1 命名实体识别模型介绍
诸如中文分词、词性标注、命名实体等问题均属于序列标签标注问题。经典的模型有HMM,MEMM,CRF模型,这些都是比较传统的方法,三种模型各有优劣,HMM模型假设观测独立,不依赖观测之间的序列特征,MEMM虽然加入了观测序列之间的跳转特征,但由于采用了局部归一化引入了标记偏置的问题,最后CRF采用全局归一化从而弥补了HMM和MEMM的缺点,但是计算量却比较大。
随着深度学习的兴起,将CNN和RNN模型应用到标签标注问题上,取得了不俗的结果。比较各模型的结果,一般来说, DNN之前,CRF的结果最好,应用中也最为广泛, DNN这把神器出来后,state-of-the-art的结果均已被DNN的各种模型占领。DNN重在特征的自学习,将DNN学习到的特征送入到CRF中是一个很自然的思路。下面介绍NeuroCRF命名实体识别模型,望文知义,就是神经网络+CRF的模型,这里的神经网络采用的是BI-LSTM网络,该模型的结果是我在实际测试中表现最好的。(CNN+CRF模型没有测试,听说表现不俗。)NeuroCRF的出处和代码见底部的链接。
1.1 LSTM 与 CRF融合
LSTM与CRF融合时,LSTM层负责特征提取(和所有的深度网络一样),但也只是对输入数据X进行加工,未对输入数据X对应的输出标签y进行加工,因此在LSTM网络输出层追加一层CRF层,通过CRF层对标签之间的跳转特征进行加工,这里的CRF模型选用的是线性链CRF模型。

结合图1的表述来说。首先将输入数据X输入到Bi-LSMT网络中,网络的输出P的一行表示为某个word对应的每种tag的分值。将这个P送入到CRF层中,实际上所起的作用就是CRF中的状态特征或者发射特征,通过CRF学习的tag之间的跳转特征实际上就是状态转移特征。
1.1.1 Bi-LSTM的输出
直接上代码,如下
outputs, final_states = tf.nn.bidirectional_dynamic_rnn(lstm_cell["forward"], lstm_cell["backward"], input, dtype=tf.float32, sequence_length=sequence_length, initial_state_fw=initial_state["forward"], initial_state_bw=initial_state["backward"])
Bi-LSTM的输出包含两部分,outputs,final_states,其中outputs就是每个时间t时刻的输出h_t, final_states就是每个时间t时刻的记忆单元cell_t。这里网络的输出矩阵P只用到了outputs. 看了多个版本Bi-lstm的输出层的实现,各有千秋:
版本1
weight, bias = self.weight_and_bias(2 * args.rnn_size, args.class_size) output = tf.reshape(tf.transpose(tf.stack(outputs), perm=[1, 0, 2]), [-1, 2 * args.rnn_size]) prediction = tf.nn.softmax(tf.matmul(outputs, weight) + bias)
版本2
