本文实例来源《我要自学网》(excel 2010 vba 视频教程)
这段时间萌生一个念头,将微软脚本正则表达式以一个初学者的见解进行梳理,一是加深理解,二是作为归纳总结的记录,方便以后查阅。
正则表达式对于像我这样的初学者,似乎作用并不大,无非是在EXCEL中,比查找替换更为强大一点的功能,单纯从工作角度,也与工作使用联系不大,即使它在多种语言环境中都有一席之地,但此时此刻感觉用处不大的时候容易产生不那么想知晓的分别心。
然而很多时候人出发的目的并不是有用无用,而是源自于一点点兴趣。
正则表达式 regular expression
正则是一个汉语词汇,拼音为zhèng zé,基本意思是正其礼仪法则;正规;常规;正宗等。出自《楚辞·离骚》、《插图本中国文学史》、《东京赋》等文献。
这是百度释义,正则一听就觉得意义很多,而且难以理解,我等凡人简单理解成规则就好。以下内容仅适用于VBA。
【基础语法篇】
sub text()
dim myreg as object
set myreg=createobject("vbscript.regexp")'后期绑定
with myreg
.pattern="[a-z]" '匹配条件
.ignorecase =true'是否忽略大小写,ture 就忽略,false就区分
.global =true'范围为全部,忽略则为第一个,一般都要写
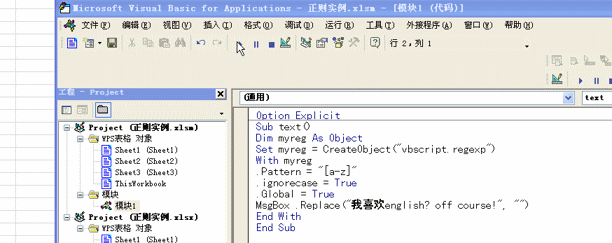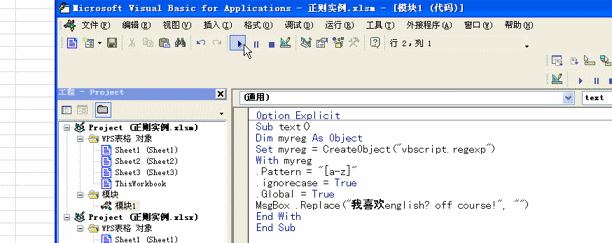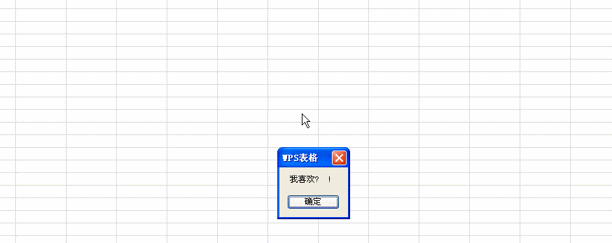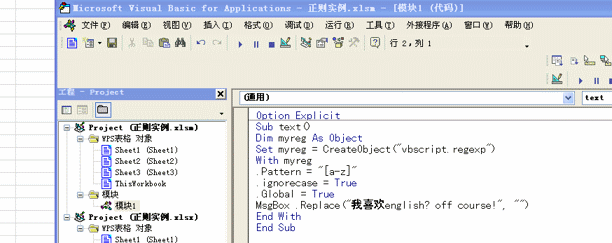
msgbox.replace("我喜欢english? of course!","")'替换方法,将匹配中的所有字母替换为空
end with
end sub
三参数:
global
ignorecase
