本文为精度Spark-core的源码的第一节,主要内容包括Spark Deployment的简介和Standalone模式下启动集群的详细流程精读。
注:本专题的文章皆使用Spark-1.6.3版本的源码为参考,如果Spark-2.1.0版本有重大改进的地方也会进行说明。
Spark Deployment
Spark 的部署主要有四种方式:local、standalone、yarn、mesos
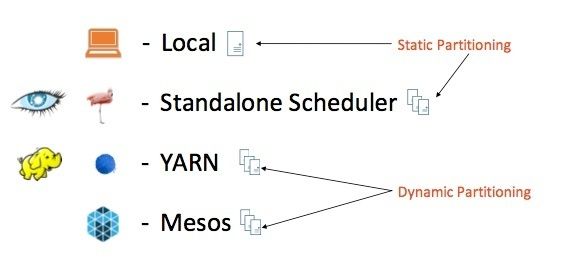
其中local和standalone模式主要用于测试学习,实际生产环境下国内一般都是使用yarn,这是历史原因造成的(考虑到集群中同时有Hadoop);而国外一般都是使用mesos,而且个人认为mesos也是一种趋势,关于yarn和mesos的部分,以后会单独进行分析,下面我们详细解读standalone模式下的集群启动的具体流程。
Standalone mode下集群启动源码精读
我们就从start-all.sh开始,主要代码如下:
# Load the Spark configuration
. "${SPARK_HOME}/sbin/spark-config.sh"
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh $TACHYON_STR
# Start Workers
"${SPARK_HOME}/sbin"/start-slaves.sh $TACHYON_STR
注释说的很明确了,我们继续追踪start-master.sh
CLASS="org.apache.spark.deploy.master.Master"
...
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS 1 \
--ip $SPARK_MASTER_IP --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT \
$ORIGINAL_ARGS
...
可以看出,是执行了spark-daemon.sh的start方法,即通过动态加载的方式将org.apache.spark.deploy.master.Master作为一个daemon(守护线程)来运行,所以我们直接分析Master的源码:
private[deploy] object Master extends Logging {
val SYSTEM_NAME = "sparkMaster"
val ENDPOINT_NAME = "Master"
def main(argStrings: Array[String]) {
//注册log
SignalLogger.register(log)
//实例化SparkConf,会加载`spark.*`格式的配置信息
val conf = new SparkConf
//使用MasterArguments对传入的参数argStrings和默认加载的conf进行封装,并执行一些初始化操作
val args = new MasterArguments(argStrings, conf)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
/**
* Start the Master and return a three tuple of:
* (1) The Master RpcEnv
* (2) The web UI bound port
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
val portsResponse = masterEndpoint.askWithRetry[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
}
首先注册log,实例化SparkConf并加载spark.*格式的配置信息,然后使用MasterArguments对传入的参数argStrings和默认加载的conf进行封装,并执行一些初始化操作,主要是加载配置信息,这里不做详细说明,我们接着往下看。
下面才是真正意义上的Start Master,startRpcEnvAndEndpoint函数中首先实例化了SecurityManager(Spark中负责安全的类),然后创建了RpcEnv(Spark的Rpc通信有三个抽象:RpcEnv、RpcEndpoint、RpcEndpointRef,这样做屏蔽了底层的实现,方便用户进行扩展,Spark-1.6.3底层的默认实现方式是Netty,而Spark-2.x已经将Akka的依赖移除),接着实例化Master,实际上就是实例化了一个RpcEndpoint(因为Master实现了ThreadSafeRpcEndpoint接口,而ThreadSafeRpcEndpoint又继承了RpcEndpoint),实例化完成后通过RpcEnv的setupEndpoint向RpcEnv进行注册,注册的时候执行了Master的onStart方法,最后返回了一个RpcEndpointRef(实际上是NettyRpcEndpointRef),通过获得的RpcEndpointRef向Master(Endpoint)发送了一条BoundPortsRequest消息,Master通过receiveAndReply方法接受到该消息(实际上是通过NettyRpcEnv中的Dispatcher进行消息的分配),模式匹配到是BoundPortsRequest类型的消息,然后执行reply方法进行回复,源码如下:
case BoundPortsRequest => {
context.reply(BoundPortsResponse(address.port, webUi.boundPort, restServerBoundPort))
}
至此Master启动完成,Rpc部分可以参考另一篇文章:Spark RPC 到底是个什么鬼?,下面贴出Master实例化部分和onStart方法的源码及中文注释:
Master实例化部分:
//默认的情况下,取消的task不会从工作的队列中移除直到延迟时间完成,所以创建一个守护线程来“手动”移除它
private val forwardMessageThread =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("master-forward-message-thread")
//用于执行重建UI代码的守护线程
private val rebuildUIThread =
ThreadUtils.newDaemonSingleThreadExecutor("master-rebuild-ui-thread")
//通过rebuildUIThread获得重建UI的执行上下文
private val rebuildUIContext = ExecutionContext.fromExecutor(rebuildUIThread)
//获取hadoop的配置文件
private val hadoopConf = SparkHadoopUtil.get.newConfiguration(conf)
