最近写了Kaggle的一个playground项目——预测科比投篮是否命中https://www.kaggle.com/c/kobe-bryant-shot-selection,主要使用python的pandas和sklearn包。 这里和大家分享一下。
首先就是进入Kaggle官网https://www.kaggle.com/,Kaggle是一个专门数据竞赛的网站。经常会有一些有奖的竞赛,当然入门也可以选101和playground的有趣的例子进行练习。官网给出的经典例子就是预测Titanic乘客的生存概率。
当然第一步就是注册。
注册后就可以直接选择自己想参加的竞赛了,本文都以预测科比投篮命中为例。注册之后我们点击上方的Competions,也就是图中上方第一个红框来进入竞赛选择页面。接着点击下图第二个红框ALL来显示所有的竞赛。然后我们可以选第三个红框,里面有getting started(101)和playground。都是难度稍低的竞赛很适合练习。
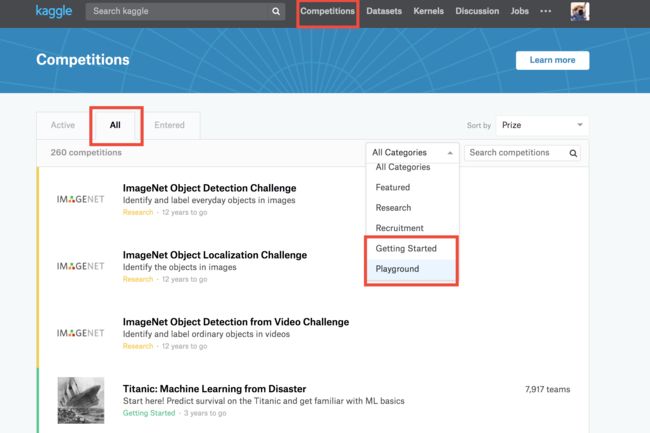
其中在gettind started里面的项目应该都是有tutorials的,都会有相关的数据处理和模型选择的教程。https://www.kaggle.com/c/titanic#tutorials 想做数据处理的也可以先看这个例子。我们仍以预测科比投篮为例,从all的playground里找到(https://www.kaggle.com/c/kobe-bryant-shot-selection) 。
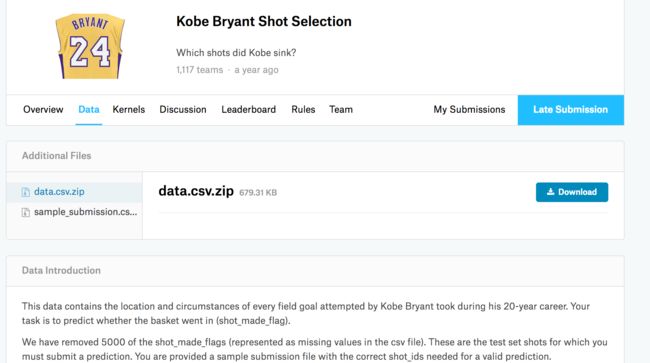
进去之后大概就是这个样子的,我们点击Data,进入数据页面,上面data.csv.zip是总的数据,包括训练集和测试集。下面的sample_submission....是提交结果的demo。
这里给之前没接触过机器学习的同学讲解一下什么是训练集和测试集,了解机器学习的请跳过这三段。训练集是用来训练你的机器学习模型的。就比如我给了你一堆猫和狗的图片,并且我给每张图片都标记上了这张图是‘猫’还是‘狗’。而我们的目的是为了解决如果给你很多(比如1亿张)新的猫或狗的图片,而且没有标记到底是猫还是狗,你一定懒得去做(对,我不相信有人能这么有毅力!!!)会想让机器解决。但机器学习,你也要教它一些事实,比如长得像图片A的就是狗,长得像图片B的就是猫。也就是把图片和正确的标记给机器,让机器能够根据你给他的这些数据来学习到一个判别方法,而给它的‘图片和正确的标记’就是训练集。
给了训练集之后机器是学习了,但它学的好不好呢?这就需要用到测试集,测试集也包含图片和正确的标记。这就好比我们学生时代的考试,你要去考考机器,看它学的怎么样,从而才知道你训练的好不好。但测试集不能和训练集重复,防止它死记硬背,就像当年考数学,老师会把题修改一下让你做一样。
所以我们一般会将得到的所有标记好的图片(包含对应正确标记)分为两组大致9比1的样子,分别是训练集和测试集。来对机器进行训练和测试。
回到正轨,解压上面下载的文件,打开csv文件。我们会看到——
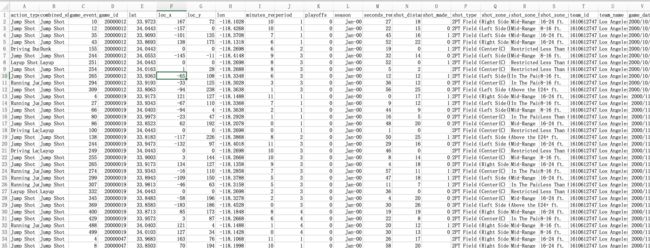
除了表头,一共有30697行,而且有数字有字符串,看得头都大了,怎么办!
