1. 对象类型与编码
Redis的对象由redisObject结构表示:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
type属性表示对象的类型:
/* The actual Redis Object */
#define OBJ_STRING 0 // 字符串对象
#define OBJ_LIST 1 // 列表对象
#define OBJ_SET 2 // 集合对象
#define OBJ_ZSET 3 // 有序集合对象
#define OBJ_HASH 4 // 哈希对象
encoding属性表示对象的编码, 即使用什么数据结构作为对象的底层实现:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
2. 数据结构
2.1 简单动态字符串(SDS,Simple Dynamic String)
SDS是Redis默认的字符串表示。代码位于sds.h和sds.c中。
2.1.1 SDS的定义
// 指向实际字符串的指针
typedef char *sds;
// 持有sds的结构
struct __attribute__ ((__packed__)) sdshdr64 {
// 字符串已用的字节数
uint64_t len;
// 字符串可用的字节数
uint64_t alloc;
// 低3位表示使用的sdshdr的类型,即sdshdr5~sdshdr64;高5位不使用
unsigned char flags;
// 指向实际的字符串
char buf[];
};
注:在redis4.0.1的代码中,根据字符串的长度,定义了多个sdshdr结构,包括sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64。在文中简化为以sdshdr64来分析讲解。
2.1.2 SDS的创建
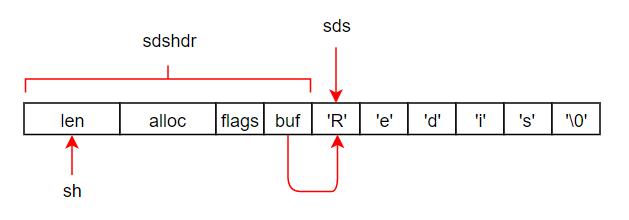
SDS示例
代码分析如下:
// 使用字符串init的前initlen字节创建sds
sds sdsnewlen(const void *init, size_t initlen) {
// 指向申请的内存,后被转化为sdshdr指针类型
void *sh;
// 指向申请的内存中实际的字符串
sds s;
// 根据字符串的长度判断使用的sdshdr类型(sdshdr5~sdshdr64)
char type = sdsReqType(initlen);
// 相应sdshdr结构的长度
int hdrlen = sdsHdrSize(type);
// 指向sdshdr结构的flags字段
unsigned char *fp;
// sdshdr结构、字符串作为整体申请内存
// 多出的1字节将设置为字符串结束字符'\0',遵循C字符串惯例
sh = s_malloc(hdrlen+initlen+1);
if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
// 内存开始位置偏移sdshdr结构长度,即为字符串起始位置
s = (char*)sh+hdrlen;
// 字符串紧跟sdshdr结构,从字符串起始位置回退1字节
// 越过sdshdr的buf字段,指向flag字段
fp = ((unsigned char*)s)-1;
switch(type) {
...
case SDS_TYPE_64: {
// 将sh转变为sdshdr指针类型,指向新创建的sdshdr结构
SDS_HDR_VAR(64, s);
// len字段:实际字符串的字节数,不包括结束字符
sh->len = initlen;
// alloc字段:字符串可用空间字节数,不包括sdshdr结构及结束字符
sh->alloc = initlen;
// 将sdshdr.flags设置sdshdr类型
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // 复制字符串
s[initlen] = '\0'; // 给字符串添加结束字符'\0'
return s;
}
// s为新分配内存中字符串的起始位置,回退sdshdr结构长度,指向新分配内存起始位置,
// 也即新创建的sdshdr结构的起始位置
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
2.1.3 SDS的增长
向SDS追加字符时可能会导致扩容。
// 向原SDS,追加字符串t的前len个字节
sds sdscatlen(sds s, const void *t, size_t len) {
// sdslen:返回sdshdr.len值
size_t curlen = sdslen(s);
// 扩容处理
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
// 追加字符
memcpy(s+curlen, t, len);
// 设置sdshdr.len值
sdssetlen(s, curlen+len);
// 设置结束字符
s[curlen+len] = '\0';
// 由于可能有扩容带来的内存重分配,因此要返回新的SDS地址
return s;
}
// 为SDS扩容,addlen为增加的字节数
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
// sdsavail:返回sdshdr.alloc - sdshdr.len值
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 如果剩余空间足够,则直接返回
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
// 增长后字符串的新长度
newlen = (len+addlen);
// SDS_MAX_PREALLOC,预分配空间,1MB
// 如果新长度小于1MB,则在新长度之上预分配同样大小空间
// 如果新长度大于1MB,则在新长度之上预分配1MB
// 预分配机制,避免了SDS增长时频繁扩容
