RIFF file format
RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构。RIFF文件所包含的数据类型由该文件的扩展名来标识
Chunk
RIFF文件结构可以看作是树状结构,其基本构成是称为"块"(Chunk)的单元,每个块有"标志符"、"数据大小"及"数据"所组成
public static class Chunk {
//4个字节
public String chunkId;
//4个字节。指的是 data的长度
public int dataSize;
public byte[] data;
}
- chunkId
4字节,用以标识块中所包含的数据。如:RIFF,LIST,fmt,data,WAV,AVI等。RIFF文件是按照小端little-endian字节顺序写入的。 - dataSize
存储在data域中的数据长度 - data
包含数据,数据以字为单位存放,如果数据长度为奇数(字节为单位),则最后添加一个空字节。
chunk是可以嵌套的,但是只有块标志为RIFF或者LIST的chunk才能包含其他的chunk。
RIFF chunk
标志为RIFF的chunk是比较特殊的,每一个RIFF文件首先存放的必须是一个RIFF chunk,并且只能有这一个标志为RIFF的chunk。RIFF的数据域的起始位置是一个4字节码(FOURCC),用于标识其数据域中chunk的数据类型;紧接着数据域的内容则是包含的subchunk,如下图

这是一个RIFF chunk中包含有两个subchunk,可以看出RIFF chunk的数据域首先是是4字节的 Form Type,接着是两个subchunk,每一个subchun有包含有自己的标识、数据域的大小以及数据域。
除了RIFF cunk可以嵌套其他的chunk外,另一个可以有subchunk的就是LIST chunk。
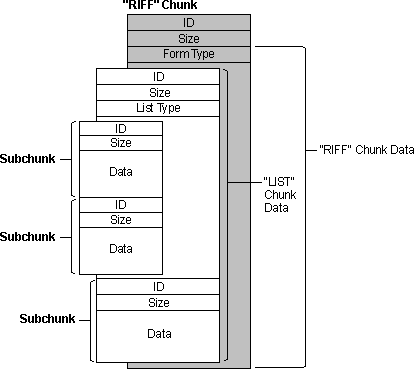
上图中,首先是RIFF文件必须的RIFF chunk,其数据域又包含有两个subchunk,其中一个subchunk的类型为LIST,该LIST chunk又包含了两个subchunk。
FourCC
FourCC 全称为Four-Character Codes,是一个4字节32位的标识符,通常用来标识文件的数据格式。例如,在音视频播放器中,可以通过 文件的FourCC来决定调用那种CODEC进行视音频的解码。例如:DIV3,DIV4,DIVX,H264等,对于音频则有:WAV,MP3等。对于上面的RIFF文件,则有:RIFF,WAVE,fmt,data等。FourCC是4个ASCII字符,不足四个字符的则在最后补充空格(不是空字符)。比如,FourCC fmt,实际上是'f' 'm' 't' ' '。
WAV
WAV 是Microsoft开发的一种音频文件格式,它符合上面提到的RIFF文件格式标准,可以看作是RIFF文件的一个具体实例。既然WAV符合RIFF规范,其基本的组成单元也是chunk。一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk。

一个WAV文件,首先是一个RIFF chunk;RIFF chunk又包含有Format chunk,Data chunk以及可选的Fact chunk。各个chunk中字段的意义如下:
RIFF chunk
| id | size | data |
|---|---|---|
| 'R' 'I' 'F' 'F' | 其data字段中数据的大小 字节数 | 包含其他的chunk |
Format chunk
| id | size | data |
|---|---|---|
| 'f' 'm' 't' ' ' | 见下面Chunk Size | 见下面Chunk Data |
chunk size
数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为= 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0)
chunk Data
存放音频格式、声道数、采样率等信息
- format_tag
2字节,表示音频数据的格式。如值为1,表示使用PCM格式。 - channels
2字节,声道数。值为1则为单声道,为2则是双声道。 - samples_per_sec
采样率,主要有22.05KHz,44.1kHz和48KHz。 - bytes_per sec
音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小 - block_align
数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。 - bits_per_sample
音频sample的量化位数,有16位,24位和32位等。 - cbSize
扩展区的长度
扩展块内容
22字节,具体介绍,后面补充。
- Fact chunk**(option)
| id | size | 采样总数 |
|---|---|---|
| 'f' 'a' 'c' 't' | 数据域的长度,4(最小值为4) | 采样总数 (每个声道) |
采用压缩编码的WAV文件,必须要有Fact chunk,该块中只有一个数据,为每个声道的采样总数。
Data chunk
| id | size | data |
|---|---|---|
| 'd' 'a' 't' 'a' | 数据域的长度 | 具体的音频数据存放在这里 |
补充
Format chunk 中的编码方式
在Format chunk中,除了有音频的数据的采样率、声道等音频的属性外,另一个比较主要的字段就是format_tag,该字段表示音频数据是以何种方式编码存放的。其具体的取值可以为以下:
| 格式代码 | 格式名称 | fmt 块长度 | fact 块 |
|---|---|---|---|
| 1(0x0001) | PCM/非压缩格式 | 16 | |
| 2(0x0002 | Microsoft ADPCM | 18 | √ |
