Pandas是Python下最强大的数据分析和探索工具,它包含高级数据结构和一些精巧的工具,使得在Python中处理数据变得非常快速和简单。Pandas构建在Numpy之上,名称来源于面板数据(Pabel Data)和Python数据分析(Data Analysis)最初是作为金融数据分析工具被开发出来,在2009年底开源。
Pandas的功能非常强大,支持类似与SQL的数据增、删、改、查,并且带有丰富的数据处理函数;支持时间序列分析功能;支持灵活处理缺失数据等。Pandas有两种基本数据结构:Series和DataFrame,其中Series称为序列,可以生成一个一维数组,DataFrame 则生成一个二维数组,这个二维数组的每一列都是一个Series。下面对这两种数据结构的使用进行介绍:
Series
Series是一维标记数组,可以存储任意数据类型,默认使用数字作为索引,也可指定索引(相当于字典的键)。而相较List,Series和Array都只能存储相同的数据类型,运算效率更高。
Series的创建
1).通过传递一个list对象来创建Series,默认创建整形索引
import numpy as np
import pandas as pd
data = pd.Series([1,2,3,4])
print(data)
0 1
1 2
2 3
3 4
dtype: int64
显然由输出可知,生成了索引为数字的一维数组。
2).创键指定索引的Series
a = pd.Series([1,2,3,4],index=['a','b','c','d'])
print(a)
a 1
b 2
c 3
d 4
dtype: int64
由输出可知生成了索引为字母a,b,c,d的一维数组。
3).通过字典创建Series
adata = {'a':1,'b':2,'c':3,'d':4}
sdata = pd.Series(adata,name = '映射')
sdata.index.name = 'id'
print(sdata)
id
a 1
b 2
c 3
d 4
Name: 映射, dtype: int64
-
Series的属性
Series对象的属性:dtype,index,values,name
Series.index的属性:name
sdata.dtype
dtype('int64')
sdata.index
Index(['a', 'b', 'c', 'd', 'e'], dtype='object', name='id')
sdata.values
array([1, 2, 3, 4])
sdata.name
'映射'
sdata.index.name
'id'
Series的增删改查
- 常规查询
sdata[2]
3
sdata['c']
3
sdata[1:3]
id
b 2
c 3
Name: 映射, dtype: int64
显然,对于指定索引的Series除了可以使用指定的索引调用外,也可使用数字索引进行切片查询,需要注意的是,进行切片查询时,不包含闭区间的末端点。
- 条件查询
sdata[sdata>=2]
id
b 2
c 3
d 4
Name: 映射, dtype: int64
- 添加数据
# 从序列尾部进行添加
sdata['e'] = 5
sdata
id
a 1
b 2
c 3
d 4
e 5
Name: 映射, dtype: int64
- 删除数据
# 根据索引进行删除
sdata = sdata.drop('e')
sdata
id
a 1
b 2
c 3
d 4
Name: 映射, dtype: int64
修改数据
sdata['a'] = 9
sdata
id
a 9
b 2
c 3
d 4
Name: 映射, dtype: int64
Series的缺失值检测
使用新索引时,原有的数据不变,新索引对应的值为np.nan,文本显示为NaN。
new_index = ['a','b','c','d','e']
sdata = pd.Series(sdata,index=new_index)
sdata
a 9.0
b 2.0
c 3.0
d 4.0
e NaN
Name: 映射, dtype: float64
显然由于未给出索引对应的值,系统自动设置为NaN
- 检测缺失值
sdata.isnull()
a False
b False
c False
d False
e True
Name: 映射, dtype: bool
pd.isnull(sdata)
a False
b False
c False
d False
e True
Name: 映射, dtype: bool
- 过滤缺失值
# 直接删除缺失值对应的索引
sdata[pd.notnull(sdata)]
a 9.0
b 2.0
c 3.0
d 4.0
Name: 映射, dtype: float64
-
Series的自动对齐
两个索引顺序不一样的Series对象进行运算时会自动对齐,索引相同的值进行运算。
a = pd.Series([1,2,3,4],index=[1,2,3,4])
b = pd.Series([1,2,3,4],index=[2,3,1,4])
print(a)
print(b)
c = a+b
print(c)
1 1
2 2
3 3
4 4
dtype: int64
2 1
3 2
1 3
4 4
dtype: int64
1 4
2 3
3 5
4 8
dtype: int64
DataFrame
pandas使用DataFrame来构建数据帧,其功能特点有:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
pandas.DataFrame(data,index,columns,dtype,copy)
| 参数 | 描述 |
|---|---|
data |
数据,使用各种格式,如:ndarray,series,map,list,dict,constant,甚至是另一个DateFrame |
| index | 行标签,如果没有索引传递,默认为np.arrange(n) |
columns |
列表签,如果没有索引传递,默认为np.arrange(n |