pattern(必选项)
方法:
replace
execute
submatches
方法会在实例中一一介绍。
正则表达式的对象属性基本就这么几个,复杂在于匹配规则的运用,而学正则表达式,实际上就是理解运用pattern(匹配条件)
【普通字符篇】
普通字符相对简单,用EXCEL自带的功能查找替换就可以完成简单的部分,快捷键是CTRL+F,值得一提的是在VBA中的replace方法,在逐个匹配过程中,如果不匹配则不会发生替换。

Sub text()
Dim rng As Range, regx As Object, rn As Range, n%
Set regx = CreateObject("vbscript.regexp")'后期绑定
With regx'with j简化代码
.Global = True
.ignorecase = True
.Pattern = "消售"
Set rng = Range("a2:a" & Cells(Rows.Count, 1).End(xlUp).Row)
For Each rn In rng'循环
n = n + 1
Cells(n + 1, 3) = .Replace(rn.Value, "销售")'将正则匹配条件替换为新内容,注意如果是数字则是文本格式
Next
End With
End Sub
【元字符篇】
元字符的特点是字母前加斜杠,这里要用到正则表达式测试工具,我从EXLHOME网站上下载了一个,建议不要从百度这么宽泛的网站上搜索,而是比较精准的网站。
这里需要注意:
1.vba元字符\w,匹配不了汉字,根据这一特性可以筛选出汉字。
2.vba元字符\b,匹配边界由于汉语书写方式与英语书写习惯有很大的区别,所以在汉语环境中\b实际作用不大。
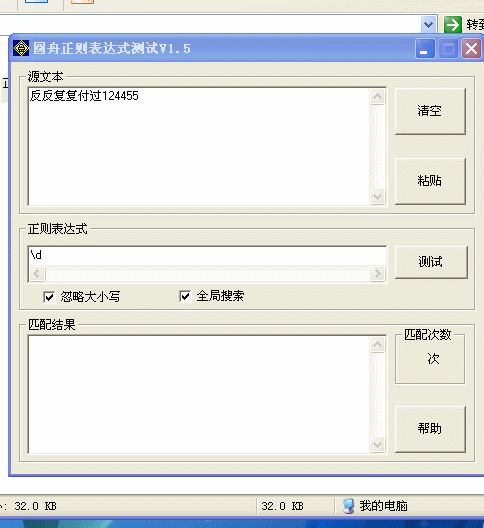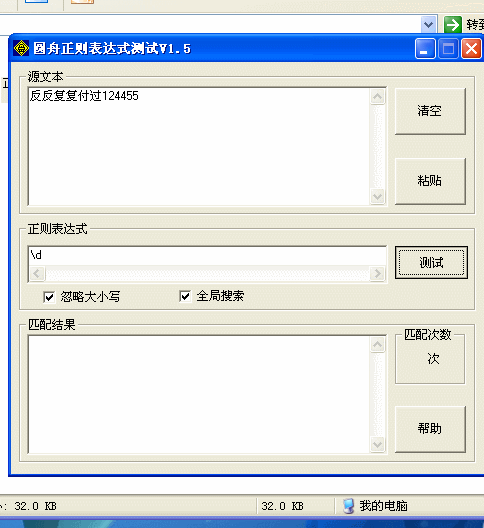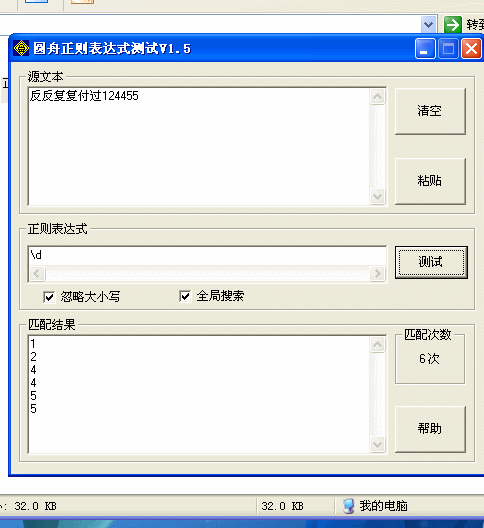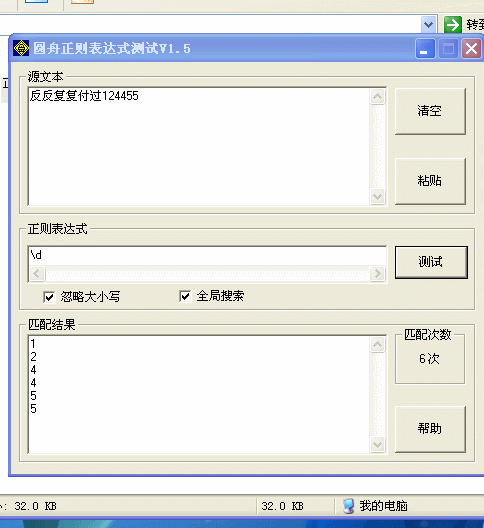