| 3(0x0003) | IEEE float | 18 | √ |
| 6(0x0006) | ITU G.711 a-law | 18 | √ |
| 7(0x0007) | ITU G.711 μ-law | 18 | √ |
| 49(0x0031) | GSM 6.10 | 20 | √ |
| 64(0x0040) | ITU G.721 ADPCM | √ | |
| 65,534(0xFFFE) | 见子格式块中的编码格式 | 40 |
关于扩展格式块
当WAV文件使用的不是PCM编码方式是,就需要扩展格式块,它是在基本的Format chunk又添加一段数据。该数据的前两个字节,表示的扩展块的长度。紧接其后的是扩展的数据区,含有扩展的格式信息,其具体的长度取决于压缩编码的类型。当某种编码方式(如 ITU G.711 a-law)使扩展区的长度为0,扩展区的长度字段还必须保留,只是其值设置为0。
扩展区的各个字节的含义如下:
- size 2字节
扩展区的数据长度 ,可以为0或22 - valid_bits_per_sample 2字节
有效的采样位数,最大值为采样字节数 * 8。可以使用更灵活的量化位数,通常音频sample的量化位数为8的倍数,但是使用了WAVE_FORMAT_EXTENSIBLE时,量化的位数有扩展区中的valid bits per sample来描述,可以小于Format chunk中制定的bits per sample。 - channle mask 4字节
声道掩码 - sub format 16字节
GUID,include the data format code,数据格式码。
在Format chunk中的format_tag设置为0xFFFE时,表示使用扩展区中的sub_format来决定音频的数据的编码方式。在以下几种情况下必须要使用WAVE_FORMAT_EXTENSIBLE
- PCM数据的量化位数大于16
- 音频的采样声道大于2
- 实际的量化位数不是8的倍数
- 存储顺序和播放顺序不一致,需要指定从声道顺序到声卡播放顺序的映射情况。
Data chunk
Data块中存放的是音频的采样数据。每个sample按照采样的时间顺序写入,对于使用多个字节的sample,使用小端模式存放(低位字节存放在低地址,高位字节存放在高地址)。对于多声道的sample采用交叉存放的方式。例如:立体双声道的sample存储顺序为:声道1的第一个sample,声道2的第一个sample;声道1的第二个sample,声道2的第二个sample;依次类推....。对于PCM数据,有以下两种的存储方式:
- 单声道,量化位数为8,使用偏移二进制码
- 除上面之外的,使用补码方式存储。
实例分析
普通的WAV

RIFF块
由上面的介绍可知,由RIFF格式固定的。包括RIFF、Size和FOURCC
-
RIFF
 RIFF.png
RIFF.png -
Size
 Size.png
Size.png
因为是小端的顺序。实际上的十六进制数应该是 “00077090”,转为487568。这个数值+8,就是文件的长度。
-
WAVE
 WAVE.png
WAVE.png
Format chunk
-
ChunkId
"fmt "。和上面标识的一样。是4个字节,不足补“ ”
 image.png
image.png -
Chunk Size
 image.png
image.png
因为是小端的顺序。实际上的十六进制数应该是 “00000010”,为16。就是后续的Data的长度。
-
Chunk Data
fmt chunk中的chunk data就是包含有该视频的信息。
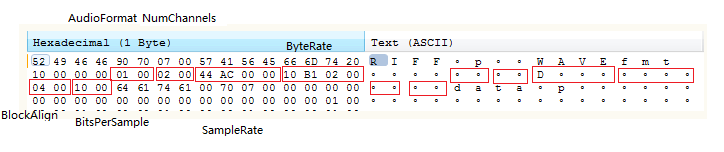 Chunk Data.png
Chunk Data.png
| 名称 | 偏移地址 | 字节数 | 端序 | 内容 | 当前值 |
|---|---|---|---|---|---|
| AudioFormat | 0x08 | 2Byte | 小端 | 音频格式 | 1,PCM音频数据的值为1。则当前没有Fact chunk |
| NumChannels | 0x0A | 2Byte | 小端 | 声道数 | 2,表示音频数据的声道数,1:单声道,2:双声道。 |
| SampleRate | 0x0C | 4Byte | 小端 | 采样率 | 44100 |
| ByteRate | 0x10 | 4Byte | 小端 | 每秒数据字节数 | 176400。SampleRate * NumChannels * BitsPerSample / 8 |
| BlockAlign | 0x14 | 2Byte | 小端 | 数据块对齐 | 4。NumChannels * BitsPerSample / 8 |
| BitsPerSample | 0x16 | 2Byte | 小端 | 采样位数 | 采样深度16bit。8:8bit,16:16bit,32:32bit |
Data
因为是PCM的数据格式,所以直接就到了data
-
标识'data'
 data.png
data.png - 音频数据的长度
Size
 Size.png
Size.png
| 名称 | 偏移地址 | 字节数 | 端序 | 内容 | 当前值 |
|---|---|---|---|---|---|
| ID | 0x00 | 4Byte | 大端 | 'data' (0x64617461) | “0x77000”,转为十进制为 487424 。 |
| Size | 0x04 | 4Byte | 小端 | N | 等于 ByteRate * seconds ,约为2.7秒。 |
| Data | 0x08 | NByte | 小端 | 音频数据 | ... |
总结
- 头部大小
通常的WAV,以PCM为数据格式的,基本上头部就如上面的结构。头部的SIZE为固定的44,
通常对WAV音频进行处理时,会直接写死这个头部的Offset。
排查一次WAV处理中的杂音情况
但是在实际处理的过程中,遇到了下面这样的WAV HEADER。头部的长度不同,导致后续的音频处理中出现了杂音的情况。排查之后,才发现是因为头部大小不同导致。
特殊一点的WAV
