属性和整体情况查询
 df的基本属性.png
df的基本属性.png
In [14]: df
Out[14]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
In [15]: df.shape
Out[15]: (3, 5)
In [17]: df.dtypes
Out[17]:
a int64
b int64
c int64
d int64
message object
dtype: object
In [18]: df.ndim
Out[18]: 2
In [19]: df.index
Out[19]: RangeIndex(start=0, stop=3, step=1)
In [20]: df.columns
Out[20]: Index(['a', 'b', 'c', 'd', 'message'], dtype='object')
In [21]: df.values
Out[21]:
array([[1, 2, 3, 4, 'hello'],
[5, 6, 7, 8, 'world'],
[9, 10, 11, 12, 'foo']], dtype=object)
In [22]: df.head(2)
Out[22]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
In [23]: df.tail(2)
Out[23]:
a b c d message
1 5 6 7 8 world
2 9 10 11 12 foo
In [24]: df.info()
RangeIndex: 3 entries, 0 to 2
Data columns (total 5 columns):
a 3 non-null int64
b 3 non-null int64
c 3 non-null int64
d 3 non-null int64
message 3 non-null object
dtypes: int64(4), object(1)
memory usage: 200.0+ bytes
In [25]: df.describe()
Out[25]:
a b c d
count 3.0 3.0 3.0 3.0
mean 5.0 6.0 7.0 8.0
std 4.0 4.0 4.0 4.0
min 1.0 2.0 3.0 4.0
25% 3.0 4.0 5.0 6.0
50% 5.0 6.0 7.0 8.0
75% 7.0 8.0 9.0 10.0
max 9.0 10.0 11.0 12.0
-
DataFrame的索引
- df.loc 通过标签索引行数据
- df.iloc 通过位置获取行数据
- 布尔索引
1.df.loc 通过标签索引行数据
In [34]: t=pd.DataFrame(np.arange(12).reshape(3,4),index=['A','B','C'],columns=['W','X','Y','Z']) In [35]: t Out[35]: W X Y Z A 0 1 2 3 B 4 5 6 7 C 8 9 10 11 In [36]: t.loc['A','W'] Out[36]: 0 In [37]: type(t.loc['A','W']) Out[37]: numpy.int32 In [38]: t.loc['A',['W','Z']] Out[38]: W 0 Z 3 Name: A, dtype: int32 In [39]: type( t.loc['A',['W','Z']]) Out[39]: pandas.core.series.Series In [40]: t.loc['B':] #选择连续的多行 Out[40]: W X Y Z B 4 5 6 7 C 8 9 10 11 In [41]: t.loc[:,'X':'Z'] # 注意会选到冒号后的数据 Out[41]: X Y Z A 1 2 3 B 5 6 7 C 9 10 11 In [42]: t.loc[['A','C'],['W','Z']] #选择间隔多行多列 Out[42]: W Z A 0 3 C 8 112.df.iloc 通过位置获取行数据
In [44]: t Out[44]: W X Y Z A 0 1 2 3 B 4 5 6 7 C 8 9 10 11 In [45]: t.iloc[:1,[2,3,]] Out[45]: Y Z A 2 3 In [47]: t.iloc[1:3,1:3] Out[47]: X Y B 5 6 C 9 10赋值更改数据:
In [48]: t Out[48]: W X Y Z A 0 1 2 3 B 4 5 6 7 C 8 9 10 11 In [49]: t.loc['A','Y']=100 In [50]: t Out[50]: W X Y Z A 0 1 100 3 B 4 5 6 7 C 8 9 10 11 In [51]: t.iloc[1:2,0:2]=200 In [52]: t Out[52]: W X Y Z A 0 1 100 3 B 200 200 6 7 C 8 9 10 113.布尔索引
