Part 20 第二周内容导学
我们继续学习python网络爬虫与信息提取课程。上一周我们讲解了python的request库,学习了自动爬取HTML页面和自动向网络提及请求的方法、讲解了robots协议、以及5个实战的网络爬取例子。
本周我们将继续讲解如何解析HTML页面的基本方法。我们讲解一个python语言里一个非常优秀的第三方库Beautiful Soup以及介绍信息标记和提取的一般方法,最后给出中国大学排名定向爬虫这样一个实例。通过这个实例我们将结合erquest库和Beautiful Soup库讲解从网络中获取信息并提取信息的基本方法。

Part 21 Beautiful Soup库的安装
下面我们介绍Beautiful Soup库的安装。Beautiful Soup也叫美味汤,它是一个非常优秀的python第三方库,他能够对HTML、SML格式进行解析并且提取其中的相关信息。在Beautiful Soup的网站上有这样一段话:Beautiful Soup可以对你提供你给他的任何格式进行相关的爬取,并且可以进行树形解析,这个我们再进行详细介绍。Beautiful Soup的使用原理是它能够把你给他的任何文档当作一锅汤,然后给你煲制这锅汤。
下面我们来安装一下Beautiful Soup库:
首先我们要用管理员权限启动command命令台,
然后我们在命令台上执行pip install Beautiful Soup4,
我们看到库已经下载安装成功。安装之后我么对Beautiful Soup库来个小测,这里面我们使用一个HTML页面地址是
http://python123.io/ws/demo.html

我们用浏览器先打开这个网站看一下:在这个页面中我们看到他有一个标题栏,标题栏上面有一行字叫This is a python demo,这个地方表示的是一个title信息。我们可以将这个文件存取下来,存取成demo.html。或者我们用他的源代码。
我们打开他的源代码,能看到这个页面对应的是一个HTML.5.0格式的页面,在这个代码中我们看到了很多的标签,这种标签以一对、尖括号来表示,如果同学们现在看不太懂这样的内容没有关系,大家记住这个HTML页面是以尖括号为主的标签所封装的信息就可以了。
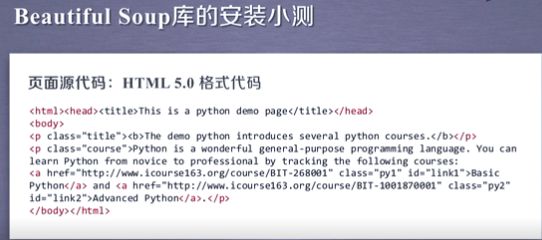
那么,如何获得这样的源代码呢?我们有两种方式:
第一种,我们可以手工获得HTML的代码,首先我们打开浏览器找到刚才的这个页面,

然后我们右键点击“查看源代码”:
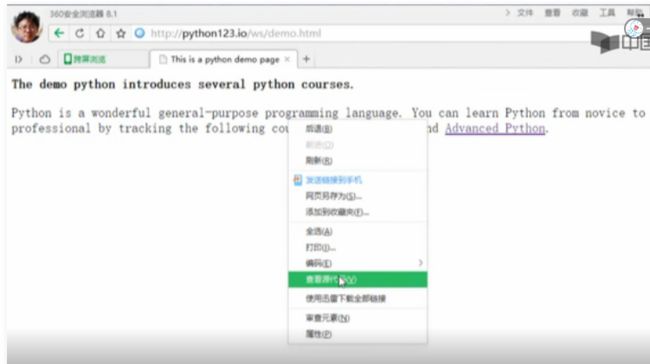
在任何一个浏览器上都有这样的一个功能,之后我们就能看到这个页面的源代码了,