由Adobe Premiere Pro CC 创建的WAV。
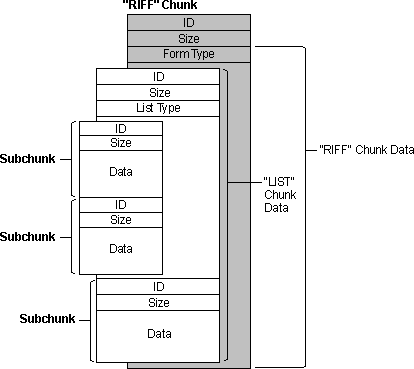
它包含有
LIST Chunk。而且
fmt chunk的size为18。
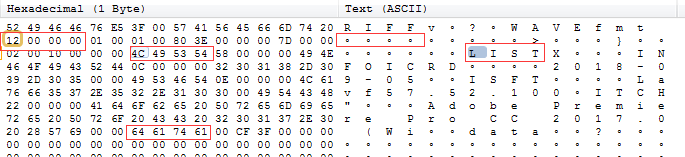
因为有LIST,导致上面通常写死的HEAD_SIZE 44出现错误。
这个时候重新去计算这个HEAD_SIZE就可以了。
LIST CHUNK
- CHUNK ID
CHUNK ID为“LIST” - CHUNK SIZE
可以看到为0x58,十进制为88。
计算HEAD_SIZE
private static int getHeadSize(RandomAccessFile srcFis) throws IOException {
int offset = 0;
//riff
getChunkId(srcFis);
offset += 4;
//length
getChunkSize(srcFis);
offset += 4;
//wave
getChunkId(srcFis);
offset += 4;
//fmt
getChunkId(srcFis);
offset += 4;
//fmt length
int skipLength = getChunkSize(srcFis);
offset += 4;
byte[] skipBytes = new byte[skipLength];
srcFis.read(skipBytes);
offset += skipLength;
String chunkId = getChunkId(srcFis);
offset += 4;
while (!chunkId.equals("data")) {
skipLength = getChunkSize(srcFis);
offset += 4;
skipBytes = new byte[skipLength];
srcFis.read(skipBytes);
offset += skipLength;
chunkId = getChunkId(srcFis);
offset += 4;
}
offset += 4;
System.out.println("headSize="+offset);
return offset;
}
private static int getChunkSize(RandomAccessFile srcFis) throws IOException {
byte[] formatSize = new byte[4];
srcFis.read(formatSize);
int fisrt8 = formatSize[0] & 0xFF;
int fisrt16 = formatSize[1] & 0xFF;
int fisrt24 = formatSize[2] & 0xFF;
int fisrt32 = formatSize[3] & 0xFF;
int chunkSize = fisrt8 | (fisrt16 << 8) | (fisrt24 << 16) | (fisrt32 << 24);
System.out.println("ChunkSize=" + chunkSize);
return chunkSize;
}
private static String getChunkId(RandomAccessFile srcFis) throws IOException {
byte[] bytes = new byte[4];
srcFis.read(bytes);
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < bytes.length; i++) {
stringBuilder.append((char) bytes[i]);
}
String chunkId = stringBuilder.toString();
System.out.println("ChunkId=" + chunkId);
return chunkId;
}
只有这样计算出的HEAD_SIZE才能正确的处理文件,避免因为这个原因导致的杂音。
WAV一些处理
获取wave文件某个时间对应的数据位置
private static int getPositionFromWave(float time, int sampleRate, int channels, int bitNum) {
int byteNum = bitNum / 8;
//时间* 每秒数据字节数= 当前时间的字节数
int position = (int) (time * sampleRate * channels * byteNum);
//当前时间的字节数 / 每个采样所需的字节数 * 当前时间的字节数 来进行取整。定位到一个完整的采样的起点
position = position / (byteNum * channels) * (byteNum * channels);
return position;
}
- 当前时间的字节数
sampleRate * channels * byteNum - 定位到完整的采样时间的起点
position = position / (byteNum * channels) * (byteNum * channels);
剪切音频
剪切音频的流程很简单
- 计算两个采样点的位置。偏移头部的大小,复制两个采样点之间的数据。
- 重新写入修改之后的头部。因为数据长度修改。里面的
RIFF块ChunkSize和data块的长度由当前的长度做对应修改。
public static void cutAudio(Audio audio, Audio audioOut, float cutStartTime, float cutEndTime) {
if (cutStartTime == 0 && cutEndTime == audio.getTimeMillis() / 1000f) {
return;
}
if (cutStartTime >= cutEndTime) {
return;
}
String srcWavePath = audio.getPath();
