FastQC是一款基于Java的软件,一般都是在linux环境下使用命令行运行,它可以快速多线程地对测序数据进行质量评估(Quality Control),其官网地址为:Babraham Bioinformatics
FastQC的下载和安装,和一般的Java软件没有什么区别,我们在这里就不做介绍了,在成功安装好以后,我们就在命令行模式下,输入fastqc就可以调用这个程序,这时候我们可以选择 --help选项查看帮助文档:
# 基本格式# fastqc [-o output dir] [--(no)extract] [-f fastq|bam|sam] [-c contaminant file] seqfile1 .. seqfileN
# 主要是包括前面的各种选项和最后面的可以加入N个文件
# -o --outdir FastQC生成的报告文件的储存路径,生成的报告的文件名是根据输入来定的
# --extract 生成的报告默认会打包成1个压缩文件,使用这个参数是让程序不打包
# -t --threads 选择程序运行的线程数,每个线程会占用250MB内存,越多越快咯
# -c --contaminants 污染物选项,输入的是一个文件,格式是Name [Tab] Sequence,里面是可能的污染序列,如果有这个选项,FastQC会在计算时候评估污染的情况,并在统计的时候进行分析,一般用不到
# -a --adapters 也是输入一个文件,文件的格式Name [Tab] Sequence,储存的是测序的adpater序列信息,如果不输入,目前版本的FastQC就按照通用引物来评估序列时候有adapter的残留
# -q --quiet 安静运行模式,一般不选这个选项的时候,程序会实时报告运行的状况。
简单使用:
fastqc -o qc -t 10 KPGP-00001_L1_R1.fq.gz
运行一段时间以后,就会在qc文件夹中出现以下报告文件:
KPGP-00001_L1_R1_fastqc.html KPGP-00001_L1_R1_fastqc.zip
使用浏览器打开后缀是html的文件,就是图表化的fastqc报告。
1、Summary

从页面左侧的的summary中可以看出有哪些选项没有通过,上图可以看出此数据的测序质量很好,没有问题。
2、Basic Statics
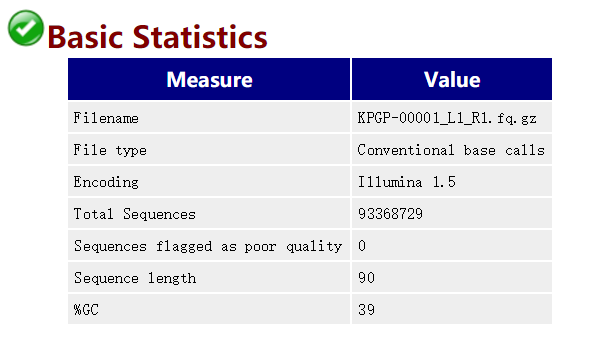
在这里我们可以看出数据的序列数量,测序平台以及GC含量等相关信息。
3、Per base sequence quality
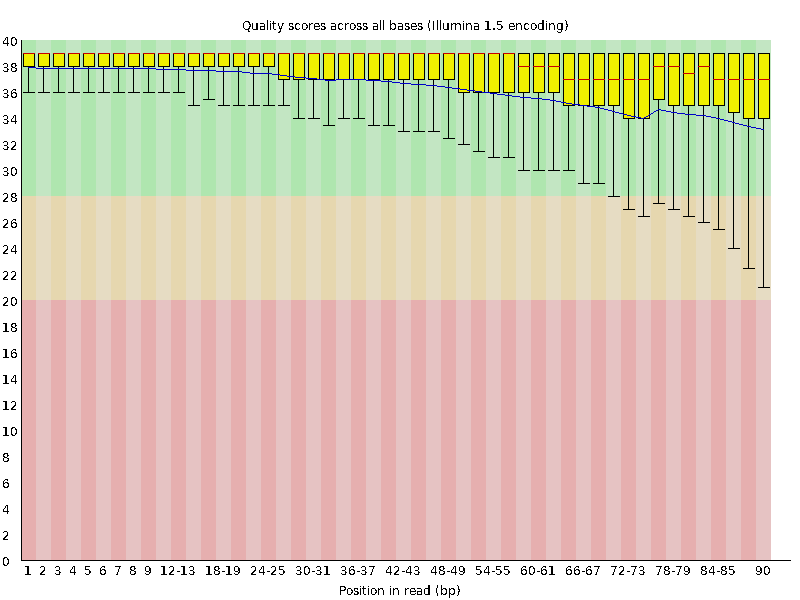
在这个图我们可以看到每个位置的碱基质量情况。
# 此图中的横轴是测序序列第1个碱基到第101个碱基# 纵轴是质量得分,Q = -10*log10(error P)即20表示1%的错误率,30表示0.1%
# 图中每1个boxplot,都是该位置的所有序列的测序质量的一个统计,上面的bar是90%分位数,下面的bar是10%分位数,箱子的中间的横线是50%分位数,箱子的上边是75%分位数,下边是25%分位数
# 图中蓝色的细线是各个位置的平均值的连线# 一般要求此图中,所有位置的10%分位数大于20,也就是我们常说的Q20过滤
# 所以上面的这个测序结果,需要把后面的87bp以后的序列切除,从而保证后续分析的正确性
# Warning 报警 如果任何碱基质量低于10,或者是任何中位数低于25# Failure 报错 如果任何碱基质量低于5,或者是任何中位数低于20
4、Per tile sequence quality
