- 1.本系列基于新生大学课程《Python编程&数据科学入门》和公开的参考资料;
- 2.文章例子基于python3.6,使用Windows系统(除了安装,其余基本没有影响);
- 3.我是纯小白,所以,错误在所难免,体系会逐渐成熟;如果您发现了错误,也烦请帮我指出来,在此先谢过了。
终于来更新第七节课了,这堂课主要是抄代码,自己整合的较少。
这节课学习的是绘图和可视化,主要内容是matplotlib 绘图基础。内容主要有三个:
- matplotlib绘图基础
- 一个具体的应用案例
- seaborn数据可视化的用法
一、matplotlib API入门
matplotlib是python的一个绘图工具包。之前我们在学习pandas时,已经知道通过pandas的一些属性,也可以画出散点图等图形。为什么要再出一个matplotlib呢?
一个原因是matplotlib基于matlib,它的函数更加丰富,而且它能够绘出更复杂的图形,他输出的是出版物级别的图,是一个非常强大的工具。
其实,学习matplotlib其实技巧并不重要,重要的是我们要知道哪些数据可以通过什么类型的图形来展示,以及这些类型的函数都在哪里。
前者需要我们大量阅读别人的数据分析图表,类似于学习音乐的“煲耳朵”,而后者可以在matplotlib官网上方便的找到。这也许是后话了。
下面我们正式开始。
进入python环境:
# 先导入库
import matplotlib.pyplot as plt
# 导入其他的包
import numpy as np
import pandas as pd
# 设置直接在notebook中输出图形
%matplotlib inline
# 设置图形的清晰度
%config InlineBackend.figure_format = 'retina'
下面我们来绘制一副余弦图。
# 先设置坐标x的取值范围,定义余弦函数
x = np.arange(0,15,0.1)
y = np.cos(x)
# 开始绘图
plt.plot(x, y)
[]
很简单,就画出一幅余弦图了。但这样不是很美观,可以对这幅图进行美化设计。
# 将前面的函数搬下来
x= np.arange(2,15,0.1)
y = np.cos(x)
plt.plot(x,y)
# 添加标题,x轴和轴的名称
plt.title('cos function')
plt.xlabel('x value')
plt.ylabel('y value')
# 用show()函数用来把图形前面的无关符号去掉。
plt.show()
我们还可以继续装饰,增加线的颜色、线型、粗细等。
matplotlib设置了很多简化的形式:
- 颜色首字母代表颜色,比如红色red用r代替,绿色green用g代替;
- 用“-”代表直线,“--”代表虚线,用“^”代表三角等等
# 设置线型为虚线,线宽为3.0
plt.plot(x,y , 'b--', linewidth = 3.0)
# 设定x轴和y轴的使用区间
plt.axis([0,6, -1.2, 1])
# 加网格线
plt.grid(True)