//时间格式,用于构建application ID
private def createDateFormat = new SimpleDateFormat("yyyyMMddHHmmss") // For application IDs
//如果Master在60s内没有收到Worker发送的heartbeat信息就认为这个Worker timeout
private val WORKER_TIMEOUT_MS = conf.getLong("spark.worker.timeout", 60) * 1000
//webUI中显示的完成的application的最大个数,超过200个就移除掉(200/10,1)=20个完成的applications
private val RETAINED_APPLICATIONS = conf.getInt("spark.deploy.retainedApplications", 200)
//webUI中显示的完成的drivers的最大个数,超过200个就移除掉(200/10,1)=20个完成的drivers
private val RETAINED_DRIVERS = conf.getInt("spark.deploy.retainedDrivers", 200)
//如果Master在(REAPER_ITERATIONS + 1) * WORKER_TIMEOUT_MS)秒内仍然没有收到Worker发送的heartbeat信息,就删除这个Worker
private val REAPER_ITERATIONS = conf.getInt("spark.dead.worker.persistence", 15)
//recoveryMode:NONE、ZOOKEEPER、FILESYSTEM、CUSTOM,默认是NONE
private val RECOVERY_MODE = conf.get("spark.deploy.recoveryMode", "NONE")
//Executor失败的最大重试次数
private val MAX_EXECUTOR_RETRIES = conf.getInt("spark.deploy.maxExecutorRetries", 10)
//下面是各种“数据结构”,不再一一说明
val workers = new HashSet[WorkerInfo]
val idToApp = new HashMap[String, ApplicationInfo]
val waitingApps = new ArrayBuffer[ApplicationInfo]
val apps = new HashSet[ApplicationInfo]
private val idToWorker = new HashMap[String, WorkerInfo]
private val addressToWorker = new HashMap[RpcAddress, WorkerInfo]
private val endpointToApp = new HashMap[RpcEndpointRef, ApplicationInfo]
private val addressToApp = new HashMap[RpcAddress, ApplicationInfo]
private val completedApps = new ArrayBuffer[ApplicationInfo]
private var nextAppNumber = 0
// Using ConcurrentHashMap so that master-rebuild-ui-thread can add a UI after asyncRebuildUI
private val appIdToUI = new ConcurrentHashMap[String, SparkUI]
private val drivers = new HashSet[DriverInfo]
private val completedDrivers = new ArrayBuffer[DriverInfo]
// Drivers currently spooled for scheduling
private val waitingDrivers = new ArrayBuffer[DriverInfo]
private var nextDriverNumber = 0
Utils.checkHost(address.host, "Expected hostname")
//下面是Metrics系统相关的代码
private val masterMetricsSystem = MetricsSystem.createMetricsSystem("master", conf, securityMgr)
private val applicationMetricsSystem = MetricsSystem.createMetricsSystem("applications", conf,
securityMgr)
private val masterSource = new MasterSource(this)
// After onStart, webUi will be set
private var webUi: MasterWebUI = null
private val masterPublicAddress = {
val envVar = conf.getenv("SPARK_PUBLIC_DNS")
if (envVar != null) envVar else address.host
}
private val masterUrl = address.toSparkURL
private var masterWebUiUrl: String = _
//当前Master的状态:STANDBY, ALIVE, RECOVERING, COMPLETING_RECOVERY
private var state = RecoveryState.STANDBY
private var persistenceEngine: PersistenceEngine = _
private var leaderElectionAgent: LeaderElectionAgent = _
private var recoveryCompletionTask: ScheduledFuture[_] = _
private var checkForWorkerTimeOutTask: ScheduledFuture[_] = _
// As a temporary workaround before better ways of configuring memory, we allow users to set
// a flag that will perform round-robin scheduling across the nodes (spreading out each app
// among all the nodes) instead of trying to consolidate each app onto a small # of nodes.