In [60]: t Out[60]: W X Y Z A 0 1 100 3 B 200 200 6 7 C 8 9 10 11 In [61]: t["X"] # 取某一列 Out[61]: A 1 B 200 C 9 Name: X, dtype: int32 In [62]: t[t["X"]>10] Out[62]: W X Y Z B 200 200 6 7假设要从数据中查找名字字符串长度大于3且分数大于98的人
In [73]: df03 Out[73]: name score one Tom 76 two John 98 three Merry 100 In [75]: df03[(df03['name'].str.len()>3)&(df03['score']>98)] Out[75]: name score three Merry 100注意两个问题:
- &表示且;|表示或
- 字符串的方法
 字符串方法.png
字符串方法.png
-
层次化索引
在某个方向上拥有多个(两个及两个以上)索引级别
通过层次化索引,pandas能够以低维度形式处理高维度数据
通过层次化索引,可以按层级统计数据 -
Series层次化索引
In [46]: data=pd.Series([988.44,95859,3949.44,32445.44,234.45],index=[['2001','2001','2001','2002','2002'],['苹果','香蕉','西瓜','苹果','西瓜']]) In [47]: data Out[47]: 2001 苹果 988.44 香蕉 95859.00 西瓜 3949.44 2002 苹果 32445.44 西瓜 234.45 dtype: float64 In [49]: data.index.names=['年份','水果类别'] In [50]: data Out[50]: 年份 水果类别 2001 苹果 988.44 香蕉 95859.00 西瓜 3949.44 2002 苹果 32445.44 西瓜 234.45 dtype: float64 -
DataFrame层次化索引
In [58]: df=pd.DataFrame({'production':[988.44,95859,3949.44,32445.44,234.45],'year':['2001','2001','2001','2002','2002'],'fruit':['苹果','香蕉','西瓜','苹果','西瓜'],'profits':[2334.44,44556,6677,7788,3345]}) In [59]: df Out[59]: production year fruit profits 0 988.44 2001 苹果 2334.44 1 95859.00 2001 香蕉 44556.00 2 3949.44 2001 西瓜 6677.00 3 32445.44 2002 苹果 7788.00 4 234.45 2002 西瓜 3345.00 In [60]: df.set_index(['year','fruit']) Out[60]: production profits year fruit 2001 苹果 988.44 2334.44 香蕉 95859.00 44556.00 西瓜 3949.44 6677.00 2002 苹果 32445.44 7788.00 西瓜 234.45 3345.00 In [61]: new_df=df.set_index(['year','fruit']) -
按层级统计数据
In [62]: new_df Out[62]: production profits year fruit 2001 苹果 988.44 2334.44 香蕉 95859.00 44556.00 西瓜 3949.44 6677.00 2002 苹果 32445.44 7788.00 西瓜 234.45 3345.00 ''' levels:每个等级上轴标签的唯一值 labels:以整数来表示每个level上标签的位置 names:index level的名称 ''' In [63]: new_df.index Out[63]: MultiIndex(levels=[['2001', '2002'], ['苹果', '西瓜', '香蕉']], labels=[[0, 0, 0, 1, 1], [0, 2, 1, 0, 1]], names=['year', 'fruit']) In [64]: new_df.sum(level='year') Out[64]: production profits year 2001 100796.88 53567.44 2002 32679.89 11133.00 In [65]: new_df.sum(level='fruit') Out[65]: production profits fruit 苹果 33433.88 10122.44 香蕉 95859.00 44556.00 西瓜 4183.89 10022.00 -
数据的合并
join:默认情况下是把行索引相同的数据合并到一起。
merge:按照指定的列把数据按照一定的方式合并到一起。