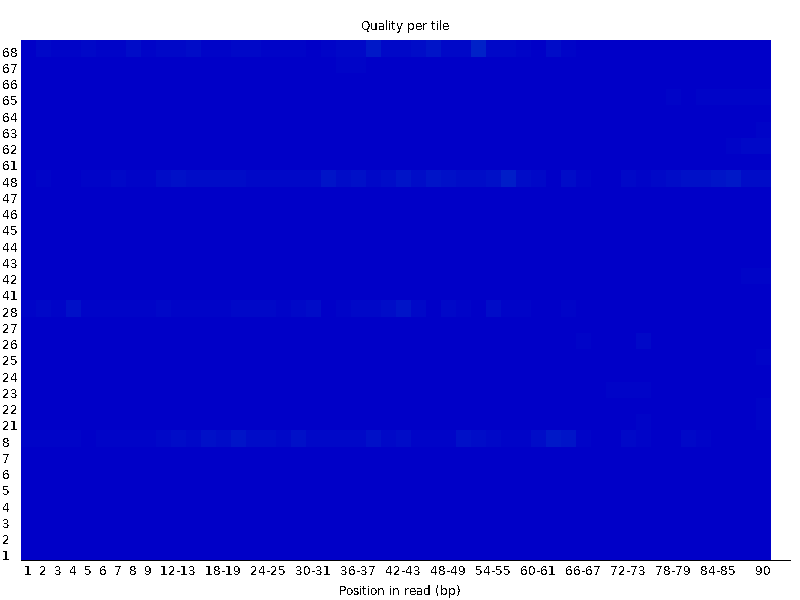
这个图显示了各个tile的序列质量情况
# 横轴和之前一样,代表101个碱基的每个不同位置# 纵轴是tail的Index编号
# 这个图主要是为了防止,在测序过程中,某些tile受到不可控因素的影响而出现测序质量偏低
# 蓝色代表测序质量很高,暖色代表测序质量不高,如果某些tail出现暖色,可以在后续分析中把该tail测序的结果全部都去除
5、Per sequence quality scores
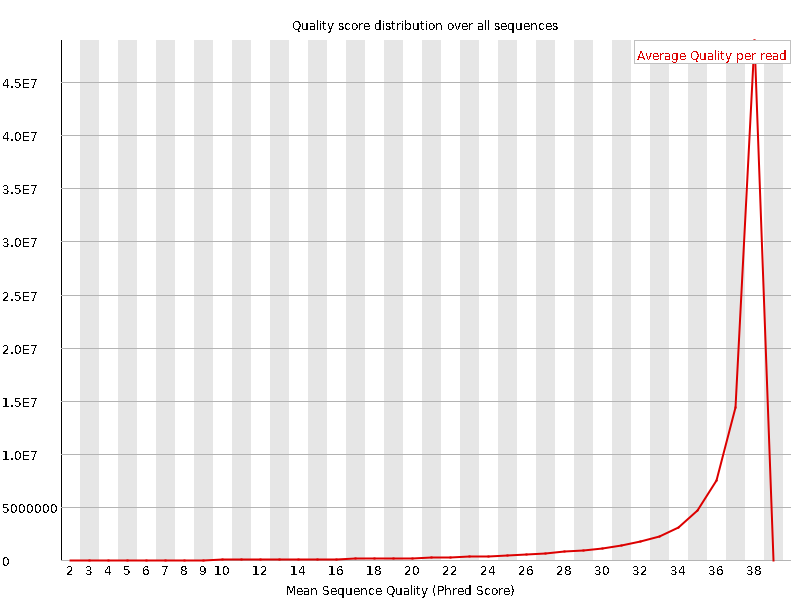
这个图可以看出各个序列质量的分布情况,上图可以看出绝大部分序列质量都在30以上,质量可以说是很好了。
# 假如我测的1条序列长度为101bp,那么这101个位置每个位置Q之的平均值就是这条reads的质量值
# 该图横轴是0-40,表示Q值# 纵轴是每个值对应的reads数目# 我们的数据中,测序结果主要集中在高分中,证明测序质量良好!
6、Per base sequence content
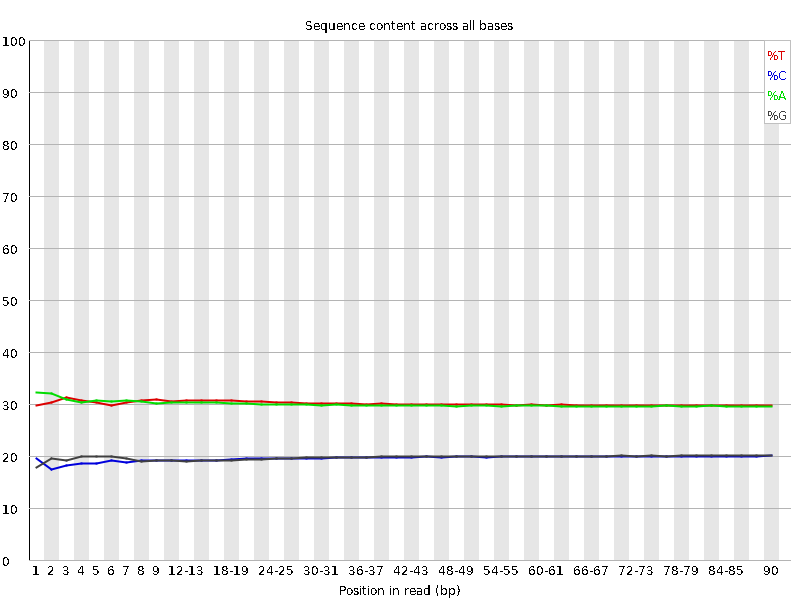
这个图可以看出每条序列中各个位置的平均碱基比例,如出现AT或GC分离的情况说明这个数据有问题,需要处理。
# 横轴是1 - 101 bp;纵轴是百分比
# 图中四条线代表A T C G在每个位置平均含量# 理论上来说,A和T应该相等,G和C应该相等,但是一般测序的时候,刚开始测序仪状态不稳定,很可能出现严重分离的情况。像这种情况,即使测序的得分很高,也需要cut开始部分的序列信息,一般像这种情况,会cut前面5-10bp
7、Per sequence GC content

