分成7步对 Lidar 的流程进行叙述:
1.坐标及格式转换
Apollo 使用了开源库 Eigen 进行高效的矩阵计算,使用了 PCL 点云库对点云进行处理。
该部分中,Apollo 首先计算转换矩阵 velodyne_trans,用于将 Velodyne 坐标转化为世界坐标。之后将 Velodyne 点云转为 PCL 点云库格式,便于之后的计算。
2.获取ROI区域
核心函数位置: obstacle/onboard/hdmap_input.cc
bool HDMapInput::GetROI(const PointD& pointd, const double& map_radius,
HdmapStructPtr* mapptr);
查询 HDmap, 根据 Velodyne 的世界坐标以及预设的半径 (FLAG_map_radius) 来获取 ROI 区域。
首先获取指定范围内的道路以及道路交叉点的边界,将两者进行融合后的结果存入 ROI 多边形中。该区域中所有的点都位于世界坐标系。
3.调用ROI过滤器
核心函数位置:obstacle/lidar/roi_filter/hdmap_roi_filter/hdmap_roi_filter.cc
boolHdmapROIFilter::Filter(constpcl_util::PointCloudPtr&cloud,constROIFilterOptions&roi_filter_options,pcl_util::PointIndices*roi_indices);
官方文档的描述如下:
高精地图 ROI 过滤器(往下简称“过滤器”)处理在ROI之外的激光雷达点,去除背景对象,如路边建筑物和树木等,剩余的点云留待后续处理。
一般来说,Apollo 高精地图 ROI过滤器有以下三步:
1. 坐标转换
2. ROI LUT构造
3. ROI LUT点查询
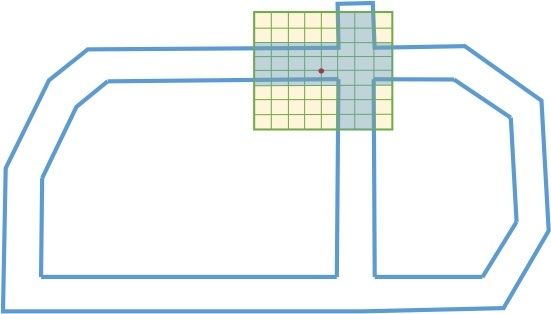
ROI 过滤器部分涉及到了 扫描线法 和 位图编码 两个技术。具体来看,该部分分以下几步:
a.坐标转换
将地图ROI多边形和点云转换至激光雷达传感器位置的地方坐标系。
b.确定地图多边形主方向
比较所有点的 x、y 方向的区间范围,取区间范围较小的方向为主方向。并将地图多边形 (map_polygons) 转换为待加工的多边形 (raw polygons)。
c.建立位图
将 raw polygons 转化为位图 (bitmap) 中的格点,位图有以下特点:
位图范围, 以 Lidar 为原点的一片区域 (-range, range)*(-range, range) 内,range 默认 70米
位图用于以格点 (grid) 的方式存储 ROI 信息。若某格点值为真,代表此格点属于 ROI。
默认的格点大小为 cell_size 0.25米。
在列方向上,1bit 代表 1grid。为了加速操作,Apollo 使用 uint64_t 来一次操纵64个grids。
为了在位图中画出一个多边形,以下3个步骤需要被完成
i. 获得主方向有效范围
ii.将多边形转换为扫描线法所需的扫描间隔:将多变形在主方向上分解为线(多边形->片段->线),计算每条线的扫描间隔。
iii. 基于扫描间隔在位图中画格点

d.ROI点检测
通过检查 grid 的值,确定在位图中得每一个 grid 是否属于 ROI。
4.调用分割器(segmentor)
入口函数所在文件cnn_segmentation.cc
boolCNNSegmentation::Segment(constpcl_util::PointCloudPtr&pc_ptr,constpcl_util::PointIndices&valid_indices,constSegmentationOptions&options,vector
分割器采用了 caffe 框架的深度完全卷积神经网络(FCNN) 对障碍物进行分割,有以下四步:
a.通道特征提取
计算以 Lidar 传感器某一范围内的各个单元格 (grid) 中与点有关的8个统计量,将其作为通道特征(channel feature)输入到 FCNN。
1. 单元格中点的最大高度
2. 单元格中最高点的强度
3. 单元格中点的平均高度
4. 单元格中点的平均强度
5. 单元格中的点数
6. 单元格中心相对于原点的角度
7. 单元格中心与原点之间的距离
8. 二进制值标示单元格是空还是被占用如
计算时默认只使用 ROI 区域内的点,也可使用整个 Lidar 范围内的点,使用标志位 use_full_cloud_ 作为开关。
b.基于卷积神经网络的障碍物预测
工作原理如下:完全卷积神经网络由三层构成:下游编码层(特征编码器)、上游解码层(特征解码器)、障碍物属性预测层(预测器)
特征编码器将通道特征图像作为输入,并且随着特征抽取的增加而连续下采样其空间分辨率。 然后特征解码器逐渐对特征图像 上采样到输入2D网格的空间分辨率,可以恢复特征图像的空间细节,以促进单元格方向的障碍物位置、速度属性预测。 根据具有非线性激活(即ReLu)层的堆叠卷积/分散层来实现 下采样和 上采样操作。

