Tensorflow使用数据流图dataflow graph表示各个独立操作之间的依赖关系。
Tensorflow低级编程模式:
- 定义dataflow graph
- 创建会话session
- 使用session在本地或远程设备运行graph
什么事Dataflow graphs?
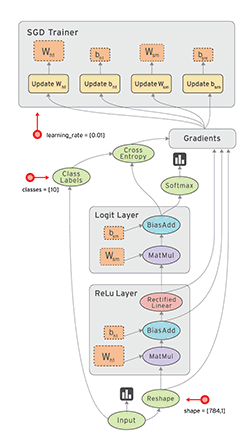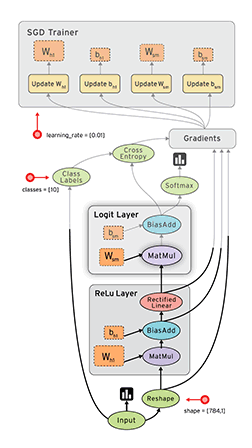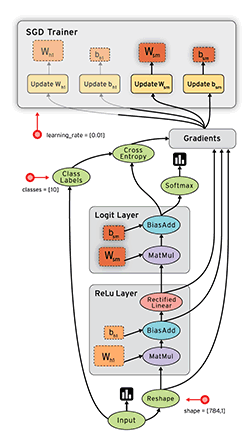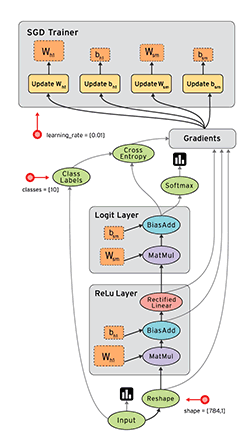
Dataflow是平行计算的通用模式。其中节点node表示计算单元,边线edge表示计算产生和消耗的数据。例如上图地步的MatMul计算节点,有两条数据输入边线和一条向上的输出边线,对应tf.matmul(a,b)方法输出矩阵a和b相乘的结果。
Dataflow graph的优势:
- 平行结构Parallelism。
- 分布式计算Distributed execution。Tensorflow可以协调多设备多机器运算。
- 可编译Compilation。XLA compiler可以利用数据流的关系产生高效率代码,融合相邻运算。
- 可移植Portability。不依赖编程语言存在,可以多语言结合。
什么是tf.graph?
它包含了两类相关信息:
图结构Graph structure。节点和边线表示了各个操作之间的关系,但并不限定如何被使用。图结构类似组装代码:从它可以看到很多关系信息,但并不是实际代码。
图集合Graph collections。Tensorflow提供了一种生成机制,用来存储图中的元数据matadata。
tf.add_to_collection可以将一个列表对象组装到一个键key(由tf.GraphKeys定义)。例如,当我们使用tf.variable创建一个变量的时候,它被添加到表示全局变量global variables和可训练变量trainabled
varibale两个集合,当稍后再创建其他tf.train.Saver、tf.train.Optimizer的时候,集合中的这些变量将作为默认参数使用。
创建一个tf.graph
大多数Tensorflow程序开始于图的创建。我们使用tf.oparation创建操作节点,使用tf.Tensor创建张量边线,然后把它们添加到tf.graph。
Tensorflow提供了一个默认图,作为一个显式的参数,作用于同一个上下文环境的接口函数。例如:
-
tf.constant(42.0),这将创建一个产生42.0的操作tf.operation,并添加到默认图,并返回一个表示常数的张量tf.tensor。
*tf.matmul(x,y),就是把xy两个张量相乘的操作,自动添加到默认图,返回相乘的结果(也是个张量)。
*v=tf.Variable(0),向默认图添加了一个操作,这个操作能够存储一个在会话多次运行之间session.run可读写的张量值。tf.Variable对象包裹着这个操作,使它可以像普通张量一样被读写使用。tf.Variable对象自身也附带了一些方法比如assign,assign_add,这些方法也能生成新的操作,通过这些操作在运算时候改变存储的张量。
-
tf.train.Optimizer.minimize,将添加操作和张量到默认图,它们用来计算梯度gradient并返回一个操作,当被运行的时候,这个操作将把梯度变化应用到变量集合上。
绝大多数程序只要解算默认图就可以了。类似tf.estimator.Estimator接口管理着默认图,当然也会为训练和评价创建不同的图。
Tensorflow大部分API接口都只是创建operation和tensor,并不真正执行运算。你编织整个图谱网络,直到找到那个最终结果或可以得到期望最后结果的操作,然后把它传递到session会话进行求解。
为操作命名
Graph为所有包含的操作定义了一个命名空间。在图中,Tensorflow为每一个操作自动设定了唯一的名称,这个名称与编程中的命名无关。有两个方法覆盖这个自动的命名:
每个创建新操作或者返回新张量的的函数都接受name参数。例如
tf.constant(42.0, name="answer")就会创建一个名叫answer的操作,并返回一个名叫answer:0的张量,如果默认图已经存在同名操作,那么新操作就会被自动添加_1,_2这样的结尾。tf.name_scope方法可以针对一个上下文环境添为特定范围内的操作都添加名称前缀。/斜杠用来划分name_scope的层级,如果已有同名,则自动添加_1,_2。
c_0 = tf.constant(0, name="c") # 得到名称为c的操作
c_1 = tf.constant(2, name="c") # 重名!得到名称为c_1的操作
#外层的命名空间.
