这里的Stream并不是指类似于IO中的输入输出流之类的一种实际概念,更多的是指一种编程思想,它本身并不执行什么特殊功能,而是提供一系列的操作来提高编程的效率。
如果接触过RxJava一类的API,肯定会对那种编程风格印象深刻,整条逻辑非常清晰,也非常易读。这里的Stream类也类似,但它提供了一套更为通用的API来处理集合。
Stream类的方法都很简单,和Optional类一样,只是了解这些方法很容易,但是没太多用处,关键是把这些方法灵活的组合起来,最终写出简洁高效的代码才是重点。下面,就让我们一起来了解一下这些方法。
创建一个Stream对象
1.of(T... values)方法
这是Stream的一个静态方法,可以创意一个或几个类型相同的元素,然后就创建了一个对应类型的Stream对象:
Stream stream = Stream.of(1,2,3,4);
由于一些基本类型的装箱与拆箱降低了效率,所以又给我们提供了一系列的包装类型:
IntStream, LongStream, DoubleStream
注意,这些包装类型并不是继承与Stream,而是有共同的父类:BaseStream
2.generate(Supplier s)
这也是一个静态方法,他需要提供一个供应者,Stream中的元素由供应者生成,注意这样生成的Stream元素使无限多的。下面我们来随机生成一个Stream并打印前10个元素:
DoubleStream.generate(Math::random).limit(10).forEach(out::println);
(可以看到,这些APi配合lambda等一些新特性写出来的代码非常简洁)
3.iterate(T seed, UnaryOperator f)
这个也是静态方法,同样也是生成无限序列,只不过它可以指定一个种子,然后依据这个种子及提供的生成器生成元素。这种序列有这样一个规律,第一个元素就是种子本身,以后的元素都是以前一个元素为参数,然后调用生成器生成的值,如下:
seed , f(seed) , f(f(seed) , ...
大致可以用这样一个数学表达式形如:
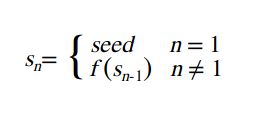
还是看一段代码比较直接:
DoubleStream.iterate(1,d->d+1).limit(10).forEach(out::println);
打印如下:
1.0
2.0
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0
4.通过集合获取
既然Stream设计出来主要是操作集合的,那么肯定可以由集合来生成Stream。
Collection有这样一个成员方法:stream() ,所以他的所有实现类都可以通过这个方法来生成一个Stream对象。
操作
1.distinct()
这个方法很简单,就是去重,主要时通过equals()方法判断是否相同
DoubleStream.of(4,2,3,3).distinct().forEach(out::println);
打印结果:
4.0
2.0
3.0
2.filter(Predicate predicate)
和字面意思一样,就是对Stream中的元素进行一遍过滤,如:
DoubleStream.of(-2,-8,0,1,3).filter(d -> d > 0).forEach(out::println); //过滤掉小于等于0的元素
3.map(Function mapper)
感觉类似的API都有这个操作函数,而且功能都类似,这个方法就是对所有的元素执行一层操作:
DoubleStream.of(-2,-8,0,1,3).map(d -> d*2).forEach(out::println); //所有元素乘以2
另外还提供了了mapToInt,mapToLong和mapToDouble的方法,分别返回IntStream, LongStream,DoubleStream
4.flatMap(Function> mapper)
和map类似,如下代码:
Stream> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
Stream outputStream = inputStream.
flatMap((childList) -> childList.stream());
他也有flatMapToDouble,flatMapToInt,flatMapToLong类似的方法
5.peek(Consumer action)
这个方法比较特殊,首先它会返回一个与他调用者一样的Stream,,但是会在输出每个元素之前执行一次传入的方法,但这个方法的执行不会对流中元素造成影响。
IntStream.of(1,2,3,4).peek(i -> out.print("<" + i + ">")).forEach(out::println);
打印结果:
<1>1
<2>2
<3>3
<4>4
注意这个方法的操作只有在元素被消费的时候才会执行,下面代码不会有任何输出:
IntStream.of(1,2,3,4).peek(i -> out.print("<" + i + ">")).filter(i -> i>2);
这里也就可以看出,Stream这个类并不是每执行一个操作符都会循环将元素执行一遍,只有在最后被消费时才会统一执行,这样可以提高效率。
6.limit(long maxSize)
这个我在演示那几个无限序列的构造是就用过了,很简单,就是取前n个元素。
7.skip(long n)
这个和limit相反,是跳过前n个元素。
8.sorted()
对Stream中的元素进行排序,默认是按自然顺序排序,他还有个重载方法,可以指定一种排序规则,和实现Comparable接口要实现的方法类似。注意,Stream那几个基本类型的包装类型是没有这个重载方法的,只能按自然顺序排序。下面演示一下用两种方法进行正序还倒序排序:
Stream.of(5,3,4,1,9,7,2).sorted().forEach(out::println); //升序
Stream.of(5,3,4,1,9,7,2).sorted((i1,i2) -> i2-i1).forEach(out::println); //倒序
9.min,max