\d 匹配一个数字字符。[0-9]
\D 匹配一个非数字字符。[^0-9]
\w 匹配包括下划线的任何单词字符。[A-Za-z0-9_]
\W 匹配任何非单词字符。[^A-Za-z0-9_]
\s 匹配任何空白字符,包括空格、制表符、换页符等等。
\S 匹配任何非空白字符。
\b 匹配一个单词边界,也就是指单词和空格间的位置。
\B 匹配非单词边界。
\n 匹配一个换行符。
\r 匹配一个回车符。
\t 匹配一个制表符。
. 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符
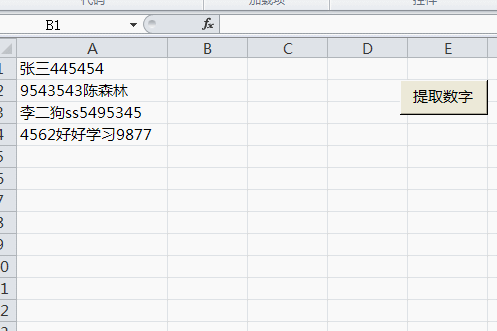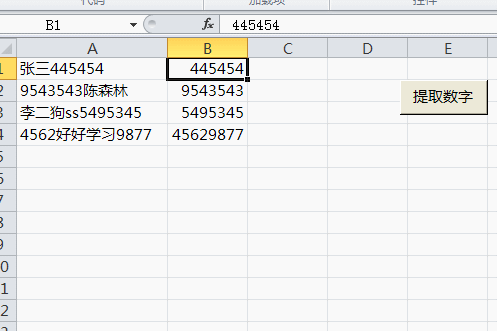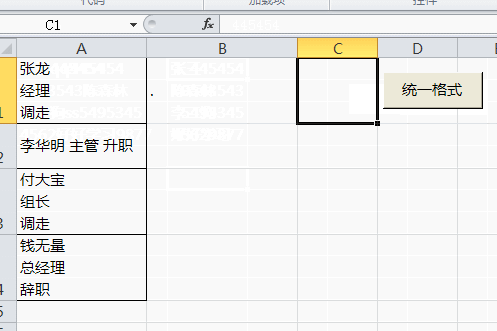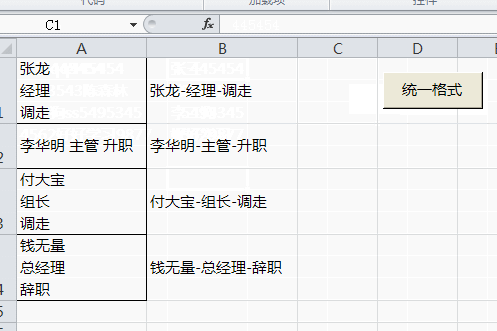
Sub 提取数字()
Dim regx As Object, rng As Range
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.ignorecase = True
.Pattern = "\D"
For Each rng In [a1:a4]
Cells(rng.Row, 2) = .Replace(rng.Value, "")
Next
End With
End Sub
Sub 提取汉字()
Dim regx As Object, rng As Range
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.ignorecase = True
.Pattern = "\w"