还好我们有电脑,有python,有别人写好的工具包pandas!
第一步,我们进入python,在命令行输入python
第二步,导入pandas
>>import pandas as pd
如果报错,说明你没安装pandas,去安装吧
第三步,载入csv文件并查看数据,下面的文件名写你自己的文件路径
>>data = pd.read_csv('data/data.csv')
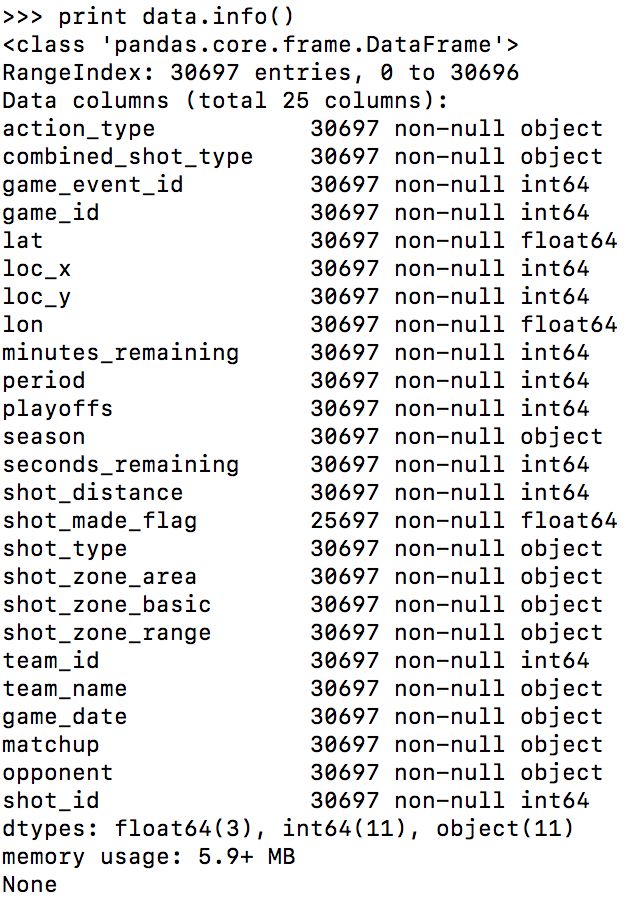
>>print data.info()
打印结果如下,可以看出显示了csv文件的各列名称,数量,是否全空,类型(这里不是数字都是object),还有一些统计信息等等。
其中shot_made_flag就是投进与否,也就是结果/标签/分类。1表示投进,0表示没进。
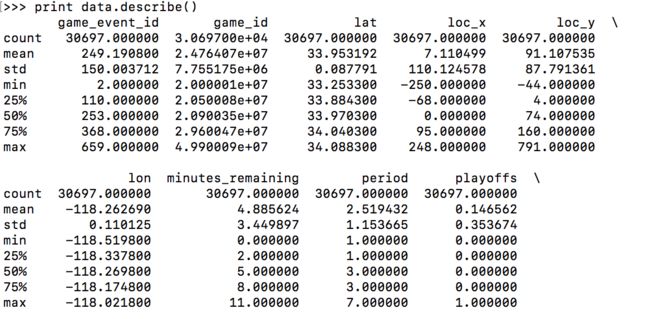
第4步,我们可以查看数值类数据的一些分布情况,这里只是部分。
>>print data.describe()
第5步,查看非数值类数据分布
>>print data.describe(include=['O'])

但是这样我们还是不知道这些离散值有哪几类,比如shot_type到底一共有哪几种呢?像这样。
>>print set(data['shot_type'].tolist())
打印结果:set(['3PT Field Goal', '2PT Field Goal'])
如果你还想看每类下面的统计数字。再像这样。
>>> print data['shot_type'].value_counts()
2PT Field Goal 24271
3PT Field Goal 6426
Name: shot_type, dtype: int64
总之,pandas的功能超乎你想象。
不过只能看数据分布是不够的,机器现在还是只能识别数字,所以上面的object类型的数据,我们还是要转换成数字。这里我们用最简单的映射办法来实现,映射按照次数来实现,比如上面的‘shot_type’,我们按照出现的次数从0向上排,比如这里2分球我们认为是0,3分球认为是1。
除了这些问题之外,我们还发现有些数据是没有用处的,比如team_id、team_name都是湖人,没什么用,还有就是shot_distant和loc_x、loc_y其实是有重复信息的。所以我们进行了筛选和处理了一部分,这一步在数据处理术语叫数据预处理。从而得到一个新的数据表pretreated_data(pandas的DataFrame格式)。代码地址https://github.com/Cauchyzhou/shot_predict 。
接着我们还要拆分数据到训练集和测试集,注意保存的路径也要根据自己的实际情况来。
PS:这里的测试集没有结果/标签,是因为我们的测试是直接将预测的结果传到网站上,网站会返回一个预测结果与真实结果的误差。
>>notnull = pretreated_data['target'].notnull()
>>isnull = ~ notnull
>>train_set = pretreated_data[notnull]
>>predict_set = pretreated_data[isnull]
