OptEx: A Deadline-Aware Cost Optimization Model for Spark
最近在研究一些Spark成本优化的东西,看了一些论文稍微总结一下思路,方便思维拓宽和希望与大家交流!
本篇博文参考自:
2016 16th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing:
《OptEx: A Deadline-Aware Cost Optimization Model for Spark》
1 文章概述及问题描述
现如今,基本上所有的云计算服务提供商在向用户提供计算服务时都是以虚拟机实例来提供,并且不同种类的虚拟机有不同的硬件配置(cpu、I/O等),这些都是按小时来计费,并且可向用户提供微型、小型、大型等不同规模的集群。但是目前并没有一种方案能够在满足用户时间及金钱成本等需求(SLO)的基础上很准确地向用户推荐一种规模或是配置的计算实例的方法或参考,并且也没有一项成本优化的策略来降低用户的使用成本,因此,这样的一个问题现状促使了本文对这两个问题的探讨和研究。
文中所介绍的OptEx模型,是一个用于预测spark作业运行时间(平均估计错误率6%),并且能够以优化成本为目的地去预估一个合适的集群组合来推荐给用户,这样的组合既可以为用户减少使用成本,并且能够保证用户对作业运行时的SLO需求(预测准确率98%)
2 论文中的相关术语以及spark基础
- SLO
全称:Service Level Objective
维基百科:
A service level objective (SLO) is a key element of a service level agreement (SLA) between a service provider and a customer. SLOs are agreed upon as a means of measuring the performance of the Service Provider and are outlined as a way of avoiding disputes between the two parties based on misunderstanding.
SLO与SLA易混淆,那么SLA是什么?它与SLO的关系如何?:
The SLA is the entire agreement that specifies what service is to be provided, how it is supported, times, locations, costs, performance, and responsibilities of the parties involved. SLOs are specific measurable characteristics of the SLA such as availability, throughput, frequency, response time, or quality. These SLOs together are meant to define the expected service between the provider and the customer and vary depending on the service's urgency, resources, and budget. SLOs provide a quantitative means to define the level of service a customer can expect from a provider.
- job completion time
表示spark作业的完成时间
- profile
文中一直提到profile或是profiling,这个是通过基准测试来获取一些模型需要的参数后,将这些参数保存在profile中的,而这些基准测试的参数值最终会被拿来作为真实作业参数的估计。
3 方法概述
OptEx模型旨在解决两个问题:spark job的完成时间的估计;以降低成本为目标的最佳集群组合方式的估计。
基本做法:
1)OptEx将spark作业分解成为更小的阶段(包括the initialization phase, the preparation phase, the variable sharing phase, and the computation phase)。模型将执行时间表示为与集群大小、迭代次数、输入大小以及模型参数配置文件的关系。
阶段解释:
initialization phase:执行类加载,symbol table创建,对象初始化,函数加载和记录器logger初始化等活动
preparation phase:作业调度,资源分配和context创建
variable sharing phase:处理从master向workers进行的broadcast或accumulating blocks of data。
2)OptEx将spark程序进行分类,跑一些具有代表性的作业来为每种类别的作业分配一个单独的作业配置文件。而模型的参数设置是来自于作业的配置文件。
3)模型中有一个资源使用成本的目标函数,在满足SLO条件下,要尽可能地通过组合集群去使目标函数最小,从而达到一个成本优化。
那么效果如何呢?
文中验证部分使用了spark PageRank的应用来进行测试。亚马逊提供30节点,Xlarge集群,用户的SLO是70小时,正常跑完后共消耗40小时和168.45美元,在使用了本文模型后,共消耗60小时,84。18美元,可见在满足SLO条件下,成本优化很显著。
4 主要贡献
提出OptEx模型用于对spark运行过程进行建模。
提出一种用于估计集群组合方式来降低成本的策略。
5 OptEx方法介绍
1、OptEx将spark分为上述几个不同的阶段后,将其每个阶段的时间具体化为与集群大小、迭代次数、输入数据大小以及模型参数之间的关系。OptEx参考了ARIA框架的实现原理,该框架是适用于hadoop的调度,OptEx使用与目标作业所属类别相对应的特定作业配置来估计模型参数。
Spark内部使用RDD来基于内存进行迭代,spark内部基于RDD封装了一些库供不同需求的计算任务所使用,例如MLlib、SQL等。对于一个app的计算阶段,将会调用相应的库来进行计算,而计算阶段包含worker间的通信以及变量共享,和RDD的执行计算部分。变量共享阶段与执行计算阶段的长度与输入的变量(集群大小、数据量等)成相关关系,尤其是变量共享和计算阶段会随着迭代而不断重复
2、对于集群组合的优化是通过最小化约束条件的目标函数来实现的,而这个成本目标函数是基于作业执行模型来构建的。
6 用于模型参数估计的profiling
关于这个profiling,我不知道如何简洁的解释,之前看到一篇hadoop性能预测的论文Starfish中这个词用的很多,大致意思就是先跑了很多基准测试,然后记录并寻找到这些基准测试的时间变化统计规律或是资源消耗规律等,用于反推到真实作业下的时间消耗等。
Starfish:《Starfish: A Selftuning System for Big Data Analytics》《Profiling, Whatif Analysis, and Costbased Optimization of MapReduce Programs》《MapReduce Programming and Costbased Optimization Crossing this Chasm with Starfish》
常见的估计给定job性能表现的手段是使用一个标准的配置工具,基于一些基准测试,这个工具能够测量真实的性能表现(例如每个阶段的时间或是资源消耗等)的统计数据,并生利用代表性的基准job来为目标job生成一个profile。OptEx先将作业类型进行分类,然后对于每一类的作业进行一些基准测试并产生相应的profiles。
6.1 应用分类
根据spark自带的几种业务逻辑,本文对spark app进行分类:
1)Spark SQL
2)Spark Streaming
3)MLlib
4)GraphX
6.2 为每一个类选择具有代表性的job
怎样为每一类job分配具有代表性的job呢?文中定义满足以下条件即可:
(我理解的具有代表性的job就是相应的基准测试的app。假设基准测试app用a表示,对应的真实作业用j表示)那么如果:
1)a的RDD包含全部j的RDD
2)j和a都是迭代的或者都不是迭代的
3)使用同一种spark lib提供的业务计算框架
根据以上条件,文中所选取的相应的基准测试案例为:
1)Spark Streaming:the web page of Spark Streaming library,数据集为Twitter dataset
2)MLlib:the movie rating application MovieLensALS
3)GraphX:PageRank
4)Spark SQL:AMPLab研发的Big Data Benchmark
6.3 用profile来估计模型的参数
模型需要一些通过基准测试获得的参数,这些参数都保存在profiles里面,这些参数的含义如下所示:
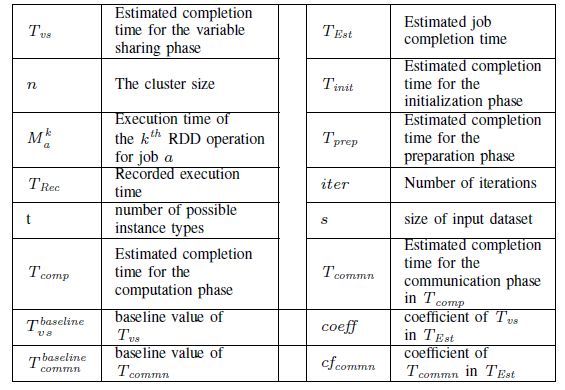
初始化阶段的时间长度额准备阶段的时间长度随着输入变量的额变化而保持不变。执行阶段的时间和变量共享阶段的时间与输入变量呈正相关关系。有这样的关系后,基准测试的profile中的参数值可以被用来作为参考基准,用来估计真实作业中相关阶段的时间长度。
根据以上参数展示以及前面讨论的阶段划分,job的完成时间可表示为如下模型:
profile获取的方式:
profiling时,基准测试的用例在单节点上进行部署和测试,同时,前面提到的四个阶段的时间长度均会被记录在profile中。对于初始化和准备阶段,可以对找到作业类型从profile文件中直接获取这两个阶段的时间。
而变量共享阶段的时间是与集群规模和迭代次数呈正相关的,因此,这个阶段的时间可以表示为:其中n表示节点个数,iter表示迭代次数,coeff表示系数,这个系数是通过不断地基准测试曲线拟合得到的。
计算阶段的时间是由通信阶段时间+执行阶段时间组合而来,通信阶段的时间可用如下表示:
执行阶段是要根据不同类型RDD来进行估计,本文使用包含代表性Spark应用程序a的每个单元RDD任务组件k的平均运行时间来表示。
7 spark job执行模型的推导
7.1 模型输入
模型的输入浚可以由用户很固定地根据job配置而给出:输入数据量、节点个数、app类型。而迭代次数可以从简短的代码中得到。
当对目标job进行建模时,用户给模型输入一个iter的上限,当运行目标job时,用户会给一个iterexec作为迭代次数的参数去运行,而这个两个iter可能会不相同!!不相同的话会导致:1)不可预测的资源消耗;2)无法满足SLO。如果发生这种情况,要重新使用新的参数进行估计。
7.2 模型的公式化
前面表示出了整体job的模型,其中关于执行阶段,我们讨论过,是由每一个RDD来决定的,而RDDtask的数量n是与数据量、迭代次数呈正相关的,因此RDD task的数量n能够表示为:
前面讨论过初始化阶段和准备阶段的时间不随其他因素而变化,因此可以直接用profile中的时间来估计。
变量共享阶段和计算阶段也可由前面提到的两个公式来计算。但是由前面的分析知道,计算阶段可以进一步分解为通信阶段和执行阶段,而执行阶段依赖于1)给定job的RDD集合的运行次数;2)迭代次数iter;3)job的stage个数;4)job的并行度;5)节点间RDD变量的共享,因此执行时间可以表示为一个和的形式:包含j的所有RDD task计算时间之和,如下公式所示:

对于计算阶段的时间估计,考虑到数据是在集群中进行并行处理的,那么需要除以节点个数n,因此计算阶段的时间长度需要重新定义如下:
根据前面的公式推导,上式可以具体化为:

其中:
到这里我们可以结合前面的推导得出目标job的执行时间模型:
其中B等于:
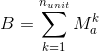
C等于:
8 基于成本优化的集群组合估计
最佳的集群大小的组合用下式表示:其中nt是t类型虚拟机实例的个数,m是所有的虚拟机实例的总个数。

总成本用C表示,用ct表示t类型的单个虚拟机实例的单位小时成本。
基于上述定于,我们可以得到如下成本目标函数:
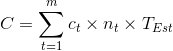
其中Nt为:
关于约束条件,很显然就是用户的SLO,即job时间 1、实验环境以及数据集是需要每次积累和对比的。 我的博客 : https://NingSM.github.io 转载请注明原址,谢谢。
9 实验环境
2、本文实验环境是Spark-1.2.1,部署在6台EC2-8core-15GBRAM-10GBEBS。backend:HDFS
3、供使用了三种算法:MovieLensALS,PageRank,Wordcount
数据集:
MovieLensALS:10-M MovieLens
PageRank:社交网络数据LiveJournal
Wordcount:Wikipedia