int sampleRate = audio.getSampleRate();
int channels = audio.getChannel();
int bitNum = audio.getBitNum();
RandomAccessFile srcFis = null;
RandomAccessFile newFos = null;
String tempOutPath = srcWavePath + ".temp";
try {
//创建输入流
srcFis = new RandomAccessFile(srcWavePath, "rw");
newFos = new RandomAccessFile(tempOutPath, "rw");
//源文件开始读取位置,结束读取文件,读取数据的大小
final int cutStartPos = getPositionFromWave(cutStartTime, sampleRate, channels, bitNum);
final int cutEndPos = getPositionFromWave(cutEndTime, sampleRate, channels, bitNum);
final int contentSize = cutEndPos - cutStartPos;
//复制wav head 字节数据
byte[] headerData = AudioEncodeUtil.getWaveHeader(contentSize, sampleRate, channels, bitNum);
copyHeadData(headerData, newFos);
//取到正确头部偏移
int srcHeadSize = getHeadSize(srcFis);
//移动到文件开始读取处
srcFis.seek(srcHeadSize + cutStartPos);
//复制裁剪的音频数据
copyData(srcFis, newFos, contentSize);
} catch (Exception e) {
e.printStackTrace();
return;
} finally {
//关闭输入流
if (srcFis != null) {
try {
srcFis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (newFos != null) {
try {
newFos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//重命名为源文件
FileUtil.renameFile(new File(tempOutPath), audioOut.getPath());
}
public static byte[] getWaveHeader(long totalAudioLen, int sampleRate, int channels, int bitNum) throws IOException {
//总大小,由于不包括RIFF和WAV,所以是44 - 8 = 36,在加上PCM文件大小
long totalDataLen = totalAudioLen + 36;
//采样字节byte率
long byteRate = sampleRate * channels * bitNum / 8;
byte[] header = new byte[44];
header[0] = 'R'; // RIFF
header[1] = 'I';
header[2] = 'F';
header[3] = 'F';
header[4] = (byte) (totalDataLen & 0xff);//数据大小
header[5] = (byte) ((totalDataLen >> 8) & 0xff);
header[6] = (byte) ((totalDataLen >> 16) & 0xff);
header[7] = (byte) ((totalDataLen >> 24) & 0xff);
header[8] = 'W';//WAVE
header[9] = 'A';
header[10] = 'V';
header[11] = 'E';
//FMT Chunk
header[12] = 'f'; // 'fmt '
header[13] = 'm';
header[14] = 't';
header[15] = ' ';//过渡字节
//数据大小
header[16] = 16; // 4 bytes: size of 'fmt ' chunk
header[17] = 0;
header[18] = 0;
header[19] = 0;
//编码方式 10H为PCM编码格式
header[20] = 1; // format = 1
header[21] = 0;
//通道数
header[22] = (byte) channels;
header[23] = 0;
//采样率,每个通道的播放速度
header[24] = (byte) (sampleRate & 0xff);
header[25] = (byte) ((sampleRate >> 8) & 0xff);
header[26] = (byte) ((sampleRate >> 16) & 0xff);
header[27] = (byte) ((sampleRate >> 24) & 0xff);
//音频数据传送速率,采样率*通道数*采样深度/8
header[28] = (byte) (byteRate & 0xff);
header[29] = (byte) ((byteRate >> 8) & 0xff);
header[30] = (byte) ((byteRate >> 16) & 0xff);
header[31] = (byte) ((byteRate >> 24) & 0xff);
// 确定系统一次要处理多少个这样字节的数据,确定缓冲区,通道数*采样位数
header[32] = (byte) (channels * 16 / 8);
header[33] = 0;
//每个样本的数据位数