dtype |
每列的数据类型 |
copy |
默认为False,用于复制数据 |
创建数据帧
Pandas数据帧(DataFrame)可使用各种输入创建:
- list
- dict
- constant
- Numpy ndarrays
- DataFrame
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print(df)
0
0 1
1 2
2 3
3 4
4 5
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['姓名','年龄'])
print(df)
姓名 年龄
0 Alex 10
1 Bob 12
2 Clarke 13
可以看到,在只给出列索引未给出行索引时,行索引默认为np.arange(n)
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['姓名','年龄'],dtype=float)
print(df)
姓名 年龄
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0
显然,dtype参数将年龄列的数据类型更改为浮点。
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print(df)
Name Age
0 Tom 28
1 Jack 34
2 Steve 29
3 Ricky 42
- 列选择
Pandas使用列表的访问方式访问数据帧的列
df['Name']
0 Tom
1 Jack
2 Steve
3 Ricky
Name: Name, dtype: object
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print(df)
Name Age
rank1 Tom 28
rank2 Jack 34
rank3 Steve 29
rank4 Ricky 42
- 添加列
# 直接往数据帧添加列
df['身高'] = [171,187,156,165]
print(df)
Name Age 身高
rank1 Tom 28 171
rank2 Jack 34 187
rank3 Steve 29 156
rank4 Ricky 42 165
- 删除列
del df['Age']
print(df)
Name 身高
rank1 Tom 171
rank2 Jack 187
rank3 Steve 156
rank4 Ricky 165
显然Age列被删除了
- 行选择
通过将行标签传递给loc()函数来选择行。
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print(df)
Name Age
0 Tom 28
1 Jack 34
2 Steve 29
3 Ricky 42
df.loc[2]
Name Steve
Age 29
Name: 2, dtype: object
也可以使用切片操作来选择数据帧的多行
df[1:3]
Name Age
1 Jack 34
2 Steve 29
- 添加行
df1 = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
print(df1,'\n',df2)
a b
0 1 2
1 3 4
a b
0 5 6
1 7 8
df = df1.append(df2)
print(df)
a b
0 1 2
1 3 4
0 5 6
1 7 8
显然成功的将df2的数据添加到了df1尾部
- 删除行
x = df.drop(0)
print(x)
a b
1 3 4
1 7 8
成功将行索引为0的两行数据删除
数据帧的基本功能
| 属性或方法 | 描述 |
|---|---|
T |
对数据帧进行转置 |
axes |
返回行列标签列表 |
dtype |
返回对象中的数据类型 |
empty |
返回布尔值,若返回True表示对象为空 |
ndim |
返回对象的纬度 |
shape |
返回数据帧的形状 |
size |
返回数据帧的大小 |
values |
将DataFrame中的数据作为ndarray返回 |
head(n) |
返回数据帧前n行的值,默认返回前五行 |
tail(n) |
返回数据帧的后n行的值 |
- 描述统计
使用describe()函数来计算有关数据帧列的统计信息摘要
dat = [[1,3,2],[2,3,7],[5,4,9]]
pdata = pd.DataFrame(dat)
pdata.describe()
0 1 2
count 3.000000 3.000000 3.000000
mean 2.666667 3.333333 6.000000
std 2.081666 0.577350 3.605551
min 1.000000 3.000000 2.000000
25% 1.500000 3.000000 4.500000
50% 2.000000 3.000000 7.000000
75% 3.500000 3.500000 8.000000
max 5.000000 4.000000 9.000000
Pandas统计函数
pct_change():将每个元素与其前一个元素进行比较,并计算变化百分比。默认情况下,该函数对列进行操作,可使用参数axis=1将其作用到行上。
a = pd.Series([1,2,3,4,5,6])
print(a.pct_change)
b = pd.DataFrame(np.random.randn(5,2))
print(b.pct_change)
协方差
cov():计算序列对象之间的协方差系数,NAN将被自动排除。
协方差(Covarance)在概率论和统计学中用于衡量两个变量之间的总体误差,方差是协方差的一种特殊情况(两个变量相同)。我们将期望值为与的两个具有有限二阶矩的随机变量X与Y之间的协方差定义为:
协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果X与Y是独立的,那么.