序列平均GC含量分布图,可以看出在这个fq文件中序列平均GC含量在39%左右。
# 横轴是0 - 100%; 纵轴是每条序列GC含量对应的数量
# 蓝色的线是程序根据经验分布给出的理论值,红色是真实值,两个应该比较接近才比较好
# 当红色的线出现双峰,基本肯定是混入了其他物种的DNA序列
# 这张图中的信息良好
8、Per base N content
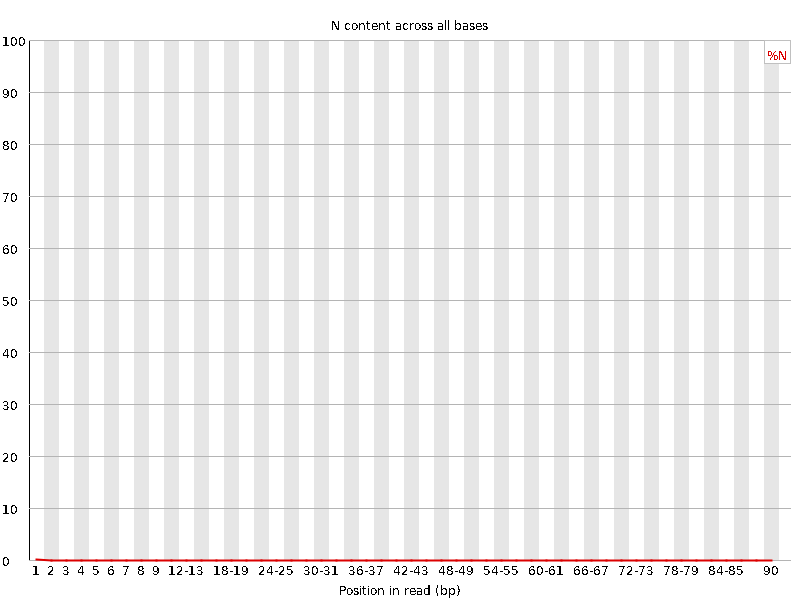
序列中各个位点的N含量,越小越好。
9、Sequence Length Distribution
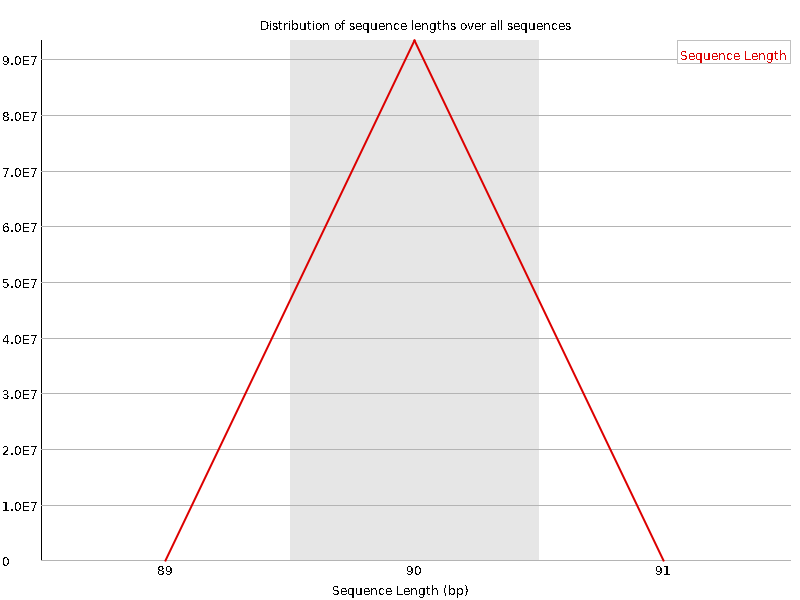
序列测序长度统计,从图中可以看出序列的平均长度为90。
# 每次测序仪测出来的长度在理论上应该是完全相等的,但是总会有一些偏差# 比如此图中,101bp是主要的,但是还是有少量的100和102bp的长度,不过数量比较少,不影响后续分析# 当测序的长度不同时,如果很严重,则表明测序仪在此次测序过程中产生的数据不可信
10、Sequence Duplication Levels

sequences duplication是指在测序前建库PCR过程中导致的一些序列扩增次数过多导致的。若重复较高则需要进行处理这些dup。
11、Overrepresented sequences