// 避免将application的运行限制在固定的几个节点上
private val spreadOutApps = conf.getBoolean("spark.deploy.spreadOut", true)
// Default maxCores for applications that don't specify it (i.e. pass Int.MaxValue)
private val defaultCores = conf.getInt("spark.deploy.defaultCores", Int.MaxValue)
if (defaultCores < 1) {
throw new SparkException("spark.deploy.defaultCores must be positive")
}
// Alternative application submission gateway that is stable across Spark versions
// 用来接受application提交的restServer
private val restServerEnabled = conf.getBoolean("spark.master.rest.enabled", true)
private var restServer: Option[StandaloneRestServer] = None
private var restServerBoundPort: Option[Int] = None
onStart方法:
override def onStart(): Unit = {
//打日志
logInfo("Starting Spark master at " + masterUrl)
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
//实例化standalone模式下的MasterWebUI并绑定到HTTP Server
webUi = new MasterWebUI(this, webUiPort)
webUi.bind()
//可以通过这个Url地址看到Master的信息
masterWebUiUrl = "http://" + masterPublicAddress + ":" + webUi.boundPort
//以固定的时间间隔检查并移除time-out的worker
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CheckForWorkerTimeOut)
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
//实例化并启动restServer用于接受application的提交
if (restServerEnabled) {
val port = conf.getInt("spark.master.rest.port", 6066)
restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl))
}
restServerBoundPort = restServer.map(_.start())
//启动MetricsSystem
masterMetricsSystem.registerSource(masterSource)
masterMetricsSystem.start()
applicationMetricsSystem.start()
// Attach the master and app metrics servlet handler to the web ui after the metrics systems are
// started.
masterMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
applicationMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
//序列化器
val serializer = new JavaSerializer(conf)
//恢复机制,包括持久化引擎和选举机制
val (persistenceEngine_, leaderElectionAgent_) = RECOVERY_MODE match {
case "ZOOKEEPER" =>
logInfo("Persisting recovery state to ZooKeeper")
val zkFactory =
new ZooKeeperRecoveryModeFactory(conf, serializer)
(zkFactory.createPersistenceEngine(), zkFactory.createLeaderElectionAgent(this))
case "FILESYSTEM" =>
val fsFactory =
new FileSystemRecoveryModeFactory(conf, serializer)
(fsFactory.createPersistenceEngine(), fsFactory.createLeaderElectionAgent(this))
case "CUSTOM" =>
val clazz = Utils.classForName(conf.get("spark.deploy.recoveryMode.factory"))
val factory = clazz.getConstructor(classOf[SparkConf], classOf[Serializer])
.newInstance(conf, serializer)
.asInstanceOf[StandaloneRecoveryModeFactory]
(factory.createPersistenceEngine(), factory.createLeaderElectionAgent(this))
case _ =>
(new BlackHolePersistenceEngine(), new MonarchyLeaderAgent(this))
}
persistenceEngine = persistenceEngine_
leaderElectionAgent = leaderElectionAgent_
}
下面介绍Worker的启动
start-slaves.sh:
# Launch the slaves
"${SPARK_HOME}/sbin/slaves.sh" cd "${SPARK_HOME}" \; "${SPARK_HOME}/sbin/start-slave.sh" "spark://$SPARK_MASTER_IP:$SPARK_MASTER_PORT"
start-slave.sh:
CLASS="org.apache.spark.deploy.worker.Worker"
...