s1 = pd.Series(np.random.randn(10))
s2 = pd.Series(np.random.randn(10))
print(s1.cov(s2))
0.20033130811311448
当应用于DataFrame时,该函数将计算所有列之间的协方差。
frame = pd.DataFrame(np.random.randn(10,5),columns=['a','b','c','d','e'])
frame['a'].cov(frame['b'])
-0.1791517011010157
frame.cov()
a b c d e
a 0.455670 -0.179152 0.427838 -0.363667 0.133017
b -0.179152 1.735416 -0.198297 0.560132 -0.065114
c 0.427838 -0.198297 1.166038 -0.851135 0.308675
d -0.363667 0.560132 -0.851135 1.395686 0.153952
e 0.133017 -0.065114 0.308675 0.153952 1.227275
相关系数
在概率路和统计学中,相关(Correlation)表示两个随机变量之间线性关系的强度和方向。相关系数是用来衡量两个随机变量之间的线性相关程度。在二元变量的相关分析过程中比较常用的有Pearson相关系数、Spearman相关系数和判定系数,在这里只对Pearson相关系数进行说明:
相关系数的取值范围:
- 两个变量为正相关
- 两个变量为负相关
- 两个变量之间不存在线性关系
- 两个变量之间为完全正相关
表示不同程度的线性相关:
- 不存在线性关系
- 低度线性相关
- 显著度线性相关
- 高度线性相关
Pandas使用corr()实现相关系数的计算:
corr(method):当对象为数据帧时返回相关系数矩阵,
method参数指定计算方法,支持
pearson、spearman、kendall等,默认为计算pearson系数。
D = pd.DataFrame([range(1,8),range(2,9)])
# 计算数据帧的相关系数矩阵
corr_a = D.corr(method='spearman')
# 选取第一行
s1 = D.loc[0]
s2 = D.loc[1]
# 计算s1和s2的相关系数
corr_b = s1.corr(s2,method='pearson')
D
0 1 2 3 4 5 6
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
5 1 1 1 1 1 1 1
6 1 1 1 1 1 1 1
corr_b
1.0
缺失值处理
数据帧的缺失值处理与Series处理方式相同.
本文对Pandas的两种数据结构Series、DataFrame和统计函数做了一些基本的介绍,更多详细内容可以参考Pandas教程。
最后来看一个例子:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 正确显示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family']='sans-serif'
excel = '/Users/wcjb/Documents/data/chapter3/demo/data/catering_sale.xls'
data = pd.read_excel(excel,index_col='日期')
# 显示前5行数据
print('前5行数据:',data.head())
# 显示数据帧的的基本统计量
print('基本统计量:',data.describe())
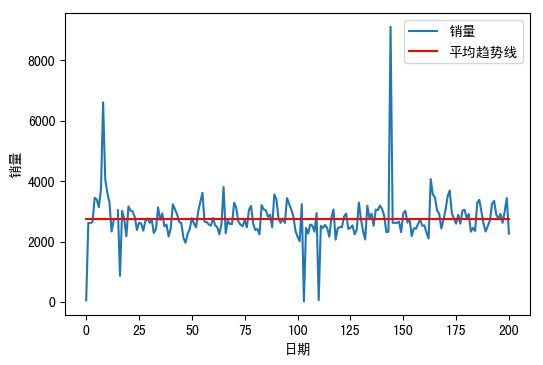
y = data['销量']
x = range(201)
# 绘制箱线图
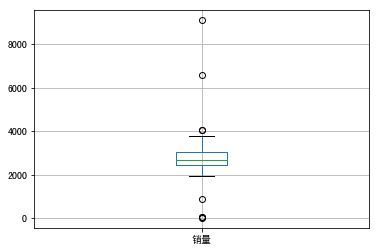
data.boxplot()
plt.figure(dpi = 100)
plt.plot(x,y)
plt.xlabel('日期')
plt.ylabel('销量')
y1 = y.mean()*np.ones(201)
plt.plot(x,y1,'r-',label = '平均趋势线')
plt.legend()
- 运行结果
前5行数据: 销量
日期
2015-03-01 51.0
2015-02-28 2618.2
2015-02-27 2608.4
2015-02-26 2651.9
2015-02-25 3442.1
基本统计量: 销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106.440000