>>train_set.to_csv('data/train_set.csv')
>>predict_set.to_csv('data/predict_set.csv')
到这里,数据预处理基本就结束了。
接着我们就要用训练集,训练了,我们这里使用传统的机器学习方法,而传统方法,最好的就是用sklearn这个工具包,全名scikit-learn。官网地址:http://scikit-learn.org/stable/
这个包有多粗暴呢,就是粗暴到你可以不了解任何算法细节,直接调用就好了(当然还是推荐理解一下算法,毕竟没有最好的算法,只有最合适的算法)
这里我们就用最简单的决策树来预测结果。
>>from sklearn import tree
>>import pandas as pd
>>data = pd.read_csv('data/train_set.csv')
>>X = data.drop('target',axis=1) #去掉结果/标签列
>>Y = data['target'] #训练集的结果
>>clf = tree.DecisionTreeClassifier()
>>clf.fit(X,Y)
经过上面几句话,我们就获得了训练好的模型clf。接着我们就可以用这个模型来预测测试集的结果了。
>>predict = pd.read_csv('data/predict_set.csv')
>>X_ = predict.drop('target',axis=1)
>>out = clf.predict(X)
这样就预测好了,是不是很粗暴!接下来保存结果。
>>OutDf = pd.DataFrame(index= predict['shot_id'].values,columns=['shot_made_flag'])
>>OutDf['shot_made_flag'] = out
>>OutDf.to_csv('DT_out.csv')
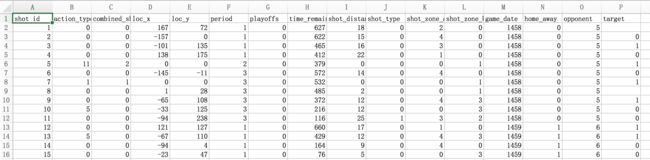
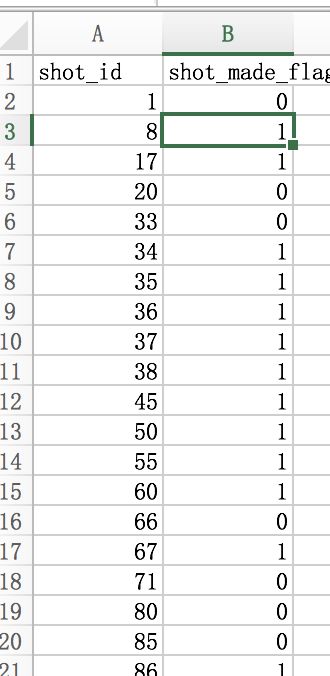
好了,这样我们整体的一个机器学习的简单项目就完成,但我们还是要看一下效果。我们生成的csv文件是这样式的~第一列是shot_id,第二列是shot_made_flag
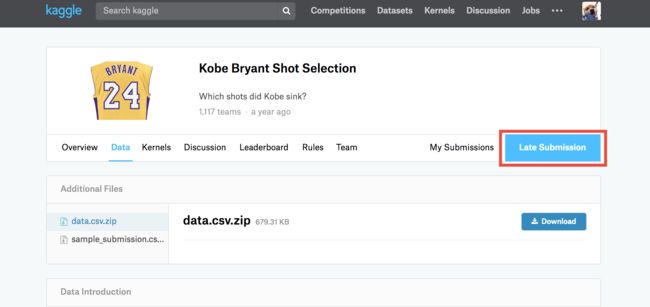
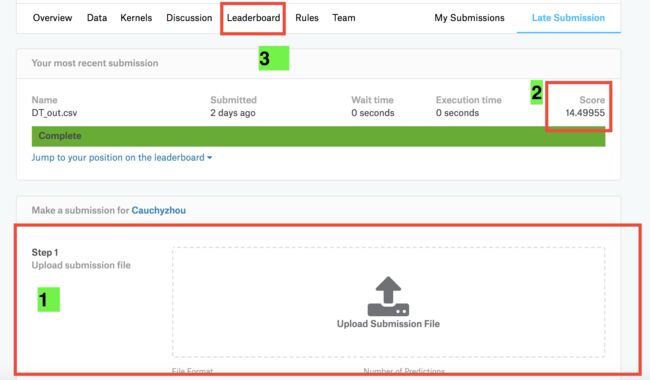
我们需要在线提交,这里保存的结果格式是点击红框(这里可能不太一样,因为我曾经提交过,不是第一次提交)
然后我们就会进入到这个页面,找到绿色背景的数字1那里,我们把自己的csv文件拖进去,就会出现2那里的损失得分,越小越好,因为我用的是最简单的决策树,只能处理线性问题,显然这个问题并不是线性的,所以得分很差。
因为这个竞赛已经结束了,所以不会有排名,只能进到3Leaderboard根据自己的得分来得出自己的排名。
这样,我们的一个整体的kaggle竞赛的流程就结束了,没想到码博客还是挺累的,而且修改博客竟然会导致重新上传图片。写了2个半小时,改了半个小时格式。写的还是比较仓促,希望大家多提意见。