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// 根据新长度判断使用的sdshdr类型
type = sdsReqType(newlen);
// 新sdshdr类型的长度
hdrlen = sdsHdrSize(type);
// 如果类型不变,则扩张原有内存区域
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
// 若类型改变,sdshdr大小变化,则重新申请新内存区域
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
// 复制原字符串内容
memcpy((char*)newsh+hdrlen, s, len+1);
// 释放原内存区域
s_free(sh);
s = (char*)newsh+hdrlen;
// 设置sdshdr结构的flags值和len值
s[-1] = type;
sdssetlen(s, len);
}
// 设置sdshdr结构的alloc值
sdssetalloc(s, newlen);
// 返回新SDS的字符串起始位置
return s;
}
扩容的基本工作还是重新申请内存以及复制内容,不同的是其扩容策略:
- 如果新长度小于1MB,则在新长度之上预分配同样大小空间
- 如果新长度大于1MB,则在新长度之上预分配1MB
2.1.4 SDS的缩短
SDS缩短时,并不会进行内存重分配,而是作为空闲空间以备下次增长之用。
void sdsclear(sds s) {
sdssetlen(s, 0); // 设置sdshdr.len值
s[0] = '\0'; // 字符串开始位置设置结束字符
}
// 将sds截断为指定区域,包含end
void sdsrange(sds s, int start, int end) {
size_t newlen, len = sdslen(s);
if (len == 0) return;
if (start < 0) { // 支持下标为负,从后往前推移位置
start = len+start;
if (start < 0) start = 0; // 越界安全
}
if (end < 0) {
end = len+end;
if (end < 0) end = 0; // 越界安全
}
newlen = (start > end) ? 0 : (end-start)+1;
if (newlen != 0) {
if (start >= (signed)len) {
newlen = 0;
} else if (end >= (signed)len) {
end = len-1;
newlen = (start > end) ? 0 : (end-start)+1;
}
} else {
start = 0;
}
// 截断内容迁移至开始位置
if (start && newlen) memmove(s, s+start, newlen);
s[newlen] = 0; // 设置结束字符
sdssetlen(s,newlen); // 设置sdshdr.len
}
2.1.5 SDS保存整数
保存的是整数的十进制字符串形式。
// 为整数创建SDS
sds sdsfromlonglong(long long value) {
char buf[SDS_LLSTR_SIZE];
// 整数转化为十进制字符串
int len = sdsll2str(buf,value);
// 为十进制字符串创建SDS
return sdsnewlen(buf,len);
}
// 8字节整数的十进制,最多有20位,还有一位保存'\0'
#define SDS_LLSTR_SIZE 21
// 整数转化为十进制字符串
int sdsll2str(char *s, long long value) {
char *p, aux;
unsigned long long v;
size_t l;
// 按十进制,从低位到高位依次保存
v = (value < 0) ? -value : value;
p = s;
do {
*p++ = '0'+(v%10);
v /= 10;
} while(v);
if (value < 0) *p++ = '-';
l = p-s;
*p = '\0'; // 添加结束字符
// 将结束字符前的十进制字符串倒置
p--;
while(s < p) {
aux = *s;
*s = *p;
*p = aux;
s++;
p--;
}
return l; // 返回字符串长度,不包括结束字符
}
2.1.6 二进制的SDS
虽然SDS名为字符串,但实际是作为字节来处理的,因此还可用来保存二进制数据。
2.2. 链表
Redis的链表是一个典型的双向链接的实现。代码位于adlist.h和adlist.c中。
2.2.1 链表的定义
// 链表节点
typedef struct listNode {
// 指向前驱节点
struct listNode *prev;
// 指向后继节点
struct listNode *next;
// 指向节点值
void *value;
} listNode;
// 链表
typedef struct list {
// 指向头节点
listNode *head;
// 指向尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值匹配函数
int (*match)(void *ptr, void *key);
// 节点数量
unsigned long len;
} list;
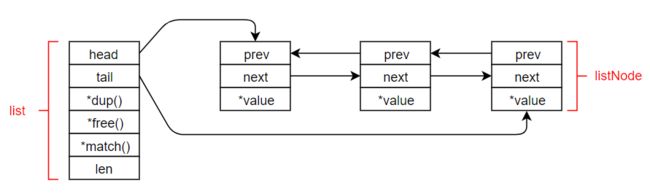
链表示例
2.2.2 链表的创建
// 创建一个链表,无节点,无函数
list *listCreate(void)
{
struct list *list;
// 为链表申请内存
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
2.2.3 链表的清空
// 清空所有节点
void listEmpty(list *list)
{
unsigned long len;
listNode *current, *next;
current = list->head;