For Each rng In [a1:a4]
Cells(rng.Row, 2) = .Replace(rng.Value, "")
Next
End With
End Sub
Sub 规范格式()
Dim regx As Object, rng As Range
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.ignorecase = True
.Pattern = "\s"
For Each rng In [a1:a4]
Cells(rng.Row, 2) = .Replace(rng.Value, "--")
Next
End With
End Sub
【量词篇】
量词在正则表达式中作用突破元字符只能匹配单个字符的限制,从而使表达式更为灵活。
这里要介绍Execute方法,语法object. Execute(sourcestring as string) as string, object为你定义的正则表达式对象(如:regEX),参数sourcestring为要对其进行查找的字符串。Execute方法查找并返回符合要求的字符串的集合,相当于使用“查找”功能。
这是从网上摘抄的一段解释,很专业也很难理解,我的理解是与Replace方法做对比,replace是将匹配结果替换为新的内容,而execute方法是将匹配结果筛选出来,放在对应区域。
? 匹配前面的子表达式零次或一次。
+ 匹配前面的子表达式一次或多次。
* 匹配前面的子表达式零次或多次。
{n} n 是一个非负整数。匹配确定的 n 次。
{n,} n 是一个非负整数。至少匹配n 次。
{n,m} m 和 n 均为非负整数,其中n <= m。
例一:
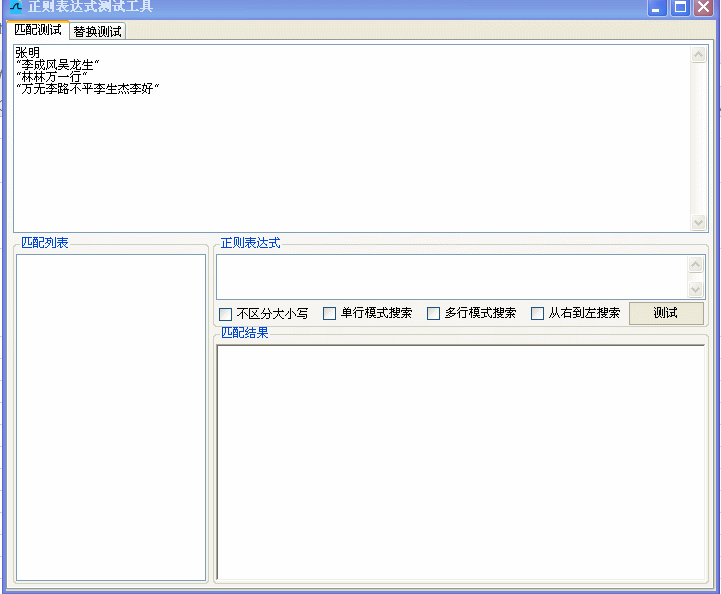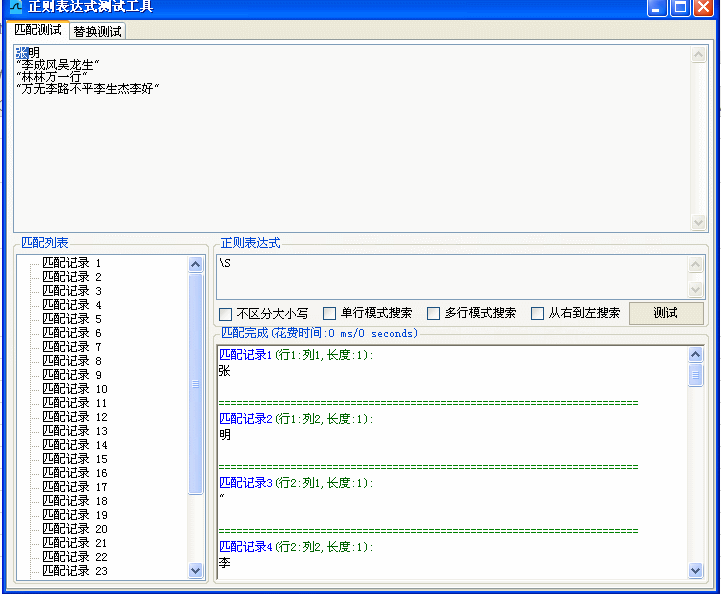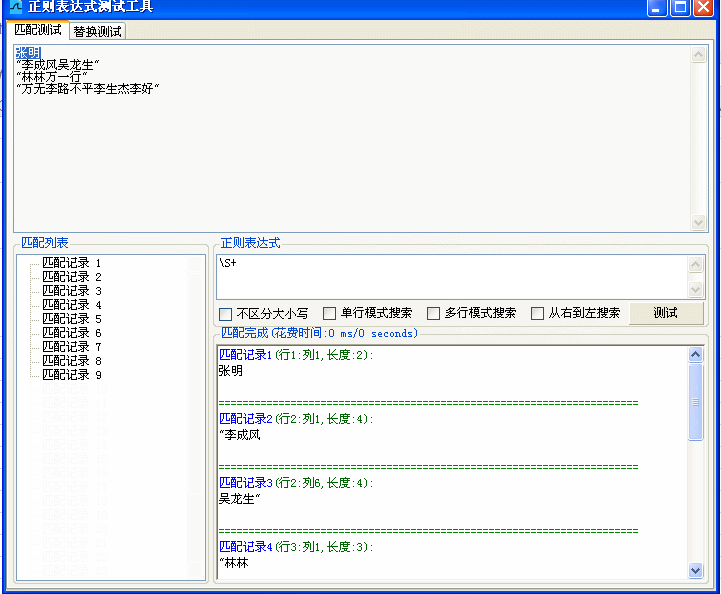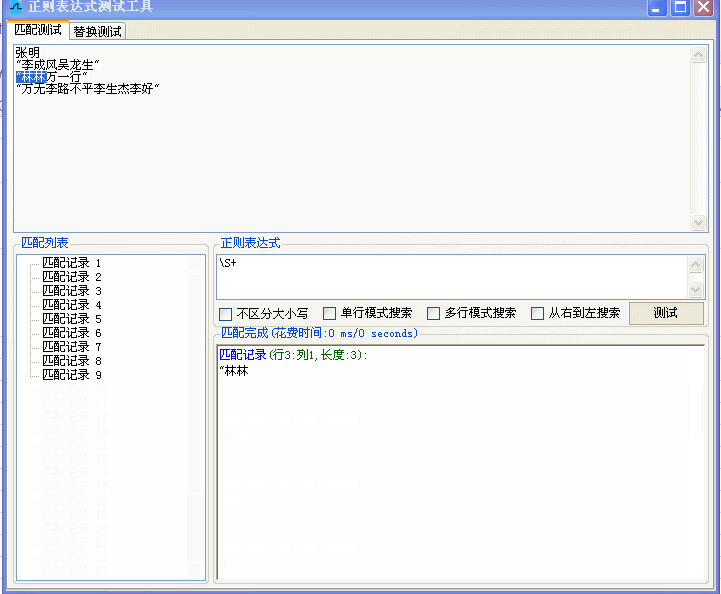