with tf.name_scope("outer"):
c_2 = tf.constant(2, name="c") #outer/c
with tf.name_scope("inner"): #嵌套的命名空间
c_3 = tf.constant(3, name="c") #outer/inner/c
c_4 = tf.constant(4, name="c") #重名!变为outer/c_1
with tf.name_scope("inner"):
c_5 = tf.constant(5, name="c") #重名!变为outer/inner_1/c
tf.Tensor对象命名规则是在产生它的操作名称后面加冒号加数字,例如上面提到的answer操作产生的张量命名是answer:0。
将操作放置到不同设备
tf.device()方法可以把同一个上下文中产生的各种操作分不到不同的设备中使用。
设备参数格式:
/job:
- JOB_NAME,非数字开头字母数字组成的字符串
- DEVICE_TYPE,设备类型,GPU或CPU
- TASK_INDEX,工作中的任务序号
- DEVICE_TYPE,设备序号
# 这里创建的操作自动选择,优先GPU
weights = tf.random_normal(...)
with tf.device("/device:CPU:0"):
#这里创建的操作将使用CPU
img = tf.decode_jpeg(tf.read_file("img.jpg"))
with tf.device("/device:GPU:0"):
#这里创建的操作将使用GPU.
result = tf.matmul(weights, img)
paramaters server(ps)参数服务器格式/job:ps,worker工作机格式/job:worker
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(tf.truncated_normal([784, 100]))
biases_1 = tf.Variable(tf.zeroes([100]))
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(tf.truncated_normal([100, 10]))
biases_2 = tf.Variable(tf.zeroes([10]))
with tf.device("/job:worker"):
layer_1 = tf.matmul(train_batch, weights_1) + biases_1
layer_2 = tf.matmul(train_batch, weights_2) + biases_2
使用tf.train.replica_device_setter自动分配:
with tf.device(tf.train.replica_device_setter(ps_tasks=3)):
# tf.Variable objects对象会被自动循环分配任务
w_0 = tf.Variable(...) # placed on "/job:ps/task:0"
b_0 = tf.Variable(...) # placed on "/job:ps/task:1"
w_1 = tf.Variable(...) # placed on "/job:ps/task:2"
b_1 = tf.Variable(...) # placed on "/job:ps/task:0"
input_data = tf.placeholder(tf.float32) # placed on "/job:worker"
layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker"
layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker"
类似张量对象Tensor-like objects
类似张量对象可以被隐式的转化为张量,它分为下面几种:
tf.Tensortf.variablenumpy.ndarray- list(和由类似张量物体构成的list)
- Python标量值:bool,string,int,float
注意,在使用类似张量对象的时候,tensorflow每次都创建新的
tf.tensor对象,如果这个对象很大,那么多次创建会消耗大量内存。
使用tf.Session对图进行计算
Tensorflow使用会话tf.Session来建立客户端程序(Python或其他语言编写的程序)与C++运行时之间的关系。tf.Session提供了访问本机和分布式机器的能力,并能缓存图graph的信息以便于多次运行。
创建会话
# 创建默认的进程内in-process会话.
with tf.Session() as sess:
# ...
# 创建远程会话
with tf.Session("grpc://example.org:2222"):