In [67]: t1=pd.DataFrame(np.full((3,4),1),index=list('ABC')) In [69]: t2=pd.DataFrame(np.full((2,5),0),index=list('AB'),columns=list('VWXYZ')) In [70]: t1 Out[70]: 0 1 2 3 A 1 1 1 1 B 1 1 1 1 C 1 1 1 1 In [71]: t2 Out[71]: V W X Y Z A 0 0 0 0 0 B 0 0 0 0 0 In [72]: t1.join(t2) Out[72]: 0 1 2 3 V W X Y Z A 1 1 1 1 0.0 0.0 0.0 0.0 0.0 B 1 1 1 1 0.0 0.0 0.0 0.0 0.0 C 1 1 1 1 NaN NaN NaN NaN NaNIn [90]: df1 = pd.DataFrame({'employee': ['Bob', 'Jake', 'Lisa', 'Sue'],'group': ['Accounting', 'Engineering', 'Engineering','Hr']}) In [91]: df2 = pd.DataFrame({'employee': ['Lisa', 'Bob', 'Jake', 'Sue'], ...: 'hire_date': [2004, 2008, 2012, 2014]}) In [92]: df1 Out[92]: employee group 0 Bob Accounting 1 Jake Engineering 2 Lisa Engineering 3 Sue Hr In [93]: df2 Out[93]: employee hire_date 0 Lisa 2004 1 Bob 2008 2 Jake 2012 3 Sue 2014 #一对一连接 In [94]: df3=pd.merge(df1,df2) In [95]: df3 Out[95]: employee group hire_date 0 Bob Accounting 2008 1 Jake Engineering 2012 2 Lisa Engineering 2004 3 Sue Hr 2014 #多对一连接:指在需要连接的两个列中,有一列的值有重复。 In [98]: df4 = pd.DataFrame({'group': ['Accounting', 'Engineering', 'Hr'],'supervisor': ['Carly', 'Guido', 'Steve']}) In [99]: df4 Out[99]: group supervisor 0 Accounting Carly 1 Engineering Guido 2 Hr Steve In [100]: pd.merge(df3,df4) Out[100]: employee group hire_date supervisor 0 Bob Accounting 2008 Carly 1 Jake Engineering 2012 Guido 2 Lisa Engineering 2004 Guido 3 Sue Hr 2014 Steve #多对多连接 In [104]: df5 = pd.DataFrame({'group': ['Accounting', 'Accounting', 'Engineering', 'Engineering', 'Hr'] , 'skills': ['math', 'spreadsheets', 'coding', 'spreadsheets', 'organization']}) In [105]: df5 Out[105]: group skills 0 Accounting math 1 Accounting spreadsheets 2 Engineering coding 3 Engineering spreadsheets 4 Hr organization In [106]: df1 Out[106]: employee group 0 Bob Accounting 1 Jake Engineering 2 Lisa Engineering 3 Sue Hr In [107]: pd.merge(df1,df5) Out[107]: employee group skills 0 Bob Accounting math 1 Bob Accounting spreadsheets 2 Jake Engineering coding 3 Jake Engineering spreadsheets 4 Lisa Engineering coding 5 Lisa Engineering spreadsheets 6 Sue Hr organization -
分割和组合
一个经典分割 - 应用 - 组合操作示例如图 所示,其中“apply”的是一个求和函数。
- 分割步骤将 DataFrame 按照指定的键分割成若干组。
- 应用步骤对每个组应用函数,通常是累计、转换或过滤函数。
- 组合步骤将每一组的结果合并成一个输出数组。
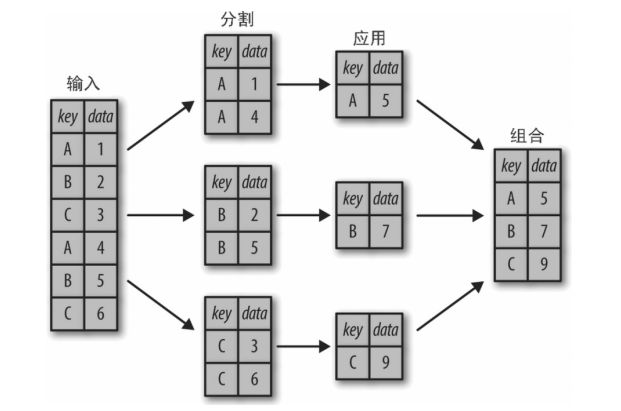 分组聚合.png
分组聚合.png
In [109]: df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],'data': range(6)}, columns=['key', 'data'])
In [110]: df
Out[110]:
key data
0 A 0
1 B 1
2 C 2
3 A 3
4 B 4
5 C 5
In [114]: df.groupby('key')