len = list->len;
while(len--) {
next = current->next;
// 调用free函数(若存在)释放节点的值
if (list->free) list->free(current->value);
// 释放节点
zfree(current);
// 取下一个节点
current = next;
}
list->head = list->tail = NULL;
list->len = 0;
}
2.2.4 链接的删除
void listRelease(list *list)
{
// 先清空所有节点
listEmpty(list);
// 再释放链表
zfree(list);
}
2.2.5 节点的插入
// 从头部插入节点
list *listAddNodeHead(list *list, void *value)
{
listNode *node;
// 为节点申请内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) { // 空链表情况
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { // 插入头部
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++; // 计数
return list;
}
// 从尾部插入节点
list *listAddNodeTail(list *list, void *value)
{
listNode *node;
// 为节点申请内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) { // 空链表情况
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { // 插入尾部
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++; // 计数
return list;
}
// 插入指定节点的前面/后面
list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
// 为节点申请内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (after) {
node->prev = old_node;
node->next = old_node->next;
if (list->tail == old_node) {
list->tail = node;
}
} else {
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) {
list->head = node;
}
}
if (node->prev != NULL) {
node->prev->next = node;
}
if (node->next != NULL) {
node->next->prev = node;
}
list->len++;
return list;
}
2.2.6 节点的删除
// 删除指定节点
void listDelNode(list *list, listNode *node)
{
if (node->prev)
node->prev->next = node->next;
else
list->head = node->next;
if (node->next)
node->next->prev = node->prev;
else
list->tail = node->prev;
// 调用链表的free函数(若存在)释放节点的值
if (list->free) list->free(node->value);
// 释放节点内存
zfree(node);
list->len--;
}
2.2.7 迭代器
- 迭代器的定义
// 链表迭代器
typedef struct listIter {
// 取下一个节点
listNode *next;
// 方向
int direction;
} listIter;
- 生成迭代器
listIter *listGetIterator(list *list, int direction)
{
listIter *iter;
// 为迭代器申请内存
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL;
// 若从前向后,则迭代器next指向头节点,否则指向尾节点;
if (direction == AL_START_HEAD)
iter->next = list->head;
else
iter->next = list->tail;
iter->direction = direction;
return iter;
}
- 迭代
listNode *listNext(listIter *iter)
{
// 返回next指向的节点
listNode *current = iter->next;
if (current != NULL) { // 根据方向设置下一个节点
if (iter->direction == AL_START_HEAD)
iter->next = current->next;
else
iter->next = current->prev;
}
return current;
}
2.2.8 搜索
- 根据值搜索节点
listNode *listSearchKey(list *list, void *key)
{
listIter iter;
listNode *node;
// 迭代器归位到头部
listRewind(list, &iter);
// 迭代遍历
while((node = listNext(&iter)) != NULL) {
// 若有匹配函数,则调用匹配函数比较值
// 否则比对是否是同一个对象(地址是否相同)
if (list->match) {
if (list->match(node->value, key)) {
return node;
}
} else {
if (key == node->value) {
return node;