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS $WORKER_NUM \
--webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@"
和Master的启动类似,我们直接看Worker文件,仍然从main方法开始:
def main(argStrings: Array[String]) {
SignalLogger.register(log)
val conf = new SparkConf
val args = new WorkerArguments(argStrings, conf)
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, systemName, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
可以看到前面和Master类似,只不过Worker有可能是多个,所以需要根据workerNumber构造一个systemName,用来创建不同的RpcEnv,然后实例化Worker(即实例化Endpoint),实例化的时候需要传入masterAddresses(注意此处可能有多个Master),以便以后向Master注册,同时由于要向对应的RpcEnv注册,注册的时候同样要执行Worker的onStart方法,我会将Worker实例化和onStart的源码放到后面,这里我们先来看一下Worker向Master注册的代码(onStart方法中调用registerWithMaster):
private def registerWithMaster() {
// onDisconnected may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
registrationRetryTimer match {
case None =>
registered = false
registerMasterFutures = tryRegisterAllMasters()
connectionAttemptCount = 0
registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster))
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
case Some(_) =>
logInfo("Not spawning another attempt to register with the master, since there is an" +
" attempt scheduled already.")
}
}
可以看到内部调用了tryRegisterAllMasters方法:
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
val masterEndpoint =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
})
}
}
通过一个名为registerMasterThreadPool的线程池(最大线程数为Worker的个数)来运行run方法中的内容:首先通过setupEndpointRef方法获得其中一个Master的一个引用(RpcEndpointRef),然后执行registerWithMaster(masterEndpoint)方法,刚才得到的Master的引用作为参数传入,下面进入registerWithMaster方法:(注意此处的registerWithMaster方法是有一个RpcEndpointRef作为参数的,和刚开始的那个不一样)
private def registerWithMaster(masterEndpoint: RpcEndpointRef): Unit = {
masterEndpoint.ask[RegisterWorkerResponse](RegisterWorker(
workerId, host, port, self, cores, memory, webUi.boundPort, publicAddress))
.onComplete {
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
Utils.tryLogNonFatalError {
handleRegisterResponse(msg)
}
case Failure(e) =>
logError(s"Cannot register with master: ${masterEndpoint.address}", e)
System.exit(1)
}(ThreadUtils.sameThread)
}
内部使用masterEndpoint(Master的RpcEndpointRef)的ask方法向Master发送一条RegisterWorker的消息,并使用onComplete方法接受Master的处理结果,下面我们先来看一下消息到达Master端进行怎样的处理:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerUiPort, publicAddress) => {
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
context.reply(MasterInStandby)
} else if (idToWorker.contains(id)) {
context.reply(RegisterWorkerFailed("Duplicate worker ID"))
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerUiPort, publicAddress)
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
context.reply(RegisteredWorker(self, masterWebUiUrl))
schedule()
} else {
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
context.reply(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}
}
首先receiveAndReply方法匹配到Worker发过来的RegisterWorker消息,然后执行具体的操作:打了一个日志,判断Master现在的状态,如果是STANDBY就reply一个MasterInStandby的消息,如果idToWorker中已经存在该Worker的ID就回复重复的worker ID的失败信息,如果都不是,将获得的Worker信息用WorkerInfo进行封装,然后执行registerWorker(worker)操作注册该Worker,如果成功就向persistenceEngine中添加该Worker并reply给Worker RegisteredWorker(self, masterWebUiUrl)消息并执行schedule方法,如果注册失败就reply RegisterWorkerFailed消息,下面我们具体看一下Master端是如何注册Worker的,即registerWorker(worker)方法:
private def registerWorker(worker: WorkerInfo): Boolean = {
// There may be one or more refs to dead workers on this same node (w/ different ID's),
// remove them.
workers.filter { w =>
(w.host == worker.host && w.port == worker.port) && (w.state == WorkerState.DEAD)
}.foreach { w =>
workers -= w
}
val workerAddress = worker.endpoint.address
if (addressToWorker.contains(workerAddress)) {
val oldWorker = addressToWorker(workerAddress)
if (oldWorker.state == WorkerState.UNKNOWN) {
// A worker registering from UNKNOWN implies that the worker was restarted during recovery.