按照其字面意思是取最大最小值,返回值是一个Optional的对象,为我们做了空指针保护。但是需要注意的是,如果是Stream的那几个基本类型的包装类,的确是去最大最小值,但是如果是一个普通的Stream,这两个方法需要传入一个比较器,结果就不一定是按其字面意思一样取最大最小值,而是取排序后两端的值。如min是取左端max取右端,如下面这个例子:
Stream.of(5,3,4,2,1,9,7,2).max((i1,i2) -> i2-i1).ifPresent(out::println); //1
Stream.of(5,3,4,2,1,9,7,2).min((i1,i2) -> i2-i1).ifPresent(out::println); //9
10.count()
很简单就是统计元素数量,为什么不设计一个size()方法呢,因为count() 更加灵活,它统计的过前面操作过之后剩余元素的个数:
out.print(Stream.of(5,3,4,1,9,7,2).count()); //7
out.print(Stream.of(5,3,4,1,9,7,2).skip(2).count()); //5
11.allMatch(Predicate predicate) ,anyMatch(Predicate predicate) ,noneMatch(Predicate predicate)
这是几个逻辑判断的方法,都很简单,使用时需要一个判断表达式。allMatch是当所有元素都满足表达式时才返回true,anyMatch是只要有一个元素满足就返回true,noneMatch是当所有元素都不满足时返回true
12.findFirst()
这个是取第一个元素,和count一样,也是灵活的,只取经过前面操作过之后剩余元素的第一个
Stream.of(5,3,4,1,9,7,2).findFirst().ifPresent(out::print); //5
Stream.of(5,3,4,1,9,7,2).skip(2).findFirst().ifPresent(out::print); //4
13.sum()
求和函数,不过只有那几个Stream的基本类型的包装类才有。
14.collect
这个方法还是比较复杂的,有些人将Stream的流程分为三步,第一步构建,第二部进行各种操作,最后进行输出。这便是最后一步的其中一种方式。
简单来说,他执行了这样一个操作,将Stream中经过前面操作后的元素,最后收集(collect)在一个容器之中。这个方法有两个重载,我们先看那个复杂一点的:
arrayList = Stream.of(5,3,4,1,9,7,2)
.collect(() -> new ArrayList(),
(list, item) -> list.add(item),
(list1, list2) -> list1.addAll(list2));
这个重载方法需要传入三个参数,都是接口,也就是要传入三个功能。第一个参数是要指定collect要返回的类型,第二个参数是对元素进行第一步处理,它将元素临时放入一个和最终返回值类型相同的中间容器,最后一个参数的作用就是将中间容器的内容传递到最终要返回的容器中。
之所以要设计这么多步骤,是为了我们能进一步操作这些元素。不过这么多步骤也是有点复杂了,也许我们最后就是简单地将元素集中到一个集合中那么简单,所以额外又给我们提供了一个简单一点的重载:
R collect(Collector collector)
这个重载只需一个参数,而且还有几个为我们封装好的方法:
Collectors.toList() //收集到list
Collectors.toSet() //收集到set
list = Stream.of(5,3,4,1,9,7,2)
.collect(Collectors.toList());
15.reduce
这个也是Stream最后一步中的方法,也很复杂。我们先来看最简单的一个重载:
Optional reduce(BinaryOperator accumulator)
它传入一个操作,返回一个Optional对象,这个操作有点像使用iterate生产无限长序列一样。他也是需要一种操作,它有两个参数,第一个是上次执行的返回值,第二个是即将执行的Stream元素。我们来模拟一下sum方法:
Stream.of(5,3,4,1,9,7,2)
.reduce((sum,i)->sum+i).ifPresent(out::print); //31
第二个重载相比上一个多一个参数,也就是初值:
T reduce(T identity, BinaryOperator accumulator)
由于有初值,所以结果肯定不为空,所以返回的类型也就不需要是Optional.
out.print(Stream.of(5,3,4,1,9,7,2).reduce(10,(sum,i)->sum+i)); // 41
第三个重载有三个参数,不但复杂,而且也让很多人非常迷惑,首先看一个例子:
ArrayList arrayList = Stream.of(1, 2, 3, 4)
.reduce(new ArrayList(),
(list, item) -> {
System.out.println("Function1:"+item);
list.add(item);
System.out.println("fun1_list: " + list);
return list;
}, (list, item) -> {
System.out.println("Function2:"+item);
list.addAll(item);
System.out.println("fun2_list: " + list);
return list;
});
System.out.println("arrayList: " + arrayList);
打印结果:
Function1:1
fun1_list: [1]
Function1:2
fun1_list: [1, 2]
Function1:3
fun1_list: [1, 2, 3]
Function1:4
fun1_list: [1, 2, 3, 4]
arrayList: [1, 2, 3, 4]
可以看到的是,只有第二个参数中的方法执行了,第三个参数虽然有返回值但是并没有打印任何东西。一个比较合理的解释是Stream是支持并发操作的,为了避免竞争,对于reduce线程都会有独立的result,最后合并每个线程的result得到最终结果。这也说明了了第三个函数参数的数据类型必须为返回数据类型了。
Java8学习笔记目录