}
}
}
return NULL;
}
- 根据下标搜索节点
listNode *listIndex(list *list, long index) {
listNode *n;
// 若下标为负,则后向遍历,否则前向遍历
if (index < 0) {
index = (-index)-1;
n = list->tail;
while(index-- && n) n = n->prev;
} else {
n = list->head;
while(index-- && n) n = n->next;
}
return n;
}
2.2.9 链表的多态
是一个典型的双向链接及迭代器实现。只是对于值的类型及处理,实现了多态,可为不同的链表实例设置不同的值类型和处理函数。
2.3 字典(Dict)
字典是Redis的重要数据结构,Redis的数据库就是使用字典作为底层实现的。代码位于dict.h和dict.c中。
2.3.1 字典的定义
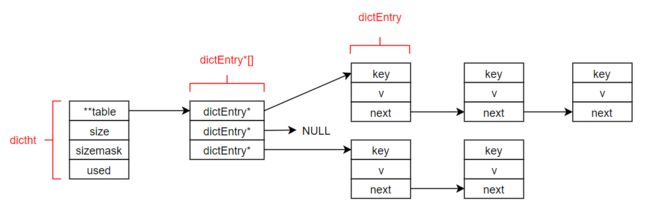
- 字典实现所用的哈希表
typedef struct dictht {
// 哈希表节点数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 大小掩码,只是等于size-1
unsigned long sizemask;
// 哈希表已有节点数量
unsigned long used;
} dictht;
- 哈希表节点
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下一个节点
struct dictEntry *next;
} dictEntry;
- 哈希表示例图如下
哈希表示例
- 字典
typedef struct dict {
// 指向字典类型结构
dictType *type;
// 私有数据
void *privdata;
// 2个哈希表
dictht ht[2];
// rehash索引,rehash未进行时其值为-1
long rehashidx;
// 当前的迭代器数量
unsigned long iterators;
} dict;
// 字典类型,保存一组操作特定类型键值对的函数
// Redis为不同的字典设置不同的类型特定函数
typedef struct dictType {
// 计算哈希值
uint64_t (*hashFunction)(const void *key);
// 复制键
void *(*keyDup)(void *privdata, const void *key);
// 复制值
void *(*valDup)(void *privdata, const void *obj);
// 比较键
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键
void (*keyDestructor)(void *privdata, void *key);
// 销毁值
void (*valDestructor)(void *privdata, void *obj);
} dictType;
为了实现渐增式rehash,字典使用了两个哈希表,ht[0]和ht[1]。一般情况下,只使用ht[0]。rehash时,会逐个将ht[0]的元素移到ht[1],直到ht[0]清空为止。
2.3.2 字典创建
// 传入字典类型和私有数据,创建字典
dict *dictCreate(dictType *type, void *privDataPtr)
{
// 申请内存
dict *d = zmalloc(sizeof(*d));
// 初始化
_dictInit(d,type,privDataPtr);
return d;
}
// 初始化字典
int _dictInit(dict *d, dictType *type, void *privDataPtr)
{
// 初始化哈希表
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
// 初始化字典属性
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
// 重置哈希表:全部置空
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
2.3.3 添加元素
- 计算键的哈希值
// 调用字典类型的hashFunction函数计算键的哈希值
#define dictHashKey(d, key) (d)->type->hashFunction(key)
- 设置键
// 若字典类型的keyDup函数存在,则使用函数计算后赋值,否则直接赋值
#define dictSetKey(d, entry, _key_) do { \
if ((d)->type->keyDup) \
(entry)->key = (d)->type->keyDup((d)->privdata, _key_); \
else \
(entry)->key = (_key_); \
} while(0)
- 设置值
// 若字典类型的valDup函数存在,则使用函数计算后赋值,否则直接赋值
#define dictSetVal(d, entry, _val_) do { \
if ((d)->type->valDup) \
(entry)->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
(entry)->v.val = (_val_); \
} while(0)
- 判断是否处于rehash中
#define dictIsRehashing(d) ((d)->rehashidx != -1)
- 向字典添加键值对
int dictAdd(dict *d, void *key, void *val)
{
// 构造哈希表节点
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
// 设置节点的值
dictSetVal(d, entry, val);
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算键的哈希值, 查找是否存在,若存在则返回