Out[114]:
In [115]: df.groupby('key').sum()
Out[115]:
data
key
A 3
B 5
C 7
DataFrameGroupBy对象常用的函数:
| 函数名 | 说明 |
|---|---|
| .count() | 统计非nan值的数量 |
| .sum() | 非nan值的和 |
| .mean() | 非nan值的平均数 |
| .median() | 非nan值的中位数 |
| .std()、.var() | 无偏(n-1)标准差和方差 |
| .min() .max() | 非nan值的最小值和最大值 |
-
pandas之读写数据
读取数据的函数
函数名 说明 read_csv() 从文件、url、文件型对象中加载带分隔符的数据,默认为' , '。 read_table() 从文件、url、文件型对象中加载带分隔符的数据,默认为'\t'。 read_excel() 从 Excel 文件读入数据 read_hdf() 使用 HDF5 文件读写数据 read_sql() 从 SQL 数据库的査询结果载入数据 read_pickle() 读入 Pickle 序列化之后的数据 其中read_csv和read_table是常用的,下面就介绍一下read_csv或read_table如何读取数据。
1.read_csv()或read_table()从文本文件读入数据
In [4]: df=pd.read_csv(r'C:\Users\Administrator\Desktop\测量计算\examples\ex1.csv') --------------------------------------------------------------------------- OSError Traceback (most recent call last) '''(报错细节不展示)''' pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source() OSError: Initializing from file failedpandas.read_csv() 报错 OSError: Initializing from file failed,一般由两种情况引起:一种是函数参数为路径而非文件名称,另一种是函数参数带有中文。
对于第一种情况很简单,原因就是没有把文件名称放到路径的后面,把文件名称添加到路径后面就可以了。。
第二种情况,即使路径、文件名都完整,还是报错的原因是这个参数中有中文,发现调用pandas的read_csv()方法时,默认使用 C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。In [5]: df=pd.read_csv(r'C:\Users\Administrator\Desktop\测量计算\examples\ex1.csv',engine='python') In [6]: df Out[6]: a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 fooIn [13]: df=pd.read_table(r'C:\Users\Administrator\Desktop\测量计算\examples\ex1.csv',sep=',',engine='python') In [14]: df Out[14]: a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo2.to_csv()写入数据
In [124]: df Out[124]: a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo In [125]: df.to_csv(r'C:\Users\Administrator\Desktop\测量计算\examples\ex001.csv') -
缺失数据的处理
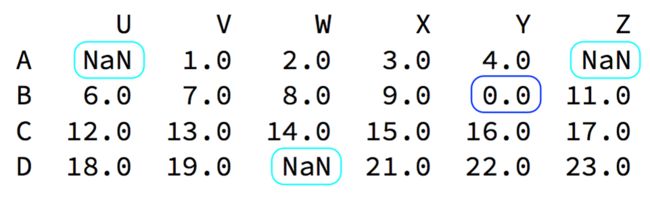 数据缺失.png
数据缺失.png
数据缺失通常有两种情况:
一种就是空,None等,在pandas是NaN(和np.nan一样)。
另一种是我们让其为0,蓝色框中。
| 方法 | 说明 |
|---|---|
| .dropna() | 根据标签的值中是否存在缺失数据对轴标签进行过滤(删除),可通过阈值调节对缺失值的容忍度 |
| .fillna() | 用指定值或插值方法填充缺失数据 |
| .isnull() | 返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值NA |
| .notnull() | isnull的否定式 |
在pandas中数据缺失处理方法:
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
注意:当然并不是每次为0的数据都需要处理;计算平均值等情况,nan是不参与计算的,但是0会。
In [6]: df=pd.DataFrame([['Tom',np.nan,456.67,'M'],['Merty',34,4567.34,np.nan],['John',23,np.nan,'M'],['Joe',18,342.45,