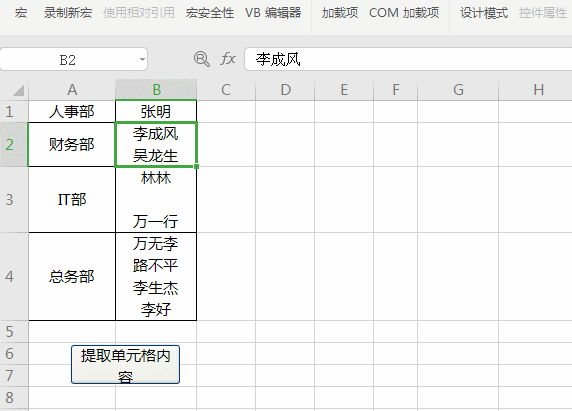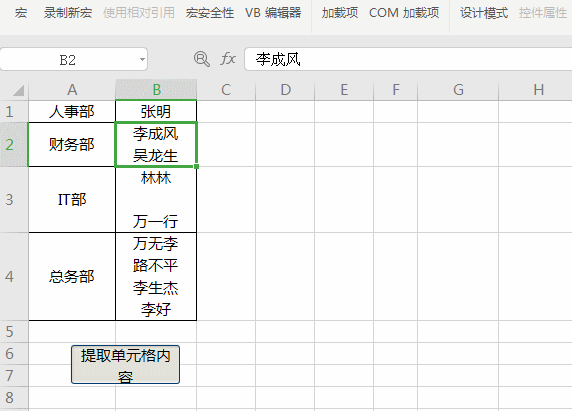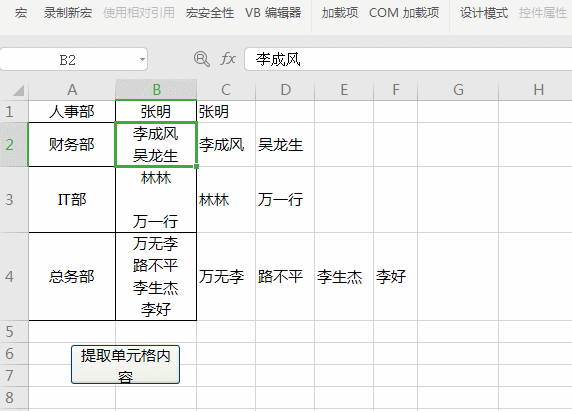
Sub 提取姓名()
Dim regx As Object, rng As Range, n%, mat, m
Set regx = CreateObject("vbscript.regexp")
regx.Global = True
regx.Pattern = "\S+"
For Each rng In [b1:b4]
Set mat = regx.Execute(rng)
For Each m In mat'两层循环优先循环内层循环
n = n + 1
Cells(rng.Row, n + 2) = m
Next
n = 0
Next
End Sub
例2:

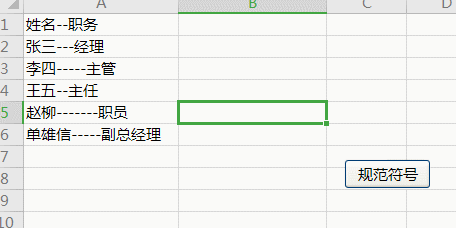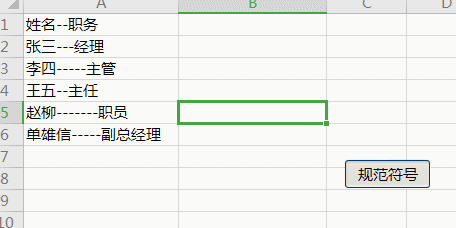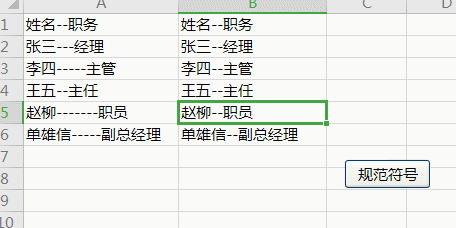
Sub 规范符号()
Dim rng As Range, regx As Object
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "-{2,}"
For Each rng In [a1:a6]
Cells(rng.Row, 2) = .Replace(rng.Value, "--")
Next
End With
End Sub
【分组篇】
分组其实就是表达式加上(),类似算数运算中提升优先级的方式。

Sub 去除重复字()
Dim regx As Object