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
// 若正在rehash,则使用ht[1]哈希表,否则使用ht[0]哈希表
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 为哈希表节点申请内存
entry = zmalloc(sizeof(*entry));
// 根据键的哈希值寻找节点链表,插入到表头
entry->next = ht->table[index];
ht->table[index] = entry;
// 增加节点计数
ht->used++;
// 设置节点的键
dictSetKey(d, entry, key);
return entry;
}
2.3.4 字典的扩张
- 字典初始大小:字典的大小指的是哈希表的槽数,即哈希表中链表的条数
#define DICT_HT_INITIAL_SIZE 4
- 对指定字典大小进行规整:大于等于指定大小的最小2次幂值
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX;
while(1) {
if (i >= size) return i;
i *= 2;
}
}
- 将字典扩张到指定大小
int dictExpand(dict *d, unsigned long size)
{
// 新的哈希表
dictht n;
// 将指定大小值进行规整:不小于size的最小2次幂值
unsigned long realsize = _dictNextPower(size);
// 判断扩张大小无效的情况
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR;
// 设置新哈希表属性
n.size = realsize;
n.sizemask = realsize-1;
// 创建链表指针数组
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// 若是初始化,则此次不是rehash,将新哈希表设置为0号即可。
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// 若0号哈希表存在,则此次是rehash,将新哈希表设置为1号
// 并且将字典置为rehash中状态,以便操作元素时进行rehash
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
2.3.5 rehash
随着操作的不断进行,哈希表的中元素最终会偏多或偏少,为了使哈希表的负载因子维持在一个合理范围内,需要对哈希表进行伸缩,而伸缩是通过rehash(重散列)来完成的。rehash步骤如下:
- 新建一张哈希表,即为ht[1](称之为1号哈希表),其大小为:
- 若为扩张,则是大于等于现有节点数2倍的最小2次幂值;
- 若为收缩,则是大于等于现有节点数的最小2次幂值。
- 对ht[0](称之为0号哈希表)中的所有元素重新计算键的哈希值和索引值,然后迁移到1号哈希表。
- ht[0]中的所有元素迁移完毕后,释放ht[0],然后将ht[1]设置为ht[0]。其后为ht[1]新建一张空哈希表,以备下次rehash使用。
如果字典中的元素数量太多,一次性地将所有元素迁移会花费很长时间,为了避免影响服务性能,Redis采用分步渐进式rehash,其步骤如下:
- 新建ht[1]哈希表(同上第1步)
- 在字典中维护一个计数器rehashidx,-1表示未开始,0表示开始。
- 开始rehash后,每次对字典进行添加、删除、查找、更新等操作时,会顺带进行一步rehash,将ht[0]中的部分元素迁移互ht[1],完成后,rehashidx加1。
- 最终,ht[0]中的所有元素迁移到ht[1],然后释放ht[0],将ht[1]置为ht[0],rehashidx复位为-1,一次完整的rehash结束。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
// 进行n步rehash,如果还有键需要迁移则返回1,否则返回0
//
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
2.3.4 删除元素
// 删除键对应的元素,成功返回DICT_OK,找不到元素返回DICT_ERR
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
}
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
// 无节点返回空
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算键的哈希值
h = dictHashKey(d, key);
// 遍历两个哈希表
for (table = 0; table <= 1; table++) {
// 哈希值与大小掩码,得出节点链表下标
idx = h & d->ht[table].sizemask;
// 节点链表头节点
he = d->ht[table].table[idx];
prevHe = NULL;
// 从头节点依次遍历整个链表
while(he) {
// 若找到相同键节点
if (key==he->key || dictCompareKeys(d, key, he->key)) {
// 将节点从链表中移除
if (prevHe) // 中间节点
prevHe->next = he->next;
else // 头节点
d->ht[table].table[idx] = he->next;
if (!nofree) {
// 释放键
dictFreeKey(d, he);
// 释放值
dictFreeVal(d, he);
// 释放节点
zfree(he);
}
// 节点计数减1
d->ht[table].used--;
// 返回
return he;
}
// 当前节点不是,移动到下一节点
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}