# ...
由于session拥有物理资源(如GPU和网络链接),所以它只管理自己的代码块的内容,退出代码块就会关闭。如果没有使用代码块,那么必须显式的关闭它tf.Session.close()。
Hight-level Api比如
tf.estimator.Estimator将会自动管理session,可以通过target或config参数对session进行设置。
tf.Session.init包含三个参数:
- 目标target。如果为空,会话只使用本机。可以使用
grpc://URL指定Tensorflow服务器,会话将可以使用该服务器控制的全部机器的全部设备。 - 图graph。默认一个新的会话将绑定到默认图,如果你的程序使用了多个图,那么可以用它显式的指定。
- 设置config。设定一个
tf.ConfigProto控制会话动作。它包含了一些设置比如: - allow_soft_placement,使用软件设备soft device,这将忽略GPU,只用CPU。
- cluster_def,当使用分布式的TensorFlow的时候,这个参数可以设定具体使用哪些机器进行计算。
- graph_options.optimizer_options,在图运算之前,控制优化器。
- gpu_options.allow_growth,设置gpu内存分配器可以梯度增加内存而不是初始占用很多。
使用tf.Session.run执行操作
run方法是对图进行运算的最主要的方法,接受一个或多个提取器fetches列表。提取器可以是:
- 一个操作operation
- 一个张量tensor
- 一个类似张量如tf.Variable
这些提取器限定了一个可被运行的子图subgraph,连接到全图的所有相关操作。
import tensorflow as tf
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
output = tf.nn.softmax(y)
init_op = w.initializer
with tf.Session() as sess:
sess.run(init_op)
print(sess.run(output))
y_val, output_val = sess.run([y, output])
print(y_val)
print(output_val)
Session.run接收feed_dic参数,一般是placeholder表示的值(scalar、list、numpy array),这些值在被计算的时候替换placeholder表示的张量,如下
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x) #这里使用了替代品张量
with tf.Session() as sess:
print(sess.run(y, {x: [1.0, 2.0, 3.0]})) # => "[1.0, 4.0, 9.0]"
print(sess.run(y, feed_dict={x: [0.0, 0.0, 5.0]})) # => "[0.0, 0.0, 25.0]"
sess.run(y) #出错!placeholder必须带有feed_dict
sess.run(y, {x: 37.0}) #出错,数值形状与placeholder不匹配
Session.run接收一个RunOptions参数,可以用来收集运算过程中的信息。这些信息可以用来构建类似Tensorboard的信息图谱。
import tensorflow as tf
y = tf.matmul([[37.0, -23.0], [1.0, 4.0]], tf.random_uniform([2, 2]))
with tf.Session() as sess:
#定义选项
options = tf.RunOptions()
options.output_partition_graphs = True
options.trace_level = tf.RunOptions.FULL_TRACE
#定义元数据容器
metadata = tf.RunMetadata()
sess.run(y, options=options, run_metadata=metadata)
# 打印每个设备上执行的子图结构.
print(metadata.partition_graphs)
# 打印每个操作执行时候的时间.
print(metadata.step_stats)
视觉化计算图
Tensorborad的Graph visualizer元件可以将计算图的结构渲染到浏览器内,只要在创建图的时候把tf.graph对象传递给tf.summary.FileWriter:
import tensorflow as tf
import os
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x)
dir_path = os.path.dirname(os.path.realpath(__file__))
sum_path=os.path.join(dir_path,'temp') #不要使用斜杠
with tf.Session() as sess:
writer = tf.summary.FileWriter(sum_path, sess.graph)
print(sess.run(y, {x: [1.0, 2.0, 3.0]})) # => "[1.0, 4.0, 9.0]"
writer.close()
然后命令行运行tensorboard --logdir=~/desktop/Myprojects/xxx/xxx/,再打开任意浏览器访问http://localhost:6006,点击GRAPHS按钮即可看到类似下图:
使用多个计算图编程
当训练模型的时候,通常使用不同的图进行训练、评价和预测。你可以使用不同的Python进程来创建和运行不同的图,也可以在统一进程内处理。
TensorFlow提供了默认的graph图:
-
tf.graph定义了其下所有操作的命名空间,单个图内的每个操作必须具有唯一命名,重名会自动添加'_1','_2'后缀。 - 默认图自动存储每个添加进来的fetches提取器信息(operation、tensor等),如果你的图包含了大数量节点的未连接子图,最好的办法是将它们分成不同的图,以便于更有效的资源回收。
也可以使用自定义的tf.graph来替代默认图,使用tf.graph.as_default语法,以下实例代码创建了两个session分别运行两个不同的图:
import tensorflow as tf
g_1 = tf.Graph()
with g_1.as_default():#以下操作将被添加到`g_1`.
c = tf.constant("Node in g_1")
# 这里创建的回话将运行`g_1`.
sess_1 = tf.Session()
print(sess_1.run(c))
g_2 = tf.Graph()
with g_2.as_default():#以下操作将被添加到`g_2`.
d = tf.constant("Node in g_2")
#也可以直接为session指定graph
sess_2 = tf.Session(graph=g_2)
print(sess_2.run(d))
以上代码输出
b'Node in g_1'
b'Node in g_2'
使用tf.get_default_graph获取计算图
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x)
g = tf.get_default_graph()
print(g.get_operations())
本篇小结
- Dataflow graph数据流图表,由节点node和边线edge组成。
- tf.graph包含了节点直接的操作关系
- 创建的各种节点和张量都会被自动添加到默认图
- name参数让每个操作都有唯一的识别名,产生的每个张量也都有唯一识别名
- 在不同设备和不同机器上分布操作
- Tensor-like objects类似张量对象
- tf.Session会话对图进行计算
- session的创建和初始化
- tf.Session.run方法运行整图或子图
- 利用Tensorboard视觉化计算图
- 使用多个计算图
探索人工智能的新边界
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,感谢转发~
END