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "(就会)+"
[b1] = .Replace([a1].Value, "就会")
End With
End Sub
【捕获模式】
“他渴望她,当然不是爱情,爱情是种低下的东西。现在有一个机会,将她的频率改造成和他一样。”——《隐杀》
捕获模式是分组的延伸,通过\1捕获左边表达式中()里的正则表达式。、(d{4})数字4个,\1捕捉括号中完全一致的内容,不符合则不匹配。
test方法,test从字面意义理解就是测试,判断是否符合正则表达式。

Sub 捕获()
Dim regx As Object, rng As Range, n%
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "(\d{4}).+\1.+"
For Each rng In [b2:b10]
If .test(rng) Then
n = n + 1
Cells(n + 1, "d") = Cells(rng.Row, "a")
End If
Next
End With
End Sub
【字符组篇】
字符组有着强大功能,它能匹配包括空格,下划线,标点符号等,相比对应元字符它更为灵活。
[]在中括号中选若干字符之一
[0-9]匹配数字
[^0-9]匹配非数字,[2468]不代表2468,而是2、4、6、8中的一个数字,中间是或的关系
[xyz] 字符集合。匹配所包含的任意一个字符。
[^xyz] 负值字符集合。匹配未包含的任意字符。
[a-z] 字符范围。匹配指定范围内的任意字符。
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。
[一-龢]匹配汉字。龢(he)
此处选择一个有代表性的例子。

Sub 重新组合()
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "[0-9]+.+[\.?]"
