并行复制最早在5.6就搞出来了,是一个库级别的并行复制(slave_parallel_type可以有两个值:DATABASE 默认值,基于库的并行复制方式;LOGICAL_CLOCK:基于组提交的并行复制方式),不太好用;所以实际上5.6的主从复制是一个串行的复制,这就导致复制延迟时有发生了
在5.7中有了另一个值后,配置并行复制基本成了标配
将slave_parallel_type设置为'LOGICAL_CLOCK',slave_parallel_workers设置为大于0的值,即算是开启了并行复制
打开从库
show variables like '%parallel%';

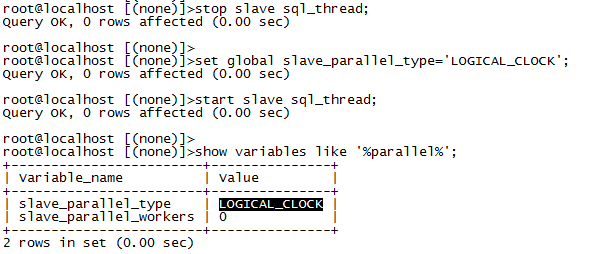
将这个database修改为logical_clock,在此之前,需要先关闭sql_thread
stop slave sql_thread;
set global slave_parallel_type='LOGICAL_CLOCK';
start slave sql_thread;
show variables like '%parallel%';
将slave_parallel_workers设置为大于0的值
set global slave_parallel_workers=16;(网文的测试表明线程数在16个时候的QPS较为理想)

修改完线程数之后,最好重新执行以下stop slave/start slave;如果没有执行的话,有可能表面上增加了线程,实际上仍然没有开启并行复制!
用sysbench结合pt-heartbeat来做一次延迟测试
sysbench对100万行的5张表进行1000秒的压测,通过pt-heartbeat实时监测延迟结果
#查看当前线程的工作状态(☆)
use performance_schema;
select * from replication_applier_status_by_worker;
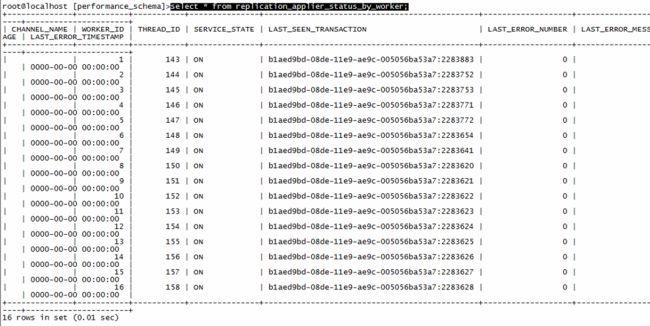
上面这个语句是用来检查当前线程工作状态的,可以看到当前确实是16个线程;如果在更改了slave_parallel_workers参数之后,没有重新slave的话,有可能这里仍然是单线程工作的情况
(我之前的测试就是修改之后没有重新slave,结果测试出来的延迟值达到了610s,和下图单线程的结果几乎没有太大区别)
将线程数设置为0,测试出的从库延迟如下
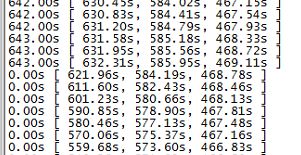
将线程数设置为16,测试出的从库延迟如下
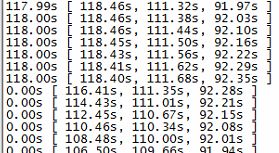
可以看到16线程的情况下,延迟时间只有单线程工作情况下的18%,这个提升可以说是非常巨大了
除了上面的参数以外,一些必要的参数设置如下

相关的表可以在performance_schema库下进行查看

select * from replication_applier_configuration;
select * from replication_applier_status;
select * from replication_applier_status_by_coordinator;
select * from replication_applier_status_by_worker;
select * from replication_connection_configuration;
select * from replication_connection_status;
select * from replication_group_member_stats;
select * from replication_group_members;
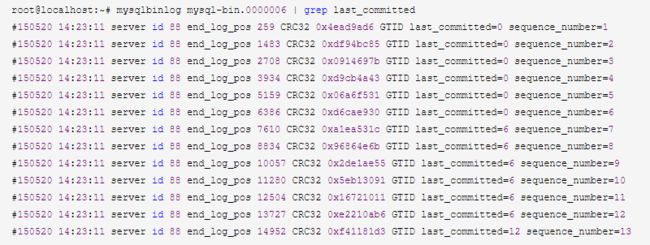
关于并行复制中涉及到的组提交概念
通过mysqlbinlog工具可以看到组提交的相关信息