基于 FCNN 的预测,Apollo 获取了每个单元格的四个预测信息,分别用于之后的障碍物聚类和后期处理。

c.障碍物集群(cluster2D)
核心函数位置 obstacle/lidar/segmentation/cnnseg/cluster2d.h
voidCluster(constcaffe::Blob
constcaffe::Blob
constapollo::perception::pcl_util::PointCloudPtr&pc_ptr,
constapollo::perception::pcl_util::PointIndices&valid_indices,
floatobjectness_thresh,booluse_all_grids_for_clustering);
Apollo基于单元格中心偏移预测构建有向图,采用压缩的联合查找算法(Union Find algorithm )基于对象性预测有效查找连接组件,构建障碍物集群。
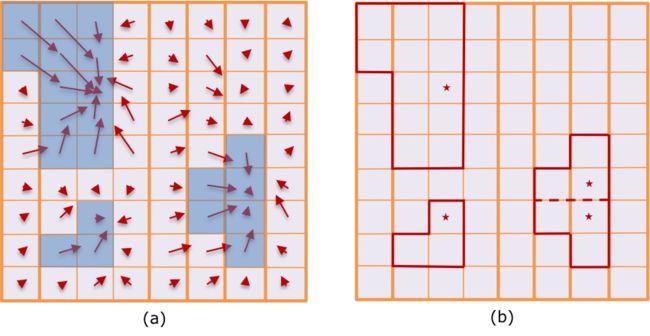
(a)红色箭头表示每个单元格对象中心偏移预测;蓝色填充对应于物体概率不小于0.5的对象单元。
(b)固体红色多边形内的单元格组成候选对象集群。
d.后期处理
涉及的函数 obstacle/lidar/segmentation/cnnseg/cluster2d.h
voidFilter(constcaffe::Blob
constcaffe::Blob
voidClassify(constcaffe::Blob
voidGetObjects(constfloatconfidence_thresh,constfloatheight_thresh,
constintmin_pts_num,std::vector
聚类后,Apollo获得一组包括若干单元格的候选对象集,每个候选对象集包括若干单元格。根据每个候选群体的检测置信度分数和物体高度,来确定最终输出的障碍物集/分段。
从代码中可以看到 CNN分割器最终识别的物体类型有三种:小机动车、大机动车、非机动车和行人。
在obstacle/lidar/segmentation/cnnseg/cluster2d.h中
enumMetaType{
META_UNKNOWN,
META_SMALLMOT,
META_BIGMOT,
META_NONMOT,
META_PEDESTRIAN,
MAX_META_TYPE
};
5.障碍物边框构架
void BuildObject(ObjectBuilderOptions options, ObjectPtr object)
边界框的主要目的还是预估障碍物(例如,车辆)的方向。同样地,边框也用于可视化障碍物。
如图,Apollo确定了一个6边界边框,将选择具有最小面积的方案作为最终的边界框

6.障碍物追踪
入口函数位置:obstacle/lidar/tracker/hm_tracker/hm_tracker.cc
// @brief track detected objects over consecutive frames
// @params[IN] objects: recently detected objects
// @params[IN] timestamp: timestamp of recently detected objects
// @params[IN] options: tracker options with necessary information
// @params[OUT] tracked_objects: tracked objects with tracking information
// @return true if track successfully, otherwise return false
boolTrack(conststd::vector
constTrackerOptions&options,
std::vector
障碍物追踪可分两大部分,即 数据关联 和 跟踪动态预估。Apollo 使用了名为 HM tracker 的对象跟踪器。实现原理:
在HM对象跟踪器中,匈牙利算法(Hungarian algorithm)用于检测到跟踪关联,并采用 鲁棒卡尔曼滤波器(Robust Kalman Filter) 进行运动估计。
数据关联
数据关联的过程是确定传感器接收到的量测信息和目标源对应关系的过程,是多传感多目标跟踪系统最核心且最重要的过程 [11]。
Apollo 首先建立关联距离矩阵,用于计算每个对象 (object ) 和 每个轨迹 (track )之间的关联距离。之后使用 匈牙利算法 为 object和 track 进行最优分配。
计算关联距离时,Apollo 考虑了以下5个关联特征,来评估 object 和 track 的运动及外观一致性,并为其分配了不同的权重。