For Each Rng In Sheet3.[a1:a100]
Set mat = .Execute(Rng)
For Each m In mat
n = n + 2
Cells(-1 + n, 1) = m
Next
Next
End With
n = 0
With regx
.Global = True
.Pattern = "[一-龢]+.+[。?!]"
For Each Rng In Sheet3.[a1:a100]
Set mat = .Execute(Rng)
For Each m In mat
n = n + 2
Cells(n, 1) = m
Next
Next
End With
End Sub
【首尾锚定篇】
^ 匹配输入字符串的开始位置。
$ 匹配输入字符串的结束位置。
不知道为什么正则表达式有股海洋的气息,首尾锚定可以直观记忆成锚首是尖,锚尾是绞盘。它的作用是截取限定匹配区域。

Sub test()
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "^[A-Z]+\d+$"
For Each Rng In [a1:a17]
Set mat = .Execute(Rng)
For Each m In mat
n = n + 1
Cells(n, 2) = m
Next
Next
End With
End Sub
【零宽断言篇】
"就算找到你爱的人,也得不到,只能默默守护在他(她)的左边。"——曾贤志
零宽断言也称环视,在vba中只能从左向右匹配,它的作用是匹配在字符之前,不代表任何字符。作用相当与插入其他字符。
(?=…)注意括号。
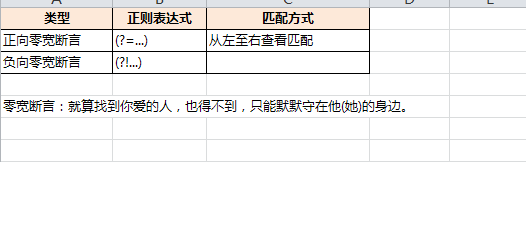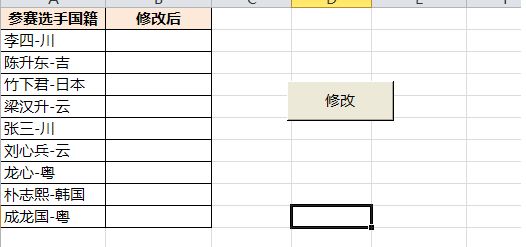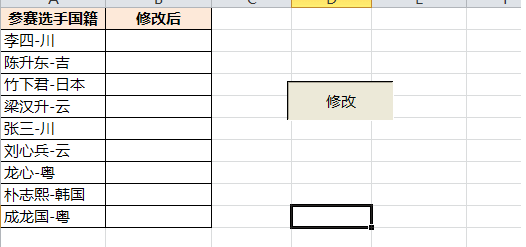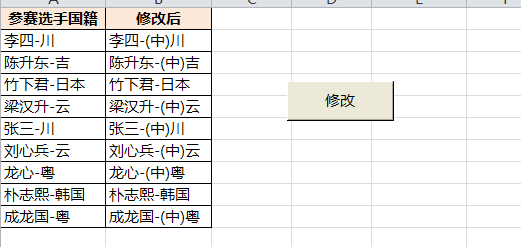
Sub test()
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "(?=[川吉云粤])"
For Each Rng In [a2:a10]
Cells(Rng.Row, 2) = .Replace(Rng, "(中)")
Next
End With
End Sub
【懒惰模式与贪婪模式】
当?号紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时是懒惰模式
懒惰模式:尽可能少的匹配所搜索的字符串
贪婪模式:尽可能多的匹配所搜索的字符串(默认模式)

Sub test()
With CreateObject("vbscript.regexp")
.Global = True
.Pattern = "第\d+章.*?[一-龢]+.+?\d+"
Set mat = .Execute([a1])
For Each m In mat
n = n + 1
Cells(n + 1, "c") = m
Next
End With
End Sub
【分组的组成员】
这里要介绍一下submatches属性,在分组后(就是加括号)会产生组1组2……,组1可以表达成$1,以此类推,同样可以表达成submatches(0),submatches(1)…以此类推。简单来说就是一个正则表达式中一个括号代表一组,两个代表两组,将它们的组成员进一步匹配。
实例一:

Sub 捕获分组值1()
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "([一-龢]{3,}) (\d+人)"
Set mat = .Execute([a1])
For Each m In mat
n = n + 1
Cells(n + 1, 3) = .Replace(m.Value, "$1")
Cells(n + 1, 4) = .Replace(m.Value, "$2")
Next
End With
End Sub
Sub 捕获分组值2()
Set regx = CreateObject("vbscript.regexp")
With regx
.Global = True
.Pattern = "([一-龢]{3,}) (\d+人)"
Set mat = .Execute([a1])
For i = 0 To mat.Count - 1
