1-19日更新。
今天打开电脑,又跑了一遍代码。发现,整个87页都能下载下来了,估计是ip解封了,说明我编写的代码,能运行!!!
结果如图:
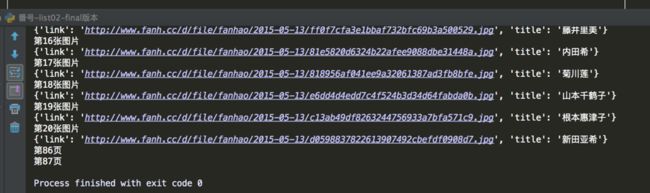
Paste_Image.png
不过,也发现了一个问题。图片中的86页等是没有被解析成功的,似乎直接跳过了?这是怎么个情况?我还没有想明白。。。
--------------------------------------------------分割线-------------------
找了一个番号网站练练手,发现还有一些难度。
首先,我要实现的是,将网站上每个女忧的图片下载到本地文件夹并且把图片名称改成女优名字。
网站是这样的:http://www.fanh.cc/fanhao/index_19.html
遇到的几个问题。
第一,编码问题。
网页编码默认是gb2312的,跟平时接触的不一样。
最后结局办法也是出乎我意料。用到了text和content属性的区别。
第二,就是网站封ip。
我初次爬的时候,可以爬到第26页(一共89页),但是后来重新爬的时候明显爬不动了,爬个几页就会停止。我估计就是他们这个网站限制了我的ip,屏蔽我了,然后我换了代理ip,并且加上了headers,就可以正常访问了。但是依旧没办法爬取总共89页,这也是一个问题。值得深入研究一下。
第三,就是对“urllib.request.urlretrieve()”这个方法中的参数,深入研究了一下,发现还有一些门道的。
不说了,开始贴代码。其实代码能够正常运行。有一点,没有解决:如何突破网站屏蔽的限制?
#!/usr/bin/env python
# 最终目标。下载网页所有女忧的图片到本地,并且图片名字改成对应的女忧名字。第一,到最后一页。--最后,完美达成此目标。
# 接下来新的挑战。
'''
01,添加计数器,到了第几页,第X张图片,都会打印出来。
02,多线程或者多进程爬去,提高速度。
03,加一个进度条。
#目前运行到第12也就暂停了,为何??? 有的女忧的名字比较特殊,AZUMI/上原安住,结果弄得下载到文本有问题。
FileNotFoundError: [Errno 2] No such file or directory: '/Users/pro/Desktop/a2/AZUMI/上原安住.jpg',需要研究一下path参数了
答:这个问题基本解决了。
但是,出现了个新问题,似乎ip被屏蔽了,没办法流畅下载图片了,原先能下载15页,但是现在不用代理ip只能下载到4页左右。
'''
import requests,time
from bs4 import BeautifulSoup
import urllib.request
path='/Users/pro/Desktop/a2/'
url = 'http://www.fanh.cc/fanhao/index_2.html'
proxies = {"http": "120.35.30.178:80"}
def download(url,title):
urllib.request.urlretrieve(url,path + (title.split('/')[-1] + '.jpg'))
#图片名字这里,我花了很多心思,发现原来这里可以用到split属性,因为有些女优的名字是XX/xx这样的格式,如果不修改会报错。现在改过来了,这就没问题了。
time.sleep(2)
#print("Done")
def download_pic(url):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36 QQBrowser/4.1.4132.400'
}
y=1
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.content,'lxml')
#这里要注意text属性与content属性的区别。
#text属性返回的是Unicodex型的数据。而content返回的是二进制类型的数据。此处,用content就不会有乱码,而text属性就不行。
titles = soup.select('body > div.list > ul > li > p > a')
pic_links = soup.select('body > div.list > ul > li > a > img')
for title,pic_link in zip(titles,pic_links):
data = {
'title': title.get_text(),
'link' : 'http://www.fanh.cc'+ pic_link.get('src') #fanh.cc才是正确的网址,这里之前写的是fanhao.cc,出错过。
}
#运行到这个时候,data是一个字典结果。接下来的download函数如何调用字典中的数据是个难题!
download(data['link'],data['title'])
print('第%s张图片'%y)
y=y+1
print(data)
#接下来,运行程序,如下
all_page_links=['http://www.fanh.cc/fanhao/index_{}.html'.format(number) for number in range(2,89)]
p=1
for single_link in all_page_links:
download_pic(single_link) #这里也出现了一个小失误,应该填写single_link的,结果我写了url测试半天都不正确。尴尬。
print('第{}页'.format(p))
p=p+1
下面是运行结果:

Paste_Image.png
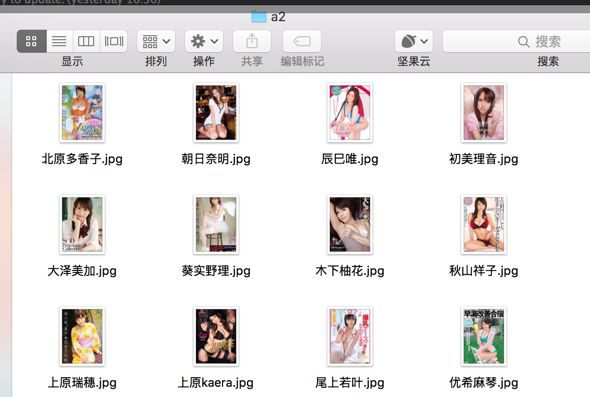
Paste_Image.png