由上表可以看出,Apollo 在计算关联距离时,重点考虑的还是几何距离和两者的形状相似度。计算得到类似下图的关联距离矩阵后,使用匈牙利算法将 Object 与 Track 做匹配。

跟踪动态预估(Track motion Estimation)
使用卡尔曼滤波来对 track 的状态进行估计,使用鲁棒统计技术来剔除异常数据带来的影响。
不了解卡尔曼滤波原理的同学请参考:卡尔曼滤波器的原理以及在matlab中的实现 [13]。这一部分的滤波整体看来是一个标准的卡尔曼滤波。在此基础上,Apollo 团队加入了一些修改,根据官方文档,Apollo 的跟踪动态预估有以下三个亮点 :
a.观察冗余
在一系列重复观测中选择速度测量,即滤波算法的输入,包括锚点移位、边界框中心偏移、边界框角点移位等。冗余观测将为滤波测量带来额外的鲁棒性, 因为所有观察失败的概率远远小于单次观察失败的概率。
卡尔曼更新的观测值为速度。每次观测三个速度值 :
锚点移位速度、边界框中心偏移速度 和 边界框角点位移速度。
从三个速度中,根据运动的一致性,选出与之前观测速度偏差最小的速度为最终的观测值。
根据最近3次的速度观测值,计算出加速度的观测值。
b.分解
高斯滤波算法 (Gaussian Filter algorithms)总是假设它们的高斯分布产生噪声。 然而,这种假设可能在运动预估问题中失败,因为其测量的噪声可能来自直方分布。 为了克服更新增益的过度估计,在过滤过程中使用故障阈值。
这里的故障阈值应该对应着程序中的 breakdown_threshold_。
该参数被用于以下两个函数中,当更新的增益过大时,它被用来克服增益的过度估计:
KalmanFilter::UpdateVelocity
KalmanFilter::UpdateAcceleration
两者的区别在于:
速度的故障阈值是动态计算的,与速度误差协方差矩阵有关
velocity_gain*=breakdown_threshold_;
加速度的故障阈值是定值,默认为2
acceleration_gain *= breakdown_threshold;
c.更新关联质量(UpdateQuality)??
原始卡尔曼滤波器更新其状态不区分其测量的质量。 然而,质量是滤波噪声的有益提示,可以估计。 例如,在关联步骤中计算的距离可以是一个合理的测量质量估计。 根据关联质量更新过滤算法的状态,增强了运动估计问题的鲁棒性和平滑度
更新关联质量 update_quality 默认为 1.0,当开启适应功能时 (s_use_adaptive ==true)Apollo 使用以下两种策略来计算更新关联质量:
1. 根据 object 自身的属性 — 关联分数 (association_score) 来计算
2. 根据新旧两个 object 点云数量的变化
首先根据这两种策略分别计算更新关联质量,之后取得分小的结果来控制滤波器噪声。
7.障碍物类型融合
入口函数位置:obstacle/lidar/type_fuser/sequence_type_fuser/sequence_type_fuser.cc
boolFuseType(constTypeFuserOptions&options,std::vector
该部分负责对 object 序列 (object sequence) 进行类型 (type) 的融合。
object 的type 如下代码所示:
enum ObjectType {
UNKNOWN = 0,
UNKNOWN_MOVABLE = 1,
UNKNOWN_UNMOVABLE = 2,
PEDESTRIAN = 3,
BICYCLE = 4,
VEHICLE = 5,
MAX_OBJECT_TYPE = 6,
};
Apollo 将被追踪的objects 视为序列。
当 object 为 background 时,其类型为 "UNKNOW_UNMOVABLE"。
当 object 为 foreground 时,使用线性链条件随机场(Linear chain Conditional Random Fields) 和 维特比(Viterbi)算法对 object sequence 进行 object 的类型的融合。