header[34] = 16;
header[35] = 0;
//Data chunk
header[36] = 'd';//data
header[37] = 'a';
header[38] = 't';
header[39] = 'a';
header[40] = (byte) (totalAudioLen & 0xff);
header[41] = (byte) ((totalAudioLen >> 8) & 0xff);
header[42] = (byte) ((totalAudioLen >> 16) & 0xff);
header[43] = (byte) ((totalAudioLen >> 24) & 0xff);
return header;
}
替换和插入音频
- 计算两个采样点的位置。偏移头部的大小,讲两个采样点之间的数据,替换成想要的音频。
- 重新写入修改之后的头部。因为数据长度修改。里面的
RIFF块ChunkSize和data块的长度由当前的长度做对应修改。
public static void replaceAudioWithSame(Audio srcAudio, Audio coverAudio, Audio outAudio, float srcStartTime) {
String srcWavePath = srcAudio.getPath();
String coverWavePath = coverAudio.getPath();
int sampleRate = srcAudio.getSampleRate();
int channels = srcAudio.getChannel();
int bitNum = srcAudio.getBitNum();
RandomAccessFile srcFis = null;
RandomAccessFile coverFis = null;
RandomAccessFile newFos = null;
String tempOutPcmPath = srcWavePath + ".tempPcm";
try {
//创建输入流
srcFis = new RandomAccessFile(srcWavePath, "rw");
coverFis = new RandomAccessFile(coverWavePath, "rw");
newFos = new RandomAccessFile(tempOutPcmPath, "rw");
int srcHeadSize = getHeadSize(srcFis);
int coverHeadSize = getHeadSize(coverFis);
final int srcStartPos = getPositionFromWave(srcStartTime, sampleRate, channels, bitNum);
final int coverStartPos = 0;
final int coverEndPos = (int) coverFis.length() - coverHeadSize;
//复制源音频srcStartTime时间之前的数据
//跳过头文件数据
srcFis.seek(srcHeadSize);
copyData(srcFis, newFos, srcStartPos);
//复制覆盖音频指定时间段的数据
//跳过指定位置数据
coverFis.seek(coverHeadSize + coverStartPos);
int copyCoverSize = coverEndPos - coverStartPos;
float volume = coverAudio.getVolume();
copyData(coverFis, newFos, copyCoverSize);
//复制srcStartTime时间后的源文件数据
final int srcStartAddCoverPosition = getPositionFromWave(srcStartTime + ((float) coverAudio.getTimeMillis()) / 1000, sampleRate, channels, bitNum);
final long srcFileSize = srcFis.length() - srcHeadSize;
int remainSize = (int) (srcFileSize - srcStartAddCoverPosition);
if (remainSize > 0) {
// coverFis.seek(WAVE_HEAD_SIZE + coverStartPos);
srcFis.seek(srcHeadSize + srcStartAddCoverPosition);
copyData(srcFis, newFos, remainSize);
}
} catch (Exception e) {
e.printStackTrace();
return;
} finally {
//关闭输入流
if (srcFis != null) {
try {
srcFis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (coverFis != null) {
try {
coverFis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (newFos != null) {
try {
newFos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 删除源文件,
// new File(srcWavePath).delete();
// 转换临时文件为源文件
AudioEncodeUtil.convertPcm2Wav(tempOutPcmPath, outAudio.getPath(), sampleRate, channels, bitNum);
//删除临时文件
new File(tempOutPcmPath).delete();
}
参考
RIFF和WAVE音频文件格式
WAV文件格式详解
wav文件格式分析与详解