// The old worker must thus be dead, so we will remove it and accept the new worker.
removeWorker(oldWorker)
} else {
logInfo("Attempted to re-register worker at same address: " + workerAddress)
return false
}
}
workers += worker
idToWorker(worker.id) = worker
addressToWorker(workerAddress) = worker
true
}
首先判断是否有和该Worker的host和port相同且状态为DEAD的Worker,如果有就remove掉,然后获得该Worker的RpcAddress,然后根据RpcAddress判断addressToWorker中是否有相同地址的记录,如果有记录且老的Worker的状态为UNKNOWN就remove掉老的Worker,如果没有记录就打日志并返回false(导致上一步reply:RegisterWorkerFailed)然后分别在workers、idToWorker、addressToWorker中添加该Worker,最后返回true,导致上一步向Worker reply注册成功的消息:context.reply(RegisteredWorker(self, masterWebUiUrl)),并执行schedule(),即向等待的applications分配当前可用的资源(每当新的application加入或者有资源变化时都会调用该方法),这个方法我会用单独的一片文章详细分析,现在我们先来看Worker端是如何进行回复的,回到上面的registerWithMaster方法(有参数的),我们直接看成功后执行的handleRegisterResponse(msg)这个方法:
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl) =>
logInfo("Successfully registered with master " + masterRef.address.toSparkURL)
registered = true
changeMaster(masterRef, masterWebUiUrl)
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat)
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(WorkDirCleanup)
}
}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
case RegisterWorkerFailed(message) =>
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}
依然是模式匹配的方式:
- 如果接受到的是RegisteredWorker,会执行changeMaster方法,取消最后一次的重试,然后向自己的RpcEnv发送SendHeartBeat消息,使用receive方法接受到该消息后会通过sendToMaster方法向Master发送心跳,最后判断CLEANUP_ENABLED如果开启就向自己的RpcEnv发送WorkDirCleanup消息,接受到消息后将老的application的目录清除
- 如果接受到的是RegisterWorkerFailed就表明注册失败
changeMaster发送:
private def changeMaster(masterRef: RpcEndpointRef, uiUrl: String) {
// activeMasterUrl it's a valid Spark url since we receive it from master.
activeMasterUrl = masterRef.address.toSparkURL
activeMasterWebUiUrl = uiUrl
master = Some(masterRef)
connected = true
// Cancel any outstanding re-registration attempts because we found a new master
cancelLastRegistrationRetry()
}
cancelLastRegistrationRetry:
private def cancelLastRegistrationRetry(): Unit = {
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
registerMasterFutures = null
}
registrationRetryTimer.foreach(_.cancel(true))
registrationRetryTimer = None
}
如果Worker注册失败同样会通过registrationRetryTimer进行重试:
registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster))
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
可以看到向自己发送重新注册的消息:ReregisterWithMaster,receive接收到后会执行reregisterWithMaster()方法:
private def reregisterWithMaster(): Unit = {
Utils.tryOrExit {
//重试次数加1
connectionAttemptCount += 1
if (registered) {
//如果已经注册了,就取消重试
cancelLastRegistrationRetry()
} else if (connectionAttemptCount <= TOTAL_REGISTRATION_RETRIES) { //判断是否超过最大重试次数
logInfo(s"Retrying connection to master (attempt # $connectionAttemptCount)")
/**
* Re-register with the active master this worker has been communicating with. If there
* is none, then it means this worker is still bootstrapping and hasn't established a
* connection with a master yet, in which case we should re-register with all masters.