outputs = tf.reshape(outputs, [-1, num_units]) //输出层的学习参数 W = weight_init([num_units, D_label]) b = bias_init([D_label]) output = tf.matmul(outputs, W) + b // 损失 loss=tf.reduce_mean((output-labels)**2)
版本3
outputs = tf.nn.xw_plus_b(token_lstm_output_squeezed, W, b, name="output_before_tanh") outputs = tf.nn.tanh(outputs, name="output_after_tanh") scores = tf.nn.xw_plus_b(outputs, W, b, name="scores")
1.2 模型结构
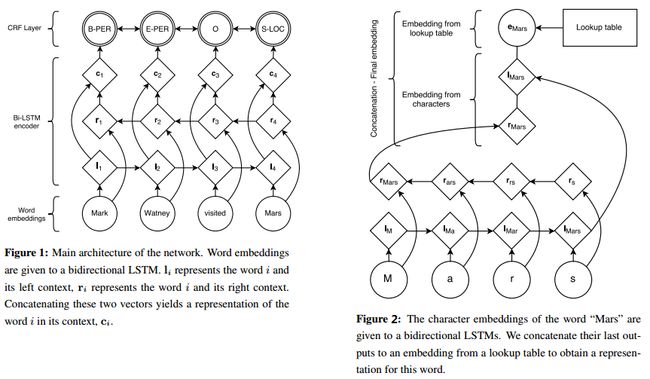
Figure1描述了BiLSTM+CRF进行实体识别的一般网络结构:首先用word2vec或者Glove与训练好word embeddings 作为输入向量,送入到Bi-LSTM中,输出是经过Bi-LSTM网络编码后的包含上下文信息的新的词向量 ci,最后将 ci 送入到CRF层中,经过这一层学习到得到的分值为最终为每个word所打的标签对应的分值。
Figure2是在Figure1所示的网络结构上,对输入信息又加入一层character embeddings。 对于中文来说,character embeddings 应该是分词后的每个词包含的字对应的embeddings,比如对于“”,其对应的character embeddings 就是"简",“书”对应的embeddings。在别的论文中看到有作者进一步对单个汉字进行拆分,比如"锦",拆分成"钅"和"帛",说是汉字的偏旁也是能够表达一些隐含信息的。
1.3 代码结构
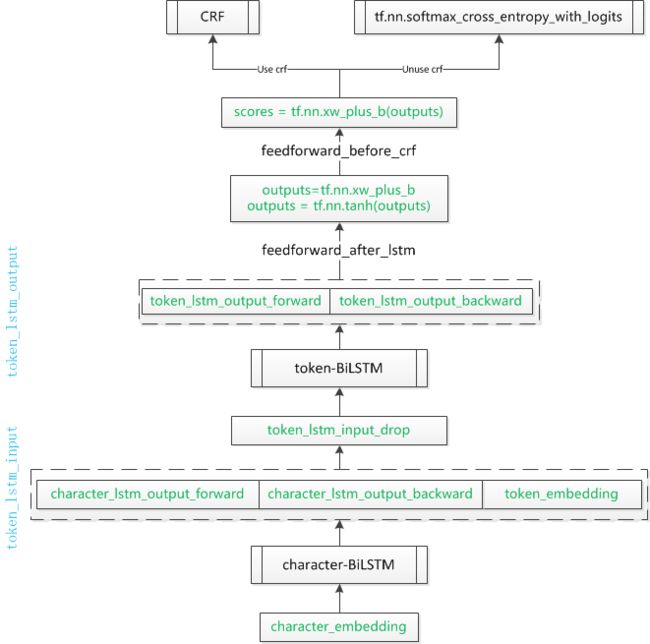
2 数据准备
2.1 数据标注方式说明
数据标注方式,对实体进行标注方式有两种,BIO和BIEOS。 B表示Beign, I 表示Internal, O表示Other, E表示End,S表示Single.举个例子,"第八 代 雅阁"的两种标注方式:
第八 B-MODEL
代 I-MODEL
雅阁 I-MODEL
和
第八 B-MODEL
代 I-MODEL
雅阁 E-MODEL
BIEOS的标注更为详细,模型的结果表现也优于BIO方式。
完整的数据格式如下,其中每一行是的第一个是要进行实体类别标注的词,第二个是词性,第三个是实体类别标注。
EU NNP B-ORG
rejects VBZ O
German JJ B-MISC
call NN O
to TO O
boycott VB O
British JJ B-MISC
lamb NN O
. . O O
2.2 数据标注
由于没有专门的人员进行实体类别的标注,只能依靠自己,通过人工标注+程序,反复的校验。
实体类别有:汽车品牌(brand),车型(model),产品(product_name),公司(company_name),组织机构名(org_name),地点(location_name),人名(person_name),职位(title_name),其他(misc).