如果有某个序列大量出现,就叫做over-represented。fastqc的标准是占全部reads的0.1%以上。为了计算方便,只取了fq数据的前200,000条reads进行统计,所以有可能over-represented reads不在里面。而且大于75bp的reads也是只取50bp。
当发现超过总reads数0.1%的reads时报"黄色!",当发现超过总reads数1%的reads时报"红色×"。
12、Adapter Content
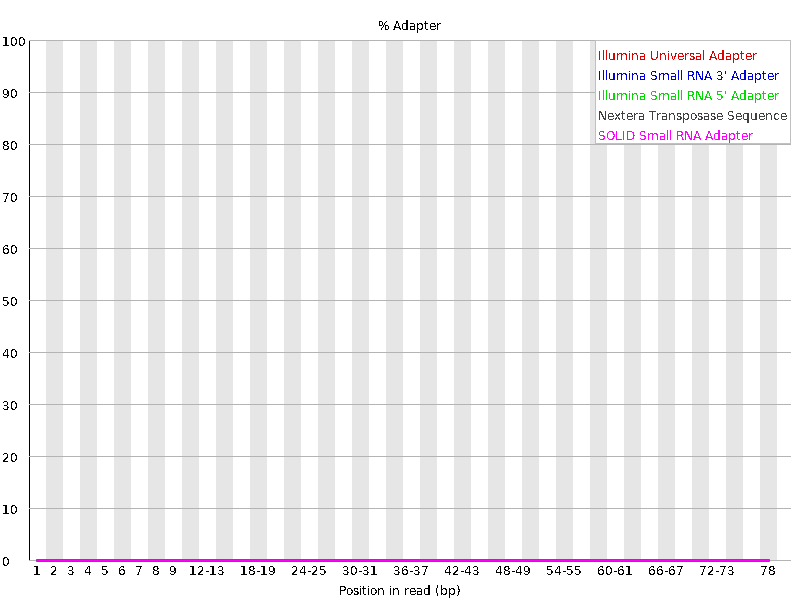
序列Adapter
# 此图衡量的是序列中两端adapter的情况# 如果在当时fastqc分析的时候-a选项没有内容,则默认使用图例中的四种通用adapter序列进行统计
# 本例中adapter都已经去除,如果有adapter序列没有去除干净的情况,在后续分析的时候需要先使用cutadapt软件进行去接头,也可以用 trimmomatic来去除接头
13、Kmer Content
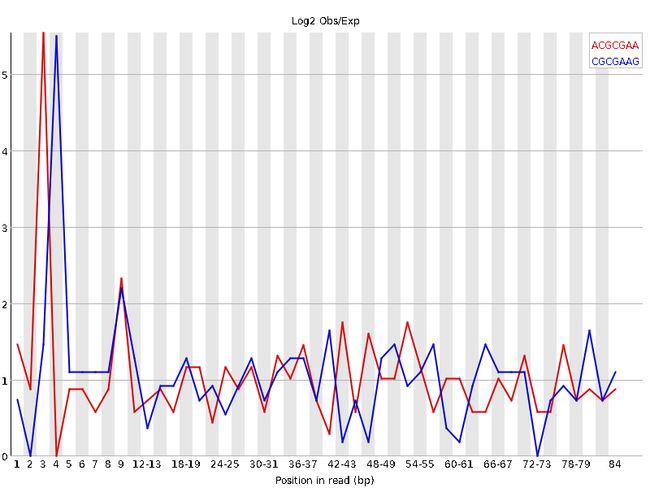
如果某k个bp的短序列在reads中大量出现,其频率高于统计期望的话,fastqc将其记为over-represented k-mer。默认的k = 5,可以用-k --kmers选项来调节,范围是2-10。出现频率总体上3倍于期望或是在某位置上5倍于期望的k-mer被认为是over-represented。fastqc除了列出所有over-represented k-mers,还会把前6个的per base distribution画出来。
当有出现频率总体上3倍于期望或是在某位置上5倍于期望的k-mer时,报"黄色!";当有出现频率在某位置上10倍于期望的k-mer时报"红色×"。本图所显示的结果来自于表格中前六个序列。