*
* It is important to re-register only with the active master during failures. Otherwise,
* if the worker unconditionally attempts to re-register with all masters, the following
* race condition may arise and cause a "duplicate worker" error detailed in SPARK-4592:
*
* (1) Master A fails and Worker attempts to reconnect to all masters
* (2) Master B takes over and notifies Worker
* (3) Worker responds by registering with Master B
* (4) Meanwhile, Worker's previous reconnection attempt reaches Master B,
* causing the same Worker to register with Master B twice
*
* Instead, if we only register with the known active master, we can assume that the
* old master must have died because another master has taken over. Note that this is
* still not safe if the old master recovers within this interval, but this is a much
* less likely scenario.
*/
master match {
case Some(masterRef) =>
// registered == false && master != None means we lost the connection to master, so
// masterRef cannot be used and we need to recreate it again. Note: we must not set
// master to None due to the above comments.
// 这里说的很清楚,如果注册失败了,但是master != None说明我们失去了和master的连接,所以需要重新创建一个masterRef
// 先取消原来阻塞的用来等待消息回复的线程
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
// 然后创建新的masterRef,然后重新注册
val masterAddress = masterRef.address
registerMasterFutures = Array(registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
val masterEndpoint =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
}))
case None =>
// 如果没有masterRef,先取消原来阻塞的用来等待消息回复的线程
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
// 然后执行最初的注册,即tryRegisterAllMasters
// We are retrying the initial registration
registerMasterFutures = tryRegisterAllMasters()
}
// We have exceeded the initial registration retry threshold
// All retries from now on should use a higher interval
// 如果超过刚开始设置的重试注册次数,取消之前的重试,开启新的注册,并改变重试次数和时间间隔
// 刚开始的重试默认为6次,时间间隔在5到15秒之间,接下来的10次重试时间间隔在30到90秒之间
if (connectionAttemptCount == INITIAL_REGISTRATION_RETRIES) {
registrationRetryTimer.foreach(_.cancel(true))
registrationRetryTimer = Some(
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(ReregisterWithMaster)
}
}, PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
}
} else {
logError("All masters are unresponsive! Giving up.")
System.exit(1)
}
}
}
至此Worker的启动和注册完成,即start-all.sh执行完成。
下面是Worker的初始化部分和onStart方法的源码及注释(重要部分):
初始化部分:
private val host = rpcEnv.address.host
private val port = rpcEnv.address.port
Utils.checkHost(host, "Expected hostname")
assert (port > 0)
// A scheduled executor used to send messages at the specified time.
private val forwordMessageScheduler =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("worker-forward-message-scheduler")
// A separated thread to clean up the workDir. Used to provide the implicit parameter of `Future`
// methods.
private val cleanupThreadExecutor = ExecutionContext.fromExecutorService(
ThreadUtils.newDaemonSingleThreadExecutor("worker-cleanup-thread"))
// For worker and executor IDs
private def createDateFormat = new SimpleDateFormat("yyyyMMddHHmmss")
// 发送心跳的时间间隔:timeout的时间 / 4
// Send a heartbeat every (heartbeat timeout) / 4 milliseconds
private val HEARTBEAT_MILLIS = conf.getLong("spark.worker.timeout", 60) * 1000 / 4
// 重试的模型及其次数设置
// Model retries to connect to the master, after Hadoop's model.
// The first six attempts to reconnect are in shorter intervals (between 5 and 15 seconds)
// Afterwards, the next 10 attempts are between 30 and 90 seconds.
// A bit of randomness is introduced so that not all of the workers attempt to reconnect at
// the same time.