...: 'F']],columns=['name','age','salary','gender'])
In [7]: df
Out[7]:
name age salary gender
0 Tom NaN 456.67 M
1 Merty 34.0 4567.34 NaN
2 John 23.0 NaN M
3 Joe 18.0 342.45 F
In [8]: df.isnull()
Out[8]:
name age salary gender
0 False True False False
1 False False False True
2 False False True False
3 False False False False
In [9]: df.notnull()
Out[9]:
name age salary gender
0 True False True True
1 True True True False
2 True True False True
3 True True True True
In [12]: series=pd.Series([1,2,3,4,np.NaN,5])
In [13]: series.dropna()
Out[13]:
0 1.0
1 2.0
2 3.0
3 4.0
5 5.0
dtype: float64
In [19]: data
Out[19]:
0 1 2
0 0.0 1.0 2.0
1 NaN NaN NaN
2 NaN 7.0 8.0
In [20]: data.dropna() #默认丢失只要含有缺失值的行
Out[20]:
0 1 2
0 0.0 1.0 2.0
In [21]: data.dropna(how='all') #丢失全部为缺失值的行
Out[21]:
0 1 2
0 0.0 1.0 2.0
2 NaN 7.0 8.0
In [23]: data
Out[23]:
0 1 2 4
0 0.0 1.0 2.0 NaN
1 NaN NaN NaN NaN
2 NaN 7.0 8.0 NaN
In [24]: data.dropna(axis=1,how='all') #丢失全部为缺失值的列
Out[24]:
0 1 2
0 0.0 1.0 2.0
1 NaN NaN NaN
2 NaN 7.0 8.0
In [25]: df=pd.DataFrame(np.random.randn(7,3))
In [26]: df.iloc[:4,1]=np.nan
In [27]: df.iloc[:2,2]=np.nan
In [28]: df
Out[28]:
0 1 2
0 -0.299147 NaN NaN
1 0.075411 NaN NaN
2 -0.406294 NaN -1.472581
3 -1.224392 NaN 1.167611
4 -0.730027 -0.459401 0.275466
5 0.919381 0.107443 -2.359248
6 -1.193738 -0.336124 0.992585
In [29]: df.fillna(df.mean()) #取df的平均值填充
Out[29]:
0 1 2
0 -0.299147 -0.229361 -0.279233
1 0.075411 -0.229361 -0.279233
2 -0.406294 -0.229361 -1.472581
3 -1.224392 -0.229361 1.167611
4 -0.730027 -0.459401 0.275466
5 0.919381 0.107443 -2.359248
6 -1.193738 -0.336124 0.992585
In [30]: df
Out[30]:
0 1 2
0 -0.299147 NaN NaN
1 0.075411 NaN NaN
2 -0.406294 NaN -1.472581
3 -1.224392 NaN 1.167611
4 -0.730027 -0.459401 0.275466
5 0.919381 0.107443 -2.359248
6 -1.193738 -0.336124 0.992585
In [31]: df[1].fillna(df[1].median()) #取1一列的中位数填充该列
Out[31]:
0 -0.336124
1 -0.336124
2 -0.336124
3 -0.336124
4 -0.459401
5 0.107443
6 -0.336124
Name: 1, dtype: float64
-
数据特征分析
- 排序
- 基本统计函数
- 累计统计函数
- 相关性分析
1.排序
索引排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序