Cells(i + 2, 5) = mat(i).submatches(0)
Cells(i + 2, 6) = mat(i).submatches(1)
Next
End With
End Sub
实例二:

Sub 提取()
n = 1
With CreateObject("vbscript.regexp")
.Global = True
.Pattern = "(\S+) (\S+) (\S) (\d+)(( \S+){1,3})"
Set mat = .Execute(Sheet3.[a1])
For Each m In .Execute(Sheet3.[a1])
n = n + 1
Cells(n, 1) = .Replace(m, "$1")
Cells(n, 2) = .Replace(m, "$2")
Cells(n, 3) = .Replace(m, "$3")
Cells(n, 4) = .Replace(m, "$4")
Cells(n, 5) = .Replace(m, "$5")
Next
End With
End Sub
EXCEL里常用的几个正则表达式
^/d+$ //非负整数(正整数 + 0)
^[0-9]*[1-9][0-9]*$ //正整数
^((-/d+)|(0+))$ //非正整数(负整数 + 0)
^-[0-9]*[1-9][0-9]*$ //负整数
^-?/d+$ //整数
^/d+(/./d+)?$ //非负浮点数(正浮点数 + 0)
^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$ //正浮点数
^((-/d+(/./d+)?)|(0+(/.0+)?))$ //非正浮点数(负浮点数 + 0)
^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$ //负浮点数
^(-?/d+)(/./d+)?$ //浮点数
^[A-Za-z]+$ //由26个英文字母组成的字符串
^[A-Z]+$ //由26个英文字母的大写组成的字符串
[^a-z+$] '由26个英文字母的小写组成的字符串
[^A-Za-z0-9]+$ ‘由数字和26个英文字母组成的字符串
^/w+$ //由数字、26个英文字母或者下划线组成的字符串
^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$ //email地址
^[a-zA-z]+://(/w+(-/w+)*)(/.(/w+(-/w+)*))*(/?/S*)?$ //url
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$ //Emil
(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)? //电话号码
^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$ //IP地址
匹配中文字符的正则表达式: [^/u4e00-/u9fa5]
匹配双字节字符(包括汉字在内):[^/x00-/xff]
匹配空行的正则表达式:/n[/s| ]*/r
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) //>/
匹配首尾空格的正则表达式:(^/s*)|(/s*$)
匹配Email地址的正则表达式:/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*
匹配网址URL的正则表达式:^[a-zA-z]+://(//w+(-//w+)*)(//.(//w+(-//w+)*))*(//?//S*)?$
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
匹配国内电话号码:(/d{3}-|/d{4}-)?(/d{8}|/d{7})?
匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$
【总结】
正则表达式在处理不规范的数据时,有着强大的功能,可能由于职业与自我认知的限制,对我来说用处并不是很大,目前能想到的只有word向excel数据转换,手工盘点账目后期处理以及目前工作中部门级名称编码不统一的处理。
告一段落,下一目标向最难整理(有着三分之一非常规数据)的成本进军。