# 加文字描述
plt.text(2, 0, 'cos function')

这个图形就相对比较美观了。
用matplotlib绘制多图
用matplotlib还可以很方便的绘制多个图形,下面绘制y= x, y= x 2(平方), y= x3(3次方)这3个函数
# 先定义函数的范围
x = np.arange(0, 5, 0.2)
# 用简化的形式:颜色用一个字母代替,线性也用一个字母代替。
plt.plot(x, x,'r-' ,x, x**2,'g^', x, x**3, 'y--')
plt.show()
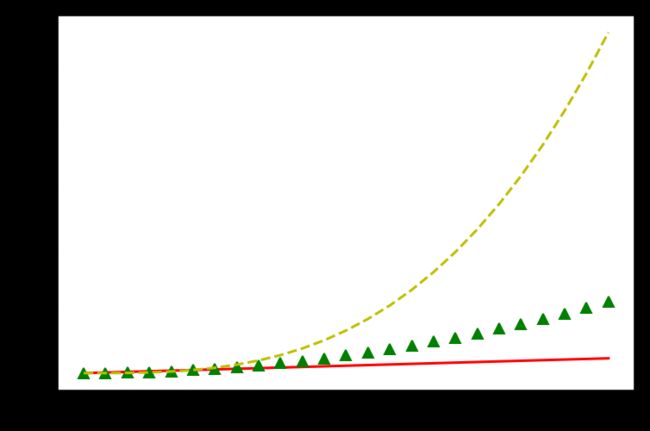
这种方法比我们在pandas学的方法要简单多了。
二、一个具体的案例
# 导入一个excel数据文件
df = pd.read_excel('lesson/sample-salesv3.xlsx')
df.head()
# account number表示账号,name代表交易的公司,sku代表商品的货号,quantity表示购货量,ext price表示总价
就是下面这样一张表:
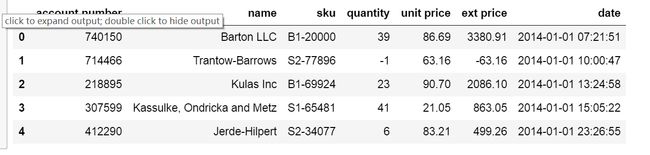
# 先查看这个表格的总体情况
df.info()
# 总共1500行,有7列,4列字符型,3列数字型
RangeIndex: 1500 entries, 0 to 1499
Data columns (total 7 columns):
account number 1500 non-null int64
name 1500 non-null object
sku 1500 non-null object
quantity 1500 non-null int64
unit price 1500 non-null float64
ext price 1500 non-null float64
date 1500 non-null object
dtypes: float64(2), int64(2), object(3)
memory usage: 82.1+ KB
# 再查看一下参加交易公司的数量
len(df.name.unique())
20
再来根据这个表格生成一个适合我们统计的表格,我们只需要公司名称、购货量、交易笔数这3项。
# 用groupby来分组,用agg进行聚合运算,sum可以统计总额,count计算交易的次数
# reset_index是重置函数,取消name作为索引
# sort_values按照指定的列进行排序,ascending=False设置降序排序
top10 = df.groupby('name')['ext price'].agg(['sum','count']).reset_index().sort_values(by = 'sum', ascending = False)[:10]
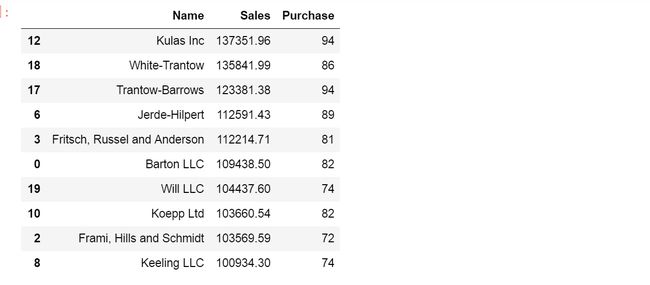
top10
