这是我自己在学习python 3爬虫时的小笔记,做备忘用,难免会有一些错误和疏漏,望指正~~~
Python 3 爬虫学习笔记 (一)
Python 3 爬虫学习笔记 (二)
Python 3 爬虫学习笔记 (三)
Python 3 爬虫学习笔记 (四)
Python 3 爬虫学习笔记 (五)
七 Scrapy小例子
之前我们知道了Scrapy中每个文件所代表的含义,这次我们就以爬取拉勾网Python相关招聘信息来具体演示下Scrapy每个文件的用法。
我们要做的是,将拉勾网以‘Python’为关键字搜索到的招聘信息前五页爬下来,然后将其中的‘职位’、‘薪资’、‘学历要求’、‘工作地点’、‘公司名称’以及‘信息发布时间’提取出来并存储到MySQL数据库中。
(一)准备工作
我们先到拉勾网,在技术一栏中点击Python,得到如下页面:

点击下一页,观察地址栏URL的变化:
第二页的URL
https://www.lagou.com/zhaopin/Python/2/?filterOption=2
我们可以发现,页码的变化体现在URL中的两个数字上,由此,我们便可以得到我们需要爬取的5个页面的URL分别为:
urls = ['https://www.lagou.com/zhaopin/Python/1/?filterOption=1',
'https://www.lagou.com/zhaopin/Python/2/?filterOption=2',
'https://www.lagou.com/zhaopin/Python/3/?filterOption=3',
'https://www.lagou.com/zhaopin/Python/4/?filterOption=4',
'https://www.lagou.com/zhaopin/Python/5/?filterOption=5',
]
整理好需要爬取的URL后,我们来按F12打开开发者工具,找我们需要提取的信息:
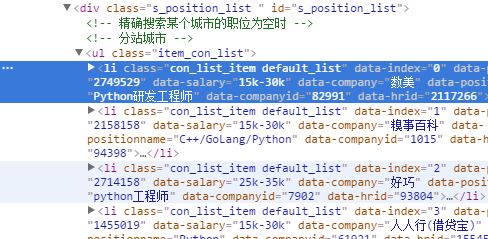
可以看到需要爬取的信息都在
8k-16k
经验1-3年 / 本科
昆明俊云科技有限公司该企业已上传营业执照并通过资质验证审核
移动互联网,硬件 / 初创型(不需要融资)
“福利优厚、期权奖励、五险一金、工作餐”
可以发现,
标签属性中有我们需要的’职位‘、’薪资‘、’公司名称‘,而’工作地点‘、’学历要求‘和’信息发布时间‘则在下面的各个标签中,于是我们可以使用如下代码,提取各个信息(Beautiful Soup):
info = BeautifulSoup(response.body, 'html.parser').find('li','con_list_item default_list')
info.attrs['data-positionname'], # 职位
info.attrs['data-salary']
info.find('em').get_text().split('·')[0], # 工作地点
(info.find('span', 'format-time')).string, # 发布时间
info.find('div', 'li_b_l').get_text().split('/')[-1], # 学历要求
info.attrs['data-company'], # 公司名称
(二)数据库的创建
先来建好数据库,这里使用的是MySQL数据库,建立如下:
DROP TABLE IF EXISTS `info01`;
CREATE TABLE `info01` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`salary` int(255) NOT NULL,
`position` varchar(255) NOT NULL,
`time` varchar(255) NOT NULL,
`grade` varchar(255) NOT NULL,
`company` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=498 DEFAULT CHARSET=utf8;
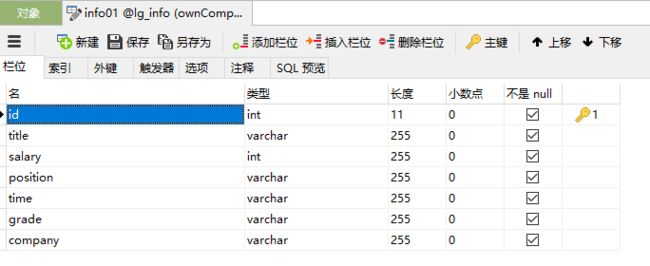
也可以使用像Navicat for MySQL之类的图形化工具,如下:
 Paste_Image.png
Paste_Image.png
要注意的是,其中的id属性设为自增,’salary‘属性设为int类型,方便以后进行数据分析统计。
(三)代码编写
准备工作完成了,下面开始代码部分,先到工作目录中建立工程,在命令行中:
scrapy startproject lgSpider
先编辑items.py文件,该文件是一个简单的数据收集容器,用于保存爬虫爬取的数据,类似一个字典:
# items.py
# -*- coding: utf-8 -*-
import scrapy
class LgspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 职位
position = scrapy.Field() # 工作地点
salary = scrapy.Field() # 最低薪资
company = scrapy.Field() # 公司名称
time = scrapy.Field() # 信息发布时间
grade = scrapy.Field() # 学历要求
在spiders中建立爬虫文件lg_spider.py如下:
# -*- coding:utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
class lg_spider(scrapy.Spider):
name = 'lg' # 爬虫名字
def start_requests(self):