.sort_index(axis=0, ascending=True)In [27]: b=pd.DataFrame(np.arange(20).reshape(4,5),index=list('cadb')) In [28]: b Out[28]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [29]: b.sort_index() Out[29]: 0 1 2 3 4 a 5 6 7 8 9 b 15 16 17 18 19 c 0 1 2 3 4 d 10 11 12 13 14 In [30]: b.sort_index(ascending=False) Out[30]: 0 1 2 3 4 d 10 11 12 13 14 c 0 1 2 3 4 b 15 16 17 18 19 a 5 6 7 8 9 In [31]: b Out[31]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [33]: c=b.sort_index(axis=1,ascending=False) In [34]: c Out[34]: 4 3 2 1 0 c 4 3 2 1 0 a 9 8 7 6 5 d 14 13 12 11 10 b 19 18 17 16 15 In [35]: c=c.sort_index() In [36]: c Out[36]: 4 3 2 1 0 a 9 8 7 6 5 b 19 18 17 16 15 c 4 3 2 1 0 d 14 13 12 11 10键值排序
.sort_values()方法在指定轴上根据数值进行排序,默认升序
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
by : axis轴上的某个索引或索引列表In [37]: b Out[37]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [38]: c=b.sort_values(2,ascending=False) # 按照索引2的一列中的值进行降序 In [39]: c Out[39]: 0 1 2 3 4 b 15 16 17 18 19 d 10 11 12 13 14 a 5 6 7 8 9 c 0 1 2 3 4 In [40]: c=c.sort_values('a',axis=1,ascending=False) # 按照索引a的一行中的值进行降序 In [41]: c Out[41]: 4 3 2 1 0 b 19 18 17 16 15 d 14 13 12 11 10 a 9 8 7 6 5 c 4 3 2 1 0注意:若按照键值排序中出现NaN,无论升序或者降序排列,统一放到排序末尾。
2.基本统计函数
适用于Series和DataFrame类型
方法 说明 .sum() 计算数据的总和,按0轴计算,下同 .count() 非NaN值的数量 .mean() .median() 计算数据的算术平均值、算术中位数 .var() .std() 计算数据的方差、标准差 .min() .max() 计算数据的最小值、最大值 .prod() .describe() 针对0轴(各列)的统计汇总 适用于Series类型
方法 说明 .argmin() .argmax() 计算数据最大值、最小值所在位置的索引位置(自动索引) .idxmin() .idxmax() 计算数据最大值、最小值所在位置的索引(自定义索引) In [42]: a=pd.Series([9,8,7,6],index=list('abcd')) In [43]: a Out[43]: a 9 b 8 c 7 d 6 dtype: int64 In [44]: a.describe() Out[44]: count 4.000000 mean 7.500000 std 1.290994 min 6.000000 25% 6.750000 50% 7.500000 75% 8.250000 max 9.000000 dtype: float64 In [48]: a.describe()['std'] Out[48]: 1.2909944487358056 In [49]: a.describe()['min'] Out[49]: 6.0In [50]: b Out[50]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [51]: b.describe() Out[51]: 0 1 2 3 4 count 4.000000 4.000000 4.000000 4.000000 4.000000 mean 7.500000 8.500000 9.500000 10.500000 11.500000 std 6.454972 6.454972 6.454972 6.454972 6.454972 min 0.000000 1.000000 2.000000 3.000000 4.000000 25% 3.750000 4.750000 5.750000 6.750000 7.750000 50% 7.500000 8.500000 9.500000 10.500000 11.500000 75% 11.250000 12.250000 13.250000 14.250000 15.250000 max 15.000000 16.000000 17.000000 18.000000 19.000000 In [52]: type(b.describe()) Out[52]: pandas.core.frame.DataFrame In [53]: b.describe().ix['max'] D:\Python36\Scripts\ipython:1: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated Out[53]: 0 15.0 1 16.0 2 17.0 3 18.0 4 19.0 Name: max, dtype: float64 In [54]: b.describe().loc['max'] #取index中的max行 Out[54]: 0 15.0 1 16.0 2 17.0 3 18.0 4 19.0 Name: max, dtype: float64 In [55]: b.describe()[2] #取统计汇总中的2列 Out[55]: count 4.000000 mean 9.500000 std 6.454972 min 2.000000 25% 5.750000 50% 9.500000 75% 13.250000 max 17.000000 Name: 2, dtype: float643.