assignment1
学习记录(做的过程中写个提纲,做完了再完善一下说不定是要理解深刻一点,总之写下来没坏处,就当纪念啦(。>∀<。))
环境Ubuntu
数据集cifar10
先完成knn代码部分
第一部分
两层循环求L2距离 compute_distances_two_loops
要求
#Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension.
dists[i,j]=np.sqrt(np.sum((self.X_train[j,:]-X[i,:])**2))
一层循环求L2距离compute_distances_one_loops
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
dists[i,:]=np.sqrt(np.sum(self.X_train-X[i,:],axis=1))
无循环 no_loop
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
用基本数组操作、广播机制
平方差展开
(dists=sqrt(X_train^2+X^2-2*X_train*X))
第二部分
predict_labels
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
使用 numpy.argsort


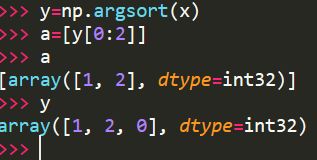
将dists进行排序存入数组
再挑出最合适的label
使用np.bincount和np.argmax
argmax:返回沿轴axis最大值的索引 bincount:统计次数,计算数据集的标签列(y_train)的分布

closest_y=self.y_train[np.argsort(dists[i,:])[0:k]]
y_pred[i]=np.argmax(np.bincount(closest_y))
完成后
用jupyter notebook打开knn.ipynb,运行

这种作业做起来好棒啊(注释说的清楚明白嘿嘿)。
发现很多感觉懂的真正写下来很难,有种文字障碍的感觉。
numpy API一点都不熟 ,想着整理又觉得每次搜一下用法也可以,哎可能这就是懒吧。
就是个记录并非教程所以详细过程也没说啦。