# 待爬取的url地址
urls = ['https://www.lagou.com/zhaopin/Python/1/?filterOption=1',
'https://www.lagou.com/zhaopin/Python/2/?filterOption=2',
'https://www.lagou.com/zhaopin/Python/3/?filterOption=3',
'https://www.lagou.com/zhaopin/Python/4/?filterOption=4',
'https://www.lagou.com/zhaopin/Python/5/?filterOption=5',
]
# 模拟浏览器的头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
for url in urls:
yield scrapy.Request(url=url, headers=headers, callback=self.parse)
def parse(self, response):
# 使用Beautiful Soup进行分析提取
soup = BeautifulSoup(response.body, 'html.parser')
for info in soup.find_all('li', 'con_list_item default_list'):
# 将提取的salary字符串,只截取最少工资并转换成整数形式,如:7k-12k -> 7000
salary = info.attrs['data-salary'].split('k')[0]
salary = int(salary) * 1000
# 存储爬取的信息
yield {
'title': info.attrs['data-positionname'], # 职位
'position': info.find('em').get_text().split('·')[0], # 工作地点
'salary': salary, # 最低工资
'time': (info.find('span', 'format-time')).string, # 发布时间
'grade': info.find('div', 'li_b_l').get_text().split('/')[-1], # 学历要求
'company': info.attrs['data-company'], # 公司名称
}
爬取的item被收集起来后,会被传送到pipelines中,进行一些处理,下面开始编辑pipelines.py用于将爬取的数据存入MySQL数据库,
# -*- coding: utf-8 -*-
import pymysql
# 数据库配置信息
db_config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '',
'db': 'lg_info',
'charset': 'utf8'
}
class LgspiderPipeline(object):
# 获取数据库连接和游标
def __init__(self):
self.connection = connection = pymysql.connect(**db_config)
self.cursor = self.connection.cursor()
# Pipeline必须实现的方法,对收集好的item进行一系列处理
def process_item(self, item, spider):
# 存储的SQL语句
sql = 'insert into info01(title, salary, position, time, grade, company) values(%s, %s, %s, %s, %s, %s)'
try:
self.cursor.execute(sql, (item['title'].encode('utf-8'),
item['salary'],
item['position'].encode('utf-8'),
item['time'].encode('utf-8'),
item['grade'].encode('utf-8'),
item['company'].encode('utf-8'),
)
)
self.connection.commit()
except pymysql.Error as e:
# 若存在异常则抛出
print(e.args)
return item
最后,再来配置settings.py文件,打开settings.py文件,会发现其中有很多注释,我们找到
# Configure item pipelines
它代表使用使用指定的pipeline,将其修改为如下格式:
# LgspiderPipeline即我们写的pipelines.py中的LgspiderPipeline类
ITEM_PIPELINES = {
'lgSpider.pipelines.LgspiderPipeline': 300,
}
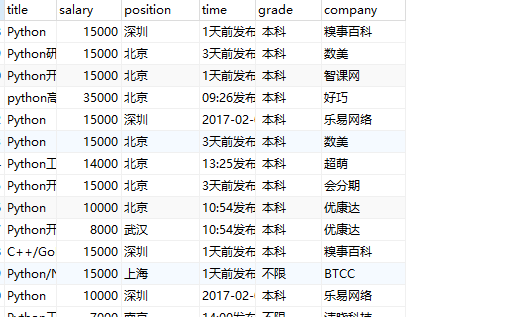
OK。所有工作都完成了,我们来执行一下爬虫看一下效果;
scrapy crawl lg
刷新一下数据库:
 Paste_Image.png
Paste_Image.png
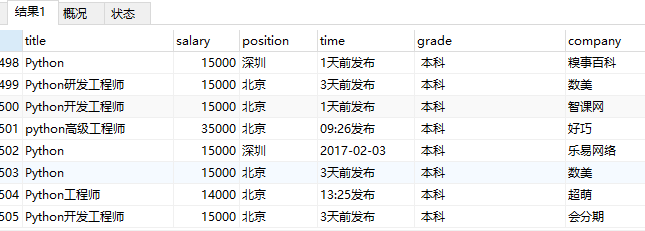
现在我们就可以通过sql语言,进行简单的数据统计,如找出所有最低工资高于10000的招聘信息:
select * FROM info01 WHERE salary>10000
 Paste_Image.png
Paste_Image.png
当然这样看起来比较麻烦,pyhon也有可以将数据图形化的第三方包,我们以后再看。