首先借助多个第三方实体识别工具,识别产品、公司、组织机构、地点、人名、职位等实体,在识别出的实体集中通过行业词典+word2vec的方式提取出车型和品牌。这一步主要得益于我们长期维护的一个行业词典。数据集中的实体及类别基本确定后,对数据集进行清洗,将数据集按照句子拆分,并分析句子中包含的实体个数和类别分布,去除包含实体少的句子,对数据集中的每个类别下的实体进行均衡,最后整理出大约10w条富含实体的句子。
3 模型结果展示和解读
以下是基于10w条进行进行训练和测试的结果。这里仅使用了words-level embeddings。
训练结果
processed 1306244 tokens with 252442 phrases; found: 252367 phrases; correct: 218323.
accuracy: 94.80%; precision: 86.51%; recall: 86.48%; FB1: 86.50
BRAND: precision: 92.18%; recall: 89.24%; FB1: 90.68 18124
COMPANYNAME: precision: 85.01%; recall: 85.05%; FB1: 85.03 32655
JOBTITLE: precision: 90.20%; recall: 92.82%; FB1: 91.49 18333
LOCATION: precision: 84.62%; recall: 86.69%; FB1: 85.64 33164
MISC: precision: 97.58%; recall: 98.68%; FB1: 98.13 538
MODEL: precision: 82.10%; recall: 88.95%; FB1: 85.39 55556
ORGNAME: precision: 82.72%; recall: 79.73%; FB1: 81.20 11184
PERSONNAME: precision: 86.79%; recall: 86.54%; FB1: 86.66 20972
PRODUCTNAME: precision: 78.30%; recall: 62.89%; FB1: 69.75 20048
TIME: precision: 95.64%; recall: 96.34%; FB1: 95.99 41793
测试结果
processed 47386 tokens with 9229 phrases; found: 9191 phrases; correct: 7943.
accuracy: 94.62%; precision: 86.42%; recall: 86.07%; FB1: 86.24
BRAND: precision: 90.88%; recall: 89.45%; FB1: 90.16 746
COMPANYNAME: precision: 84.79%; recall: 83.73%; FB1: 84.26 1190
JOBTITLE: precision: 86.72%; recall: 88.57%; FB1: 87.63 670
LOCATION: precision: 84.78%; recall: 86.47%; FB1: 85.62 1183
MISC: precision: 100.00%; recall: 100.00%; FB1: 100.00 23
MODEL: precision: 84.71%; recall: 87.35%; FB1: 86.01 2014
ORGNAME: precision: 78.50%; recall: 75.75%; FB1: 77.10 386
PERSONNAME: precision: 87.12%; recall: 84.87%; FB1: 85.98 792
PRODUCTNAME: precision: 76.44%; recall: 66.75%; FB1: 71.27 662
TIME: precision: 94.69%; recall: 96.07%; FB1: 95.38 1525
从结果来看,还是不错的,观察具体识别的结果,可以看到模型的学习能力还是很强大的,有些label标错了也能正确的识别出来。以下数据的第三列是标注结果,第四列是模型预测结果。
总结 v O O
: wm O O
近期 t O O
, wd O O
金杯 n B-MODEL B-MODEL
蒂阿兹 nz I-MODEL I-MODEL
、 wn O O
昌河 nz B-MODEL B-MODEL
M70 nx I-MODEL I-MODEL
、 wn O O
猎豹 v B-MODEL B-MODEL
CT7 nx I-MODEL I-MODEL
、 wn O O
长安 nz B-MODEL B-MODEL
CX70T nx I-MODEL I-MODEL
、 wn O O
起亚 nz B-BRAND B-MODEL
混动 n O I-MODEL
Niro nx B-PRODUCTNAME I-MODEL
极睿 nz I-PRODUCTNAME I-MODEL
、 wn O O
潍柴 nz B-MODEL B-MODEL
英致 nz I-MODEL I-MODEL
G3CVT nx I-MODEL I-MODEL
版 n I-MODEL I-MODEL
等 udeng O O
车型 n O O
相继 d O O
上市 vi O O
。 wj O O
Refs
- Marc-Antoine Rondeau, LSTM-Based NeuroCRFs for Named Entity Recognition
- Guillaume Lample,Neural Architectures for Named Entity Recognition
- Full-Rank Linear-Chain NeuroCRF for Sequence Labeling
- https://github.com/Franck-Dernoncourt/NeuroNER