# 可以使用rename对变量重命名,replace表示替换原来的变量名称,如果不替换,就只是产生了一个引用
top10.rename(columns = {'name':'Name','sum':'Sales','count':'Purchase'},inplace=True)
top10
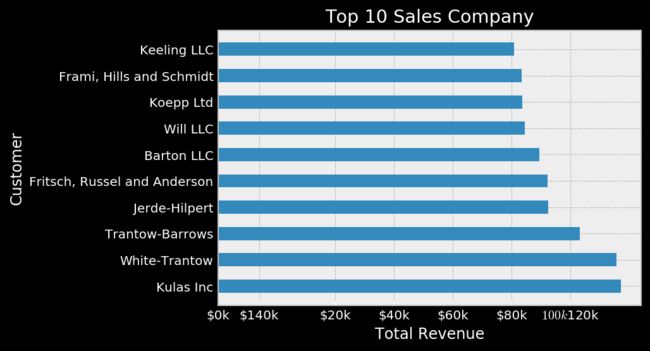
下面我们用这个新表画一个条形图:
# 设置作图的风格
plt.style.use('bmh')
# bar绘制水平的直方图,barh绘制水平的条形图
plt.barh(np.arange(10), top10['Sales'], height = 0.5)
# 下面再增加一些必要的装饰
plt.title('Top 10 Sales Company')
plt.xlabel('Total Revenue')
plt.ylabel('Customer')
# 修改横纵坐标的刻度
plt.yticks(np.arange(10), top10.Name)
plt.xticks([0.20000,40000,60000,80000,100000,120000,14000],
['$0k','$20k','$40k','$60k','$80k','$100k''$120k','$140k'])
plt.show()
PS: 刚才死活出不来图,显示错误:ValueError: incompatible sizes: argument 'width' must be length 10 or scalar。
刚开始没注意。后来想读读看看。原来是因为字符的长度不匹配,修改之后就好了。不懂英语真可怕,明明写的是数量必须是10个,我就是没明白。
# 用plt.style.available查看作图的风格
plt.style.available
下面这些都是可以用的作图风格,可以挨个试试,选自己喜欢的风格。
['bmh',
'classic',
'dark_background',
'fivethirtyeight',
'ggplot',
'grayscale',
'seaborn-bright',
'seaborn-colorblind',
'seaborn-dark-palette',
'seaborn-dark',
'seaborn-darkgrid',
'seaborn-deep',
'seaborn-muted',
'seaborn-notebook',
'seaborn-paper',
'seaborn-pastel',
'seaborn-poster',
'seaborn-talk',
'seaborn-ticks',
'seaborn-white',
'seaborn-whitegrid',
'seaborn',
'_classic_test']
# 下面画出交易总数最高的10个公司的条形图
top10_1 = df.groupby('name')['quantity'].agg(['sum','count']).reset_index().sort_values(by='count', ascending = False)[:10]
top10_1

开始画图,使用经典风格。