我们可以将这个页面的源代码拷贝下来,并且放到我们的程序里,另外我们上周已经学过了request库,我们可以用request库来自动的获取这个来链接对应的源代码。
下面我们看一下,我们输入import requests,然后我们用get函数来获得这个链接所对应的内容,然后我们显示一下这个文本,我们这个时候看到的就是HTML页面的相关内容。
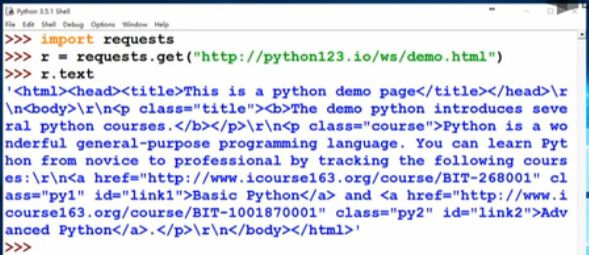
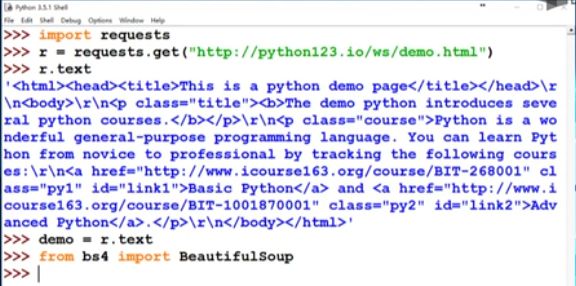
为了简化我们可以定义一个变量叫demo,表示这个页面的所有代码内容。我们给出demo = r.text,后面我们将频繁地使用demo这个变量,请同学们把这段代码看清楚。

下面我们对Beautiful Soup安装进行一个小测。首先我们要导入Beautiful Soup库,我们输入from bs4 import BeautifulSoup4。这里面很有趣,尽管我们安装这个库的时候,我们安装的是Beautiful Soup4,但是我们在使用的时候我们用他的简写bs4,所以我们from bs4这个库的时候我们导入了一个类叫BeautifulSoup。
那下面我们来开始做这锅汤,也就是把这个demo的页面熬制成一个Beautiful Soup能够理解的汤,我们用一个变量叫soup,这里面需要大家注意:我们除了给出demo,同时还要给出解析demo的解释器,这里面我们使用的是html.parser,也就是说我们是对demo进行HTML解析。
那下面我们看看我们的解析是否正确呢?也就是说我们看一下我们安装的库是否正确。我们用print语句将我们做的这锅汤打印出来。我们输入print(soup.prettify()),好我们看到这个页面相关输出了,那说明我们Beautiful Soup库成功的解析了我们给出的demo页面。
那么,怎么使用Beautiful Soup库呢?简单来说,只需要两行代码:

第一行:from bs4 import BeautifulSoup。这里面的BeautifulSoup是一个类,大家记住B和S要大写。
第二行:然后呢,我们需要做一锅汤,那这锅汤呢,我们用一个变量叫soup。当然我们可以用其他的变量,soup = BeautifulSoup()这个类型有两个参数,第一个参数我们需要BeautifulSoup解析的html格式的信息,我们可以用
data来做个代替,我们也可以用任何的变量,同时我们给出一个解析这锅汤时用的解析器,我们这里使用html.parser。只要两行代码我们就可以看到html和sml的信息,是不是很简单呢?
Part 23 Beautiful Soup库的基本元素
下面我们介绍一下BeautifulSoup库的基本元素。理解这些基本元素,是使用BeautifulSoup库的基础。我们知道BeautifulSoup库是能够解析html和sml文件的功能库。那么我们该怎么理解他呢?
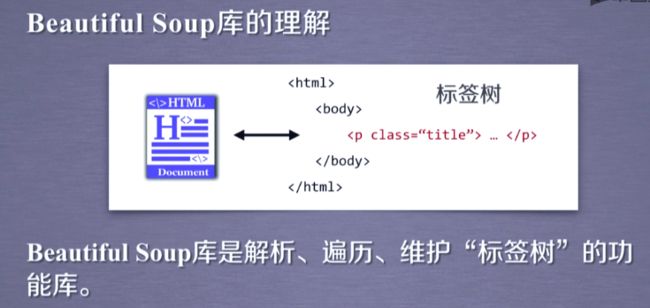
我们以HTML文件为例,任何一个html文件,如果打开他的源代码,我们都能看到它是由一组尖括号构成的标签组织起来的。这里边每一对尖括号形成了一个标签,而标签之间存在一个上下游关系,形成了一个标签树。所以我们可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。只要你提供的文件是标签类型那么Beautiful Soup库都可以对它做很好的解析。
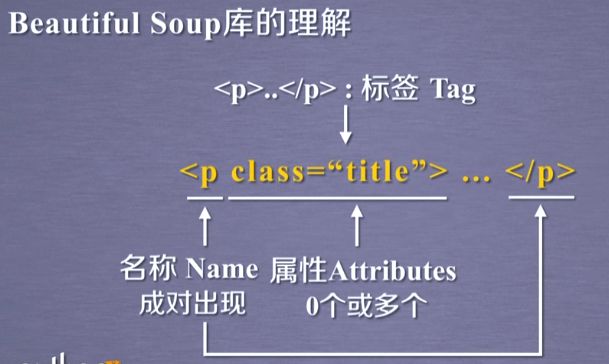
那么我们再看一下每个标签的具体格式:这里面我们以p标签为例:
p标签是以一对尖括号形成的一个标签类型,他的name 是p。那么这里面有一对尖括号和带有一个/的尖括号之间形成的就是一个标签对,英文叫Tag。那么其中的第一个尖括号中的第一个单词p就是这个标签的名称,我们叫name,一般这个标签名称是成对出现的,那么在最开始和最后都出现标明这一个标签的范围。那么在第一对尖括号中除了名字之外,存在这一个相关的域,这个域叫属性域,这里面包含0个或多个属性,那这个属性呢是用来定义这个标签的特点。这里面我们看到一个属性,他叫class,属性的内容是title。那么任何一个属性有它属性的特性和它的值,所以我们叫属性是由键和值,就是键值对构成的。这样的一个格式构成了标签的基本结构。
我们说Beautiful Soup库,也叫beautifulsoup4库或bs4。我们在使用他的时候,需要采用一些引用方式。目前我们最常用的引用方式是from bs4 import BeautifulSoup,这个引用方式说明我们从bs4库中引入了一个类型,这个类型叫BeautifulSoup,这里面还要提醒大家:BeautifulSoup中的B和S要大写。因为python是一个大小写敏感的语言