private val INITIAL_REGISTRATION_RETRIES = 6
private val TOTAL_REGISTRATION_RETRIES = INITIAL_REGISTRATION_RETRIES + 10
private val FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND = 0.500
private val REGISTRATION_RETRY_FUZZ_MULTIPLIER = {
val randomNumberGenerator = new Random(UUID.randomUUID.getMostSignificantBits)
randomNumberGenerator.nextDouble + FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND
}
private val INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(10 *
REGISTRATION_RETRY_FUZZ_MULTIPLIER))
private val PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(60
* REGISTRATION_RETRY_FUZZ_MULTIPLIER))
//CLEANUP相关的设置
private val CLEANUP_ENABLED = conf.getBoolean("spark.worker.cleanup.enabled", false)
// How often worker will clean up old app folders
private val CLEANUP_INTERVAL_MILLIS =
conf.getLong("spark.worker.cleanup.interval", 60 * 30) * 1000
// TTL for app folders/data; after TTL expires it will be cleaned up
private val APP_DATA_RETENTION_SECONDS =
conf.getLong("spark.worker.cleanup.appDataTtl", 7 * 24 * 3600)
private val testing: Boolean = sys.props.contains("spark.testing")
//对master的引用
private var master: Option[RpcEndpointRef] = None
private var activeMasterUrl: String = ""
private[worker] var activeMasterWebUiUrl : String = ""
private val workerUri = rpcEnv.uriOf(systemName, rpcEnv.address, endpointName)
private var registered = false
private var connected = false
private val workerId = generateWorkerId()
private val sparkHome =
if (testing) {
assert(sys.props.contains("spark.test.home"), "spark.test.home is not set!")
new File(sys.props("spark.test.home"))
} else {
new File(sys.env.get("SPARK_HOME").getOrElse("."))
}
var workDir: File = null
val finishedExecutors = new LinkedHashMap[String, ExecutorRunner]
val drivers = new HashMap[String, DriverRunner]
val executors = new HashMap[String, ExecutorRunner]
val finishedDrivers = new LinkedHashMap[String, DriverRunner]
val appDirectories = new HashMap[String, Seq[String]]
val finishedApps = new HashSet[String]
val retainedExecutors = conf.getInt("spark.worker.ui.retainedExecutors",
WorkerWebUI.DEFAULT_RETAINED_EXECUTORS)
val retainedDrivers = conf.getInt("spark.worker.ui.retainedDrivers",
WorkerWebUI.DEFAULT_RETAINED_DRIVERS)
// The shuffle service is not actually started unless configured.
private val shuffleService = new ExternalShuffleService(conf, securityMgr)
private val publicAddress = {
val envVar = conf.getenv("SPARK_PUBLIC_DNS")
if (envVar != null) envVar else host
}
private var webUi: WorkerWebUI = null
private var connectionAttemptCount = 0
private val metricsSystem = MetricsSystem.createMetricsSystem("worker", conf, securityMgr)
private val workerSource = new WorkerSource(this)
private var registerMasterFutures: Array[JFuture[_]] = null
private var registrationRetryTimer: Option[JScheduledFuture[_]] = None
// 用来和Master注册使用的线程池,默认线程的最大个数为Worker的个数
// A thread pool for registering with masters. Because registering with a master is a blocking
// action, this thread pool must be able to create "masterRpcAddresses.size" threads at the same
// time so that we can register with all masters.
private val registerMasterThreadPool = ThreadUtils.newDaemonCachedThreadPool(
"worker-register-master-threadpool",
masterRpcAddresses.size // Make sure we can register with all masters at the same time
)
var coresUsed = 0
var memoryUsed = 0
onStart()方法:
override def onStart() {
assert(!registered)
logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(
host, port, cores, Utils.megabytesToString(memory)))
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
logInfo("Spark home: " + sparkHome)
// 创建Work的目录
createWorkDir()
// 开启 external shuffle service
shuffleService.startIfEnabled()
webUi = new WorkerWebUI(this, workDir, webUiPort)
webUi.bind()
// 向Master注册自己
registerWithMaster()
// metrics系统
metricsSystem.registerSource(workerSource)
metricsSystem.start()
// Attach the worker metrics servlet handler to the web ui after the metrics system is started.
metricsSystem.getServletHandlers.foreach(webUi.attachHandler)
}
本文简单介绍了Spark的几种部署模式,并详细的分析了start-all.sh所执行源码(Master的启动和注册、Worker的启动和向Master的注册)的具体流程,当然Master的schedule方法并没有详细说明,我们会单独用一篇文章进行详细的分析。
本文参考和拓展阅读:
Spark-1.6.3源码
Spark-2.1.0源码
本文为原创,欢迎转载,转载请注明出处、作者,谢谢!