plt.style.use('classic')
plt.barh(np.arange(10), top10_1['count'], height = 0.5 )
plt.title('The Top10 Salses Count')
plt.xlabel('Count')
plt.ylabel('Customer')
plt.yticks(np.arange(10), top10_1['name'])
plt.show()

matplotlib能够很方便的绘制多图。比如在同一幅图中绘制销售总额和交易次数的条形图:
# 先设置画布大小
fig = plt.figure(figsize = (20,8))
# 设置图像标题、文字大小、加粗
fig.suptitle('Sales Analysis', fontsize = 16, fontweight = 'bold')
# 添加第一个子图
ax1 = fig.add_subplot(121) # 121代表的是1行2列中的第1个图
plt.barh(np.arange(10), top10.Sales, height = 0.5, tick_label = top10.Name)
plt.title('Revenue')
# 加入平均销售额,用一条垂直的虚线表示
revenue_average = top10.Sales.mean()
plt.axvline(x=revenue_average, color = 'y', linestyle = '--', linewidth = 2)
# 同样的,添加第二个图。
ax2 = fig.add_subplot(122)# 122代表的是1行2列中的第2个图
plt.barh(np.arange(10), top10.Purchase, height = 0.5)
plt.title('Units')
# 让第二幅图不显示纵轴的刻度
plt.yticks(visible = False)
# 加入交易个数的平均线,也用黄色的垂直虚线表示
purchases_average = top10.Purchase.mean()
plt.axvline(x= purchases_average, color = 'y', linestyle='--', linewidth=2)
plt.show()
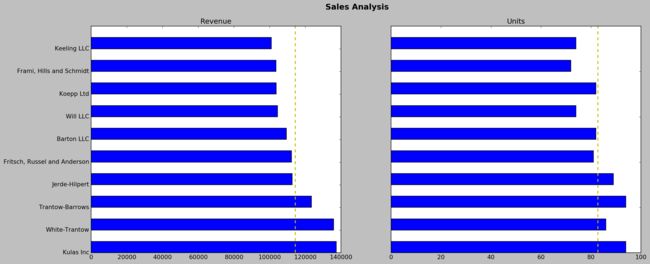
这就画好了两幅图。
学习matplotlib的三个小技巧:
去官网学习。官网有全部的图形库,特别是可以从官网提供的例子来学习,这样学习起来非常快。而且能够一边学习,一边提高英文的水平。
多做笔记。因为图形的种类非常多,参数多,不可能全部记住,可以把一些重点的记录在笔记里面,随时调用。比如,可以用印象笔记,记录一些函数。
多用google,可以找到很多资料。
我们再多看几个例子:
# 绘制饼图
plt.pie(top10.Sales, labels= top10.Name, autopct='%1.1f%%')
# 调整坐标轴比例为1:1,也就是圆形
plt.axis('equal')