除了这样的约定引用方式之外,如果我们需要对BeautifulSoup库里面的一些基本的变量进行判断的时候,我们也可以直接引用BeautifulSoup库,使用的是import bs4。那么如何理解BeautifulSoup这个类呢?我们想说BeautifulSoup库本身解析的是html和sml的文档,那么这个文档和标签树是一一对应的。 那么经过了BeautifulSoup库的处理,我们可以使得每一个标签树,大家可以理解为标签树就是一个字符串,我们将这个标签树转换成一个BeautifulSoup类,那么BeautifulSoup类就是能够代表标签树的类型。

事实上,我们认为html文档、标签树、和BeautifulSoup类这三者是等价的。在这个等价的基础上,我们就可以通过BeautifulSoup类使得标签树形成了一个变量,而对这个变量的处理就是对标签树的相关的处理。

这里面我们可以使用几行代码,首先我们from bs4 import BeautifulSoup这个类型,然后可以定义一个变量soup,它等于BeautifulSoup,然后我们给出一个html代码,并且指定它的解析器是html.parser,同时我们也可以通过打开文件的方式来对BeautifulSoup类提供html或sml的文档内容。
简单讲我么可以把内容BeautifulSoup类当作对应HTML/XML文档的全部内容。
之前的例子我们使用了HTML解析器。那么除了HTML解析器,BeautifulSoup库也可以使用四种其他的解析器:

第一种就是我们之前使用过的BeautifulSoup提供的HTML解析器,我们在输入参数的时候输入html.parser,它的使用条件是:只要我们安装了BeautifulSoup库就可以使用。
第二种:接下来我们可以使用lxml的HTML解析器,那我们在使用的时候输入的是lxml这样的一个解析器的标识。为了使用这样的解析器,我们需要在命令行中使用pip install 去安装一个lxml这样的一个库,才能使用这个解析器。
第三种:此外lxml也提供XML解析器,也同样是安装lxml库就可以使用。
第四种:另外还有一个库,叫第三方库叫html5lib。我们可以通过pip install html5lib去安装这样的一个解析器。
事实上,无论哪种解析器他都可以有效的解析html和sml文档的。这里面呢,我们主要使用html解析器,如果大家处理xml文档,或者希望获得更快的性能或者非常准确的xml解析的格式和信息的话,可以使用其他的解析器。
下面我们介绍一下BeautifulSoup类的基本元素:

BeautifulSoup类一共有5种基本元素:
第一种:就是我们之前介绍过的,并且使用过的Tag标签。标签是BeautifulSoup类里面的最基本的信息组织单元,他与html和xml文档中的一对尖括号相对应,它分别是用尖括号和尖括号中带/来标明开头和结尾。
第二种:标签中有名字,也构成了基本元素叫name。那么我们可以用标签.name来获取标签的名字。除了名字之外,标签有属性,它是以字典形式组织的这样一个类型。我们可以用标签.attrs来获得属性的信息。
第三种:此外在标签和尖括号之间,也就是我们所说的省略号的部分。实际上它是一种字符串,我们可以用标签.string来
未待完续。。。。。。