累计统计函数
适用于Series和DataFrame类型,累计计算
方法 说明 .cumsum() 依次给出前1、2、…、n个数的和 .cumprod() 依次给出前1、2、…、n个数的积 .cummax() 依次给出前1、2、…、n个数的最大值 .cummin() 依次给出前1、2、…、n个数的最小值 In [56]: b Out[56]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [57]: b.cumsum() Out[57]: 0 1 2 3 4 c 0 1 2 3 4 a 5 7 9 11 13 d 15 18 21 24 27 b 30 34 38 42 46 In [58]: b.cumprod() Out[58]: 0 1 2 3 4 c 0 1 2 3 4 a 0 6 14 24 36 d 0 66 168 312 504 b 0 1056 2856 5616 9576 In [60]: b.cummin() Out[60]: 0 1 2 3 4 c 0 1 2 3 4 a 0 1 2 3 4 d 0 1 2 3 4 b 0 1 2 3 4 In [61]: b.cummax() Out[61]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19适用于Series和DataFrame类型,滚动计算(窗口计算)
方法 说明 .rolling(w).sum() 依次计算相邻w个元素的和 .rolling(w).mean() 依次计算相邻w个元素的算术平均值 .rolling(w).var() 依次计算相邻w个元素的方差 .rolling(w).std() 依次计算相邻w个元素的标准差 .rolling(w).min() .max() 依次计算相邻w个元素的最小值和最大值 In [62]: b Out[62]: 0 1 2 3 4 c 0 1 2 3 4 a 5 6 7 8 9 d 10 11 12 13 14 b 15 16 17 18 19 In [63]: b.rolling(2).sum() Out[63]: 0 1 2 3 4 c NaN NaN NaN NaN NaN a 5.0 7.0 9.0 11.0 13.0 d 15.0 17.0 19.0 21.0 23.0 b 25.0 27.0 29.0 31.0 33.0 In [64]: b.rolling(3).sum() Out[64]: 0 1 2 3 4 c NaN NaN NaN NaN NaN a NaN NaN NaN NaN NaN d 15.0 18.0 21.0 24.0 27.0 b 30.0 33.0 36.0 39.0 42.04.相关性分析
两个事物,表示为X和Y,如何判断它们之间的存在相关性?
X增大,Y增大,两个变量正相关;X增大,Y减小,两个变量负相关;X增大,Y无视,两个变量不相关。
协方差:
协方差>0, X和Y正相关;协方差<0, X和Y负相关;协方差=0, X和Y独立无关Pearson相关系数:
r取值范围[‐1,1]
0.8‐1.0 极强相关;0.6‐0.8 强相关; 0.4‐0.6 中等程度相关; 0.2‐0.4 弱相关; 0.0‐0.2 极弱相关或无相关。
相关分析函数适用于Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .cov() | 计算协方差矩阵 |
| .corr() | 计算相关系数矩阵, Pearson、Spearman、Kendall等系数 |
In [65]: hprice=pd.Series([3.04,22.93,11.22,22.55,12.33],index=['2010','2011','2012','2013','2014'])
In [66]: m2=pd.Series([8.18,6.93,9.12,7.55,6.63],index=['2010','2011','2012','2013','2014'])
In [67]: hprice.cov(m2)
Out[67]: -3.88571
In [68]: hprice.corr(m2)
Out[68]: -0.46194948337869285
参考资料:
网址:
https://blog.csdn.net/qq_35318838/article/details/80564938
书籍:
《python数据科学手册》
《利用python进行数据分析》
《python科学计算》
视频:
《黑马程序员之数据分析》
《python数据分析与展示》