plt.show()

# 画一个散点图
plt.scatter(x= top10.Purchase, y=top10.Sales, s = 50)
plt.show()

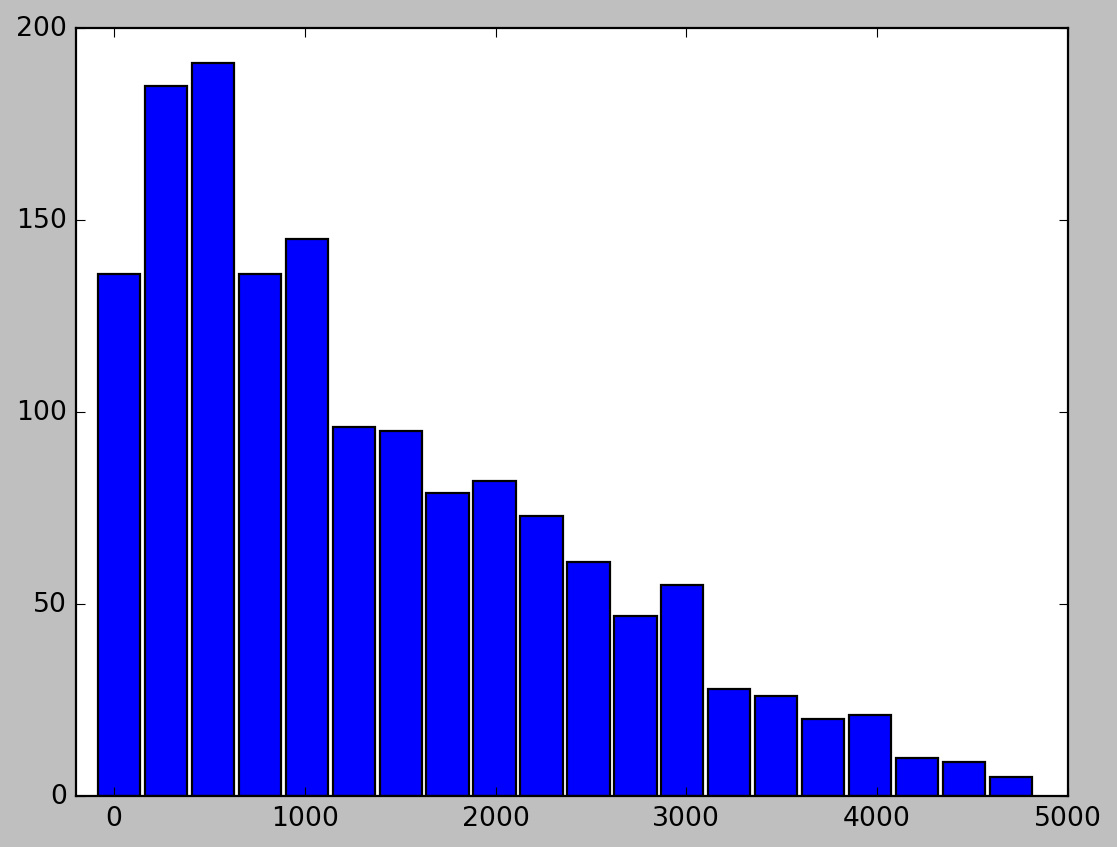
# 绘制直方图。用hist直方图,bins代表区间个数
plt.hist(df['ext price'], bins = 20, rwidth = 0.9)
# 设置x轴区间的范围
plt.xlim(-200,5000)
plt.show()
三、seaborn
下面再来看看seaborn。
seaborn是在matplotlib基础上开发的一个模块,它也是为了实现统计可视化,可以与pandas无缝对接,但它比matplotblib使用更简单,更便于新手直接使用。
matplotlib和seaborn的关系就像pandas和numpy的关系一样。
# 首先仍是导入seaborn包
import seaborn as sns
# 导入鸢尾花的数据
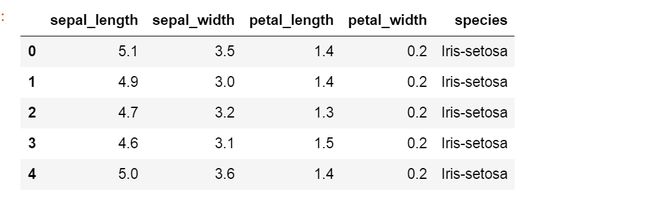
iris = pd.read_csv('iris.csv', names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'])
iris.head()
# 使用matplotlib绘制散点图
plt.scatter(iris.pental_width, iris.petal_length)
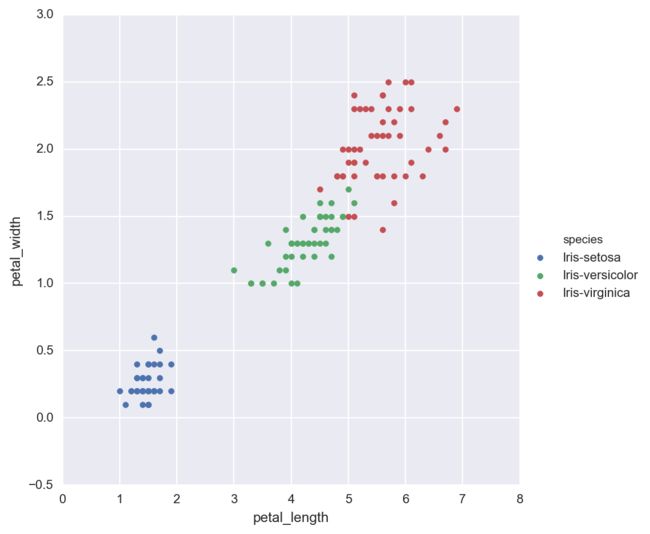
下面再使用seaborn做图来对比一下, 仍然用品种划分数据画出花瓣长度和宽度的散点图。
FacetGrid对象是用来连接pandas DataFrame到一个有着特别结构的matplotlib图像。具体来说,FacetGrid是用来画一组固定的关系给定某个变量的某个值。FacetGrid中的hue参数指明划分数据的变量,这里是species(品种)
sns.FacetGrid(iris, hue="species",size = 6)\
.map(plt.scatter, 'petal_length', 'petal_width').add_legend() #legend增加图例
下面用seaborn画出箱线图
sns.boxplot(data = iris, x = 'species', y = 'sepal_length')
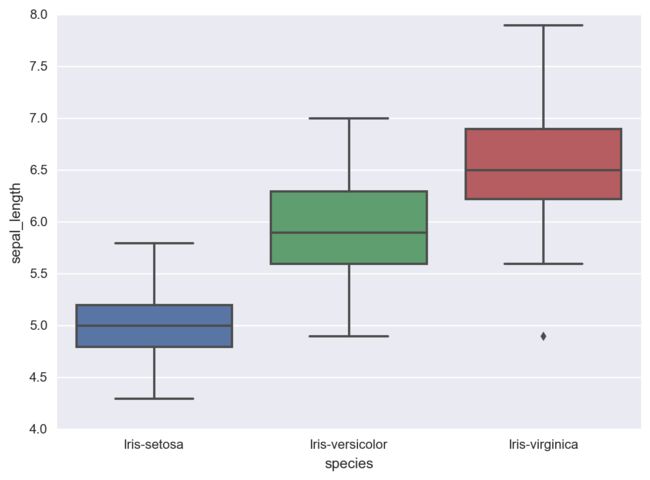
大家注意到了没有,在红色的箱线图的下方有一个黑色的小点,这个点上次也出现过,这个点是一些离散值。
多变量图
也就是通过一行命令画出四个变量的配对关系。
sns.pairplot(iris, hue='species')
# 这个图是按照种类划分的多图。
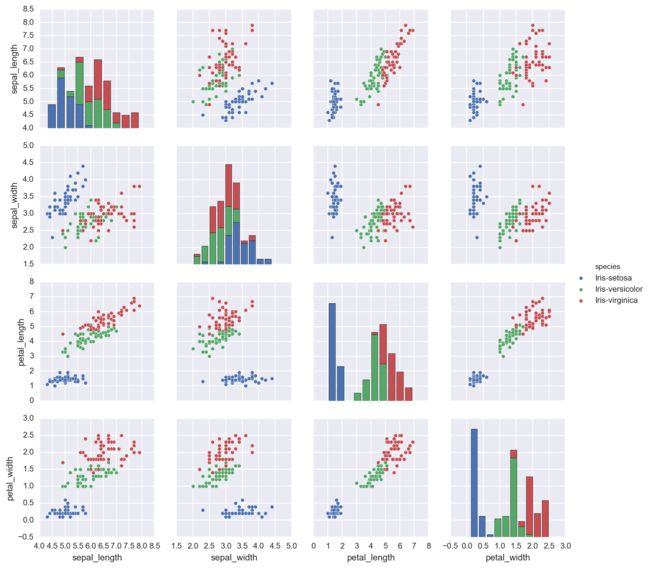
seaborn这个命令的效率太惊人了。
两个不同要素对应的是散点